
Transformer 学习笔记
1. Introduction
Transformer 是2017年论文 “Attention Is All You Need” 中提出的 seq2seq 模型,该模型最大的贡献是舍弃了过去 seq2seq 模型中大量使用的RNN(包括LSTM和GRU),而是完全基于 attention 机制,使 Decoder 不用逐词预测,实现了模型的并行化,大大提高了训练速度。因为不是在 Decoder 中对 Encoder 的输出做 attention ,而是分别在 Encoder 和 Decoder 各自做 attention ,因此也称为 self-attention 。Transformer 的网络结构如下图。
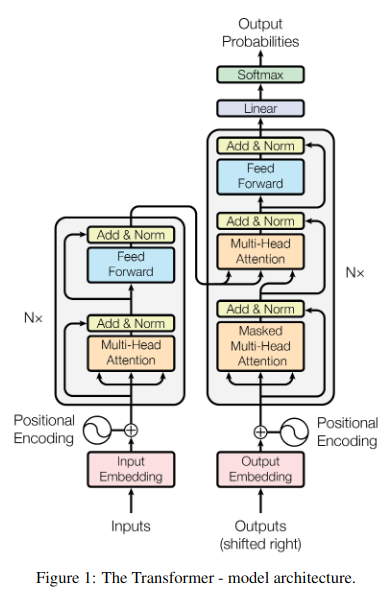
2. Encoder & Decoder
Transformer 模型主要分为两部分, Encoder 和 Decoder 。
Encoder:Encoder 由6个相同的 EncoderLayer 层构成,每个层有2个子层,第一个是多头自注意力 (multi-head self-attention) 机制,第二个是简单的全连接前馈网络。每个子层的输出都使用了残差连接,然后进行层归一化,因此每个子层的输出为 LayerNorm(x + Sublayer(x)),为了便于残差连接所有子层和 Word_Embedding 输出维度都设置为 d_model = 512 。
Decoder:Decoder 也由6个相同的 DecoderLayer 层构成,每个层有3个子层,除了2个和 Encoder 相同的子层外,还增加了一个对 Encoder 的输出做多头注意力 (multi-head attention) 的子层。和 Encoder 类似,也对每个子层的输出使用残差连接并做层归一化。并且对 Decoder 的自注意力进行了 mask 修正,以确保当前位置 i 的预测只依赖于 i - 1 之前的输入。
下面按从输入到输出的顺序解释模型的各组成部分。
3. Positional Encoding
因为 Transformer 里没有使用 RNN ,不是逐词预测,所以直接输入序列的话就缺少时序信息,即对输入词的前后位置不敏感,因此我们需要在输入到 Encoder 和 Decoder 前给输入序列加上时序信息,即每个词的位置信息。
方法是在输入的 Word_Embedding 中加入位置编码 (Positional Encoding) ,位置编码的 size 与 Embedding size 相同,均为 d_model ,因此两者可以相加。论文中使用了不同频率的 sin 和 cos 函数计算位置编码:
\[\begin{array}{*{20}{l}}
{PE \left( pos,2i \left) =sin \left( pos/10000\mathop{{}}\nolimits^{{2i/d\mathop{{}}\nolimits_{{model}}}} \right) \right. \right. }\\
{PE \left( pos,2i+1 \left) =cos \left( pos/10000\mathop{{}}\nolimits^{{2i/d\mathop{{}}\nolimits_{{model}}}} \right) \right. \right. }
\end{array}\]
上式中 pos 指的是一句话中某个字的位置,取值范围是 [0, max_output_len),i 指的是字嵌入向量的维度序号,取值范围是 [0, d_model/2)。
上面有 sin 和 cos 一组公式,也就是对应着 d_model 维度的一组奇数和偶数序号的维度,例如 0,1 一组, 2,3 一组,分别用上面的 sin 和 cos 函数做处理,从而产生不同的周期性变化。而位置编码在 d_model 维度上随着维度序号增大,周期变化会越来越慢,最终产生一种包含位置信息的纹理,就像论文中讲的,位置编码函数的周期从 2π 到 10000∗2π 变化,而每一个位置在 d_model 维度上都会得到不同周期的 sin 和 cos 函数的取值组合,从而产生唯一的纹理位置信息,最终使得模型学到词位置之间的依赖关系和序列的时序信息。位置编码的可视化表示如下:
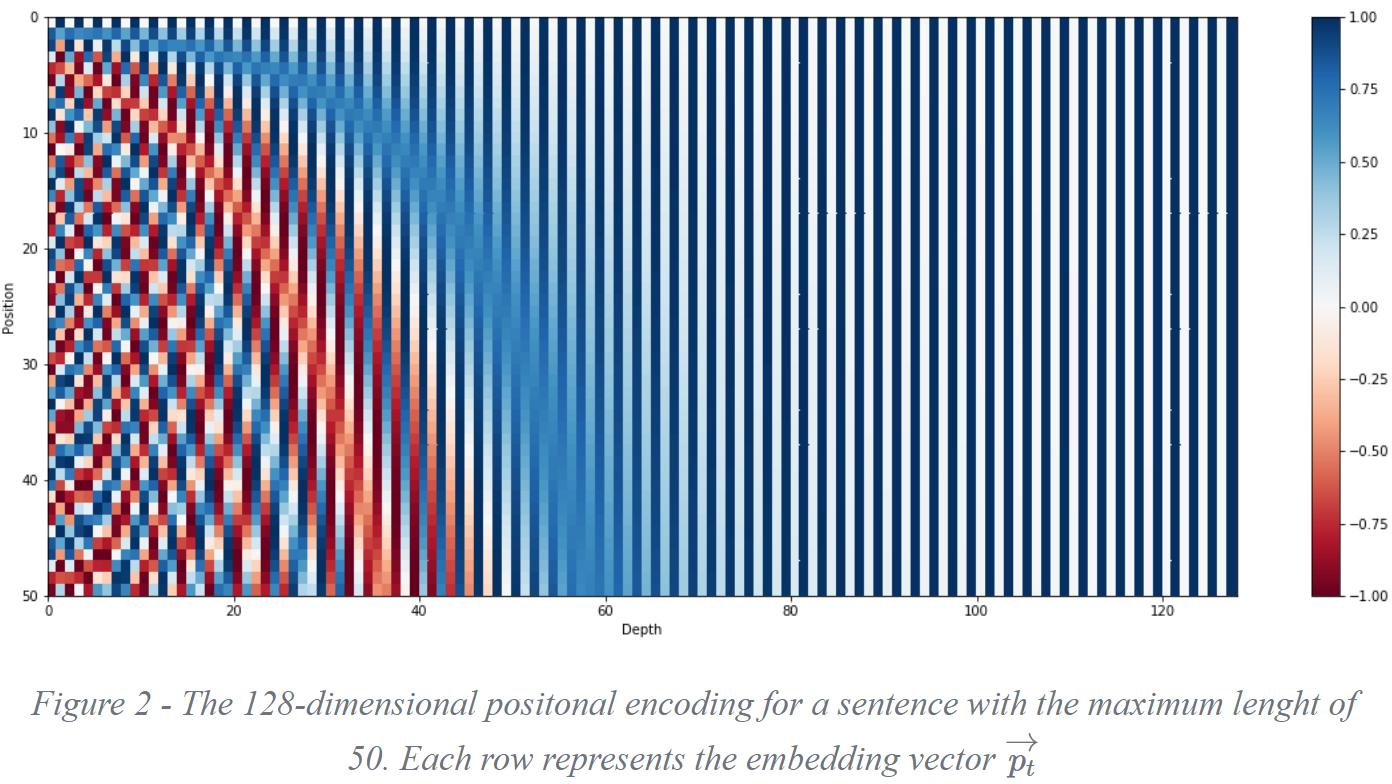
4. Multi-Head Attention
4.1 Self-Attention
在对输入序列加入位置编码后得到 Encoder 的输入 x ,将 x 的第 t 个词的表示向量记作 xt 。然后定义3个不同的矩阵 WQ, WK, WV 分别对所有词的表示向量做线性变换,这样 xt 又可以得到3个新的向量:查询向量 qt ,键向量 kt ,值向量 vt 。用 q1 和每个键向量 k 做计算来获得第 t 个词的注意力权重,方法如图(来自李宏毅老师深度学习课程):
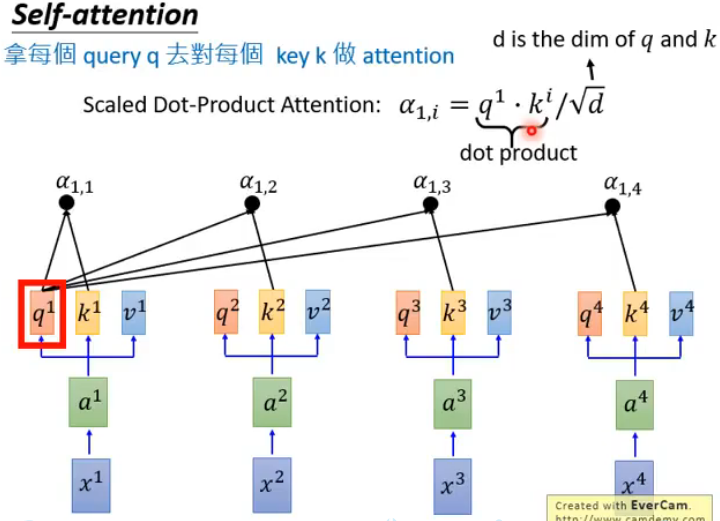
对结果做 softmax 得到注意力权重,然后与每个值向量 v 加权求和得到第一个词的上下文向量 b1 ,如图:
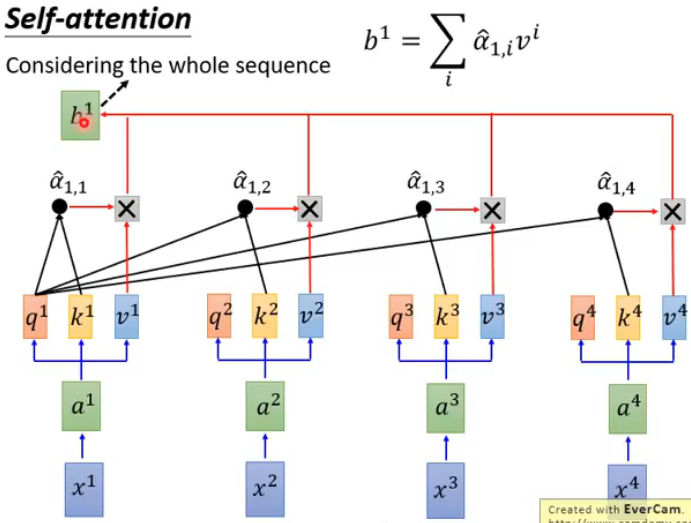
用同样的方法获得其他词的上下文向量,即可得到 attention 的所有输出,如图:
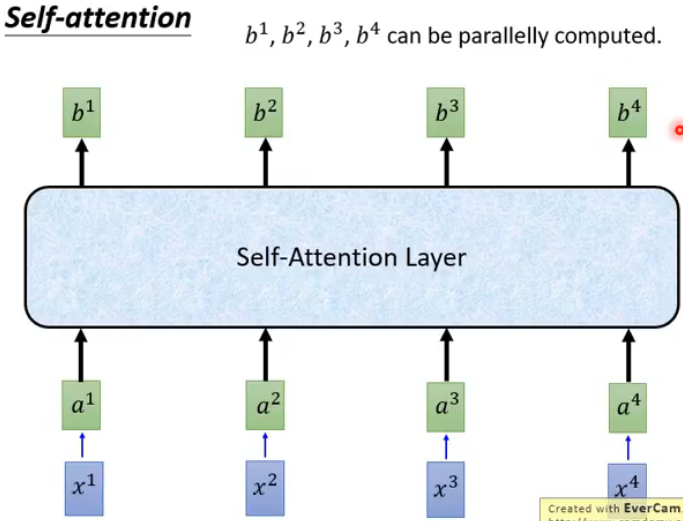
可以通过矩阵运算加速:

4.2 Multi-Head
即定义多组矩阵 (WQ0, WK0, WV0), (WQ1, WK1, WV1), ... 对于每一组变换矩阵,都能经过上述的计算过程得到一个输出矩阵 O ,将这些输出矩阵连接起来并通过一个线性全连接层就得到 Multi-Head Attention 的输出。如图:
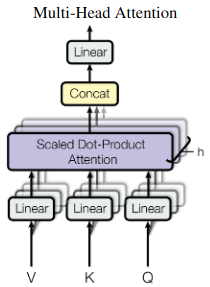
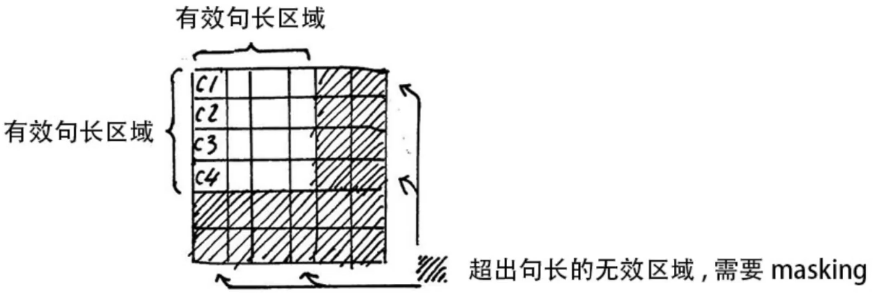
4.3 Padding Mask
训练中一个 batch 是由多个不等长的句子组成的,我们需要按照这个 batch 中最大的句长对剩余的句子进行补齐,一般用 0 进行填充,这个过程叫做 padding ,这样在进行 softmax 就会产生问题。因为 e^0=1 ,所以做 softmax 时 padding 的部分也参与了运算,可能会影响预测的结果,因此要对 padding 的部分做一个 mask 操作,让这些无效的区域不参与运算,一般是在 softmax 前给无效区域加一个很大的负数偏置,即
\[{Z\mathop{{}}\nolimits_{{illegal}}=Z\mathop{{}}\nolimits_{{illegal}}+bias, \left( bias \to - \infty \right) }\]
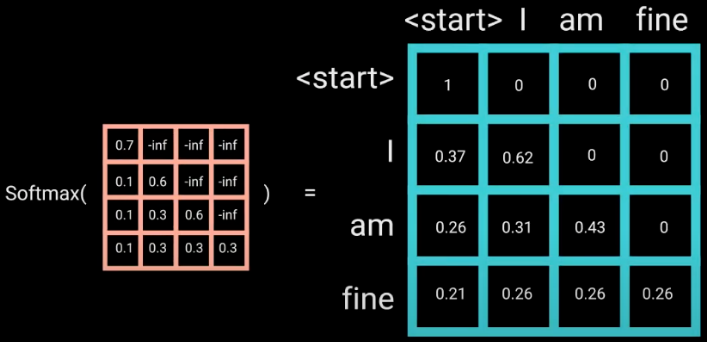
4.4 Masked Self-Attention
传统 seq2seq 的 Decoder 使用 RNN 模型,逐词预测输出序列,这样在预测当前时刻的词时, Decoder 只看到以前时刻的 dec_inputs 。而 Transformer 舍弃了 RNN ,一次性读取整个 dec_inputs 序列的所有词,这意味着预测当前词时 Decoder 就看到了整个 dec_inputs 序列,这显然是不符合实际的,因此作者提出了 Masked Self-Attention 用于 Decoder 。即在计算 Decoder 端的 self-attention 权重和做 softmax 之间,除了做 Padding Mask 操作外,还要做一个 Subsequence Mask ,方法是生成一个下三角全 0,上三角全为负无穷的矩阵,然后将其与 self-attention 权重相加。可以想象,实际上的 mask 是两个 mask 的逻辑或,即只要在某个位置其中一个 mask 的值为负无穷,这个位置就要被 masking ,即 softmax 后这个位置为 0 。

4.5 Encoder-Decoder Attention
这一部分是 Decoder 中的第二个 attention ,步骤与 Encoder 中的 self-attention 一模一样,唯一的不同是只有 Q 是由 Decoder 端 Masked self-attention 的输出经过矩阵变换得到,而 K 和 V 是由 Encoder 的输出经过矩阵变换得到。
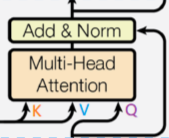
5. Residual Connection & Layer Normalization
在得到 attention 的输出后,将其与输入序列的 embedding 相加做残差连接,即
\[{X\mathop{{}}\nolimits_{{embedding}}+Attention \left( Q,K,V \right) }\]
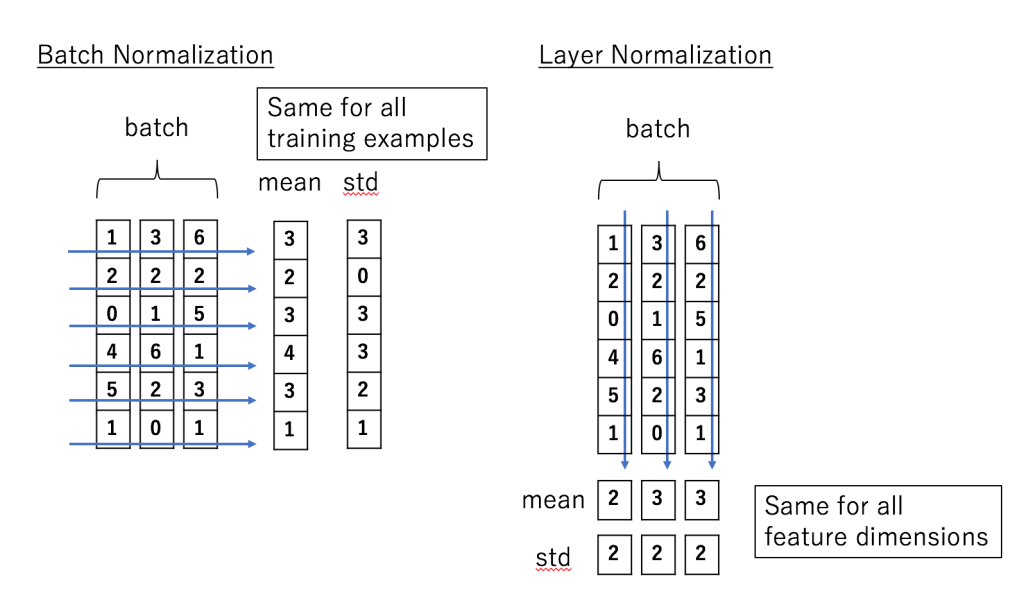
然后做层归一化,层归一化的作用是把神经网络中隐藏层归一为标准正态分布,也就是 i.i.d 独立同分布,以起到加快训练速度,加速收敛的作用。
\[{LayerNorm \left( x \left) =\frac{{x\mathop{{}}\nolimits_{{ij}}- \mu \mathop{{}}\nolimits_{{j}}}}{{\sqrt{{ \sigma \mathop{{}}\nolimits^{{2}}+ \varepsilon }}}}\right. \right. }\]
其中, μ 为均值, σ2 为方差, ε 是为了防止分母为零。
批归一化与层归一化的区别:
经过残差连接和层归一化后输出到一个全连接层(Feed Forward),全连接层后也有一次残差连接和层归一化,之后再输出到下一个 EncoderLayer 。Feed Forward 层的结构为:
\[{x\mathop{{}}\nolimits_{{hidden\text{ }}}=Linear \left( ReLU \left( Linear \left( x\mathop{{}}\nolimits_{{attention}} \left) \left) \right) \right. \right. \right. \right. }\]
6. The Whole Transformer
整个 Transformer 网络就是由以上各模块构成。其中:
Encoder 由 (1) Word Embedding & Positional Encoding, (2) Multi-Head Self_Attention, (3) Residual Connection & Layer Normalization, (4) Feed Forward, (5) Residual Connection & Layer Normalization, (6) repeat (2)-(5) × 6 构成。
Decoder 由 (1) Word Embedding & Positional Encoding, (2) Masked Multi-Head Self_Attention, (3) Residual Connection & Layer Normalization, (4) Multi-Head Encoder-Decoder Attention, (5) Residual Connection & Layer Normalization, (6) Feed Forward, (7) Residual Connection & Layer Normalization, (8) repeat (2)-(7) × 6, (9) Linear & Softmax 构成。
以上就是 Transformer 的内部结构和整体流程,除此之外,论文中还提到一些训练时的 tricks ,比如模型中 Dropout 的使用, optimizer 学习率的自定义方式等,这些 tricks 可在具体任务中选择性地使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号