NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE (Seq2Seq with Attention)论文阅读
1. Introduction
这篇论文首次提出了NLP中的Attention机制,该机制被提出的目的是为了解决Encoder-Decoder神经机器翻译模型中长句子的翻译效果差的问题。作者希望通过Attention机制将输入和输出句子进行“对齐”,但是不同语言的语法结构相差很大,并没有很好的严格对齐方法,因此这里的对齐实际上是“软”对齐。
作者认为的瓶颈主要在于中间转换的向量维数是固定的。因此,作者提出了一种新的解码方式,其解码的依赖不仅仅包括该向量,允许模型自动(软)搜索与预测目标词相关的源句子部分,而不必将这些部分严格划分,即Attention机制。作者还通过定性分析说明这种机制是合理的、符合人的直觉的。
之前的Encoder-Decoder模型在对长句子的翻译中效果较差,尤其是遇到比训练语料库中的句子更长的句子。因此作者提出了一种(软)对齐方法,每次模型在翻译中生成单词时,它都会(自动)搜索源句子中最相关信息集中的一组位置,然后,该模型基于与这些源位置相关联的上下文向量和所有先前生成的目标词预测目标词。与基本的Encoder-Decoder模型相比,此方法最重要的区别在于,它不会尝试将整个输入句子编码为单个固定长度的向量,而是将输入句子encoder为一个向量序列,并在decoder翻译时自适应地从向量序列中选择其子集。这样的模型可以更好地处理长句子,句子越长,改进越明显。这是符合人的直觉的,因为我们人在翻译句子时,不会一直关注整个句子,而是在翻译某个片段时,重点关注该片段及其距离较近的上下文内容。
2. Model
2.1 Encoder
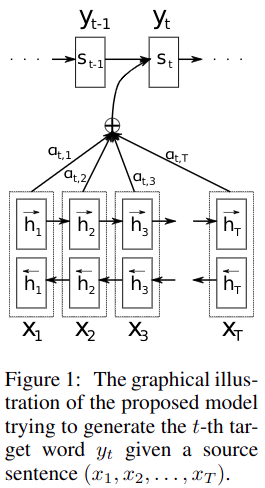
基本的RNN Encoder是按顺序输入句子中的单词序列,将源句子Encoder成一个固定维数的向量,这样RNN中间的隐藏层状态只包含了当前词及之前的信息,而这篇论文使用了双向RNN (BiRNN),那么隐藏层状态就包含了当前词及之前之后的所有信息,相当于每一个隐藏层都看了整个句子。一个BiRNN包含一个前向(forward)和一个反向(backward)RNN,前向RNN按顺序读取单词序列 (x1,...,xT),并计算得到前向隐藏状态序列${ \left( \overrightarrow {h}\mathop{{}}\nolimits_{{1}},..., \overrightarrow {h}\mathop{{}}\nolimits_{{T}} \right) }$;反向RNN按逆序读取单词序列 (xT,...,x1),并计算得到反向隐藏状态序列${ \left( \overleftarrow {h}\mathop{{}}\nolimits_{{1}},..., \overleftarrow {h}\mathop{{}}\nolimits_{{T}} \right) }$。最后对于词 xj ,表示为两个RNN的相应隐藏状态的连接,即${h\mathop{{}}\nolimits_{{j}}={{ \left[ { \overrightarrow {h}{\mathop{{}}\nolimits_{{j}}ᐪ}; \overleftarrow {h}{\mathop{{}}\nolimits_{{j}}ᐪ}} \right] }ᐪ}}$,这样 hj 压缩了前向和反向的表示,并且更加关注于词 xj 周围的词,使得 RNN 能更好地表达当前的输入,这个隐藏状态序列将被Decoder和后面的对齐模型用来计算上下文向量。
2.2 Decoder
定义估计目标词时的条件概率为:
${{p \left( y\mathop{{}}\nolimits_{{i}}{ \left| {y\mathop{{}}\nolimits_{{1}},...,y\mathop{{}}\nolimits_{{i-1}},x}\right. } \right) }=g \left( y\mathop{{}}\nolimits_{{i-1}},s\mathop{{}}\nolimits_{{i}},c\mathop{{}}\nolimits_{{i}} \right) }$
g 一般是多层非线性神经网络,si 是RNN在 i 时刻的隐藏状态,计算为${s\mathop{{}}\nolimits_{{i}}=f \left( s\mathop{{}}\nolimits_{{i-1}},y\mathop{{}}\nolimits_{{i-1}},c\mathop{{}}\nolimits_{{i}} \right) }$。注意,与基本的Encoder-Decoder不同,这里的概率计算依赖于每个目标词的 yi 的不同上下文向量 ci 。ci 依赖于Encoder中计算出的隐藏状态序列${ \left( h\mathop{{}}\nolimits_{{1}},...,h\mathop{{}}\nolimits_{{T}} \right) }$,其中每个 hj 都包含了整个输入序列的信息,并且重点关注于输入序列的第 j 个词 xj 周围的部分。下面介绍实现的方法。
上下文向量 ci 可以由各隐藏状态 hj 加权求和得到:
${c\mathop{{}}\nolimits_{{i}}={\mathop{ \sum }\limits_{{j=1}}^{{T}}{ \alpha \mathop{{}}\nolimits_{{ij}}h\mathop{{}}\nolimits_{{j}}}}}$
每个 hj 的权重计算为:
${ \alpha \mathop{{}}\nolimits_{{ij}}=\frac{{exp \left( e\mathop{{}}\nolimits_{{ij}} \right) }}{{{\mathop{ \sum }\nolimits_{{T}}^{{k=1}}{exp \left( e\mathop{{}}\nolimits_{{ik}} \right) }}}}}$
其中,${e\mathop{{}}\nolimits_{{ij}}=a \left( s\mathop{{}}\nolimits_{{i-1}},h\mathop{{}}\nolimits_{{j}} \right) }$。这里的 a 可以看作是一个对齐模型,用来计算输入序列第 j 个词和目标序列第 i 个词的匹配程度。至于这个匹配程度的具体计算方法,可以自己设计,比如直接计算余弦相似度、可以是一个线性变换矩阵、也可以是一个比较小的神经网络。如果匹配程度的计算中有参数的话,也能够在整个模型中联合训练。
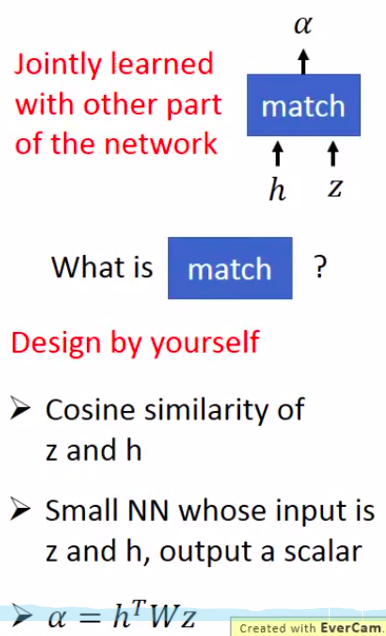
而本文作者则是使用了一个单层的多层感知机,如下图:

不同于传统的对齐模型:源句子每个词明确对齐到目标句子一个或多个词(“硬”对齐),该方法是一种“软”对齐方法,可以融入整个 NMT 模型,通过反向传播求梯度以及更新参数。
将Attention机制用于 NMT 模型中,可以使得Decoder更多地关注于源句子中与估计目标词相关的部分词,从而缓解了Encoder-Decoder中将源句子Encoder成固定维数的向量,对长句子翻译效果差的问题。
3. Experiments
作者仍然对融入Attention机制的Encoedr-Decoder模型 (RNNsearch) 在英语->法语翻译任务中进行了实验,并对比了基本的RNN Encoder-Decoder模型 (RNNenc) ,让这两个模型分别在句子最大长度为 30 和 50 的训练集上训练,在测试集上得到了如下图结果。
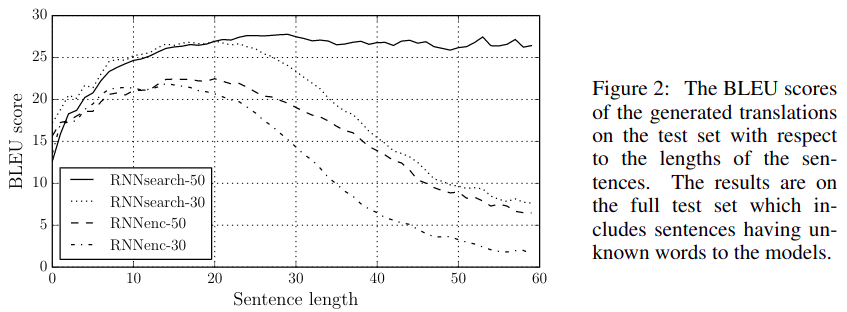
可以看到,融入Attention机制的模型表现明显由于基本模型,尤其是在较长句子上训练的RNNsearch-50模型对于长句子翻译的表现突出,可以说十分稳定,几乎不受长句子影响。
论文中还说明了一些模型实现的细节:
Encoder由正向和反向RNN组成,每个都有1000个隐藏单元,Decoder有1000个隐藏单元,并且均使用具有单个maxout隐藏层的多层网络计算每个目标词的条件概率;
使用了minibatch随机梯度下降(SGD)算法和Adadelta算法来训练模型,每个SGD更新方向使用80个句子的minibatch计算;
使用了beam search方法寻找最优解。
更多的具体实现细节在论文的附录中,此处不做赘述。
4. Model analysis
为了从直观上感受 Attention 机制下的(软)对齐效果,作者随机抽取了测试集中的几个句子,将他们的注意力权重 αij 采用热图的方式可视化了出来。
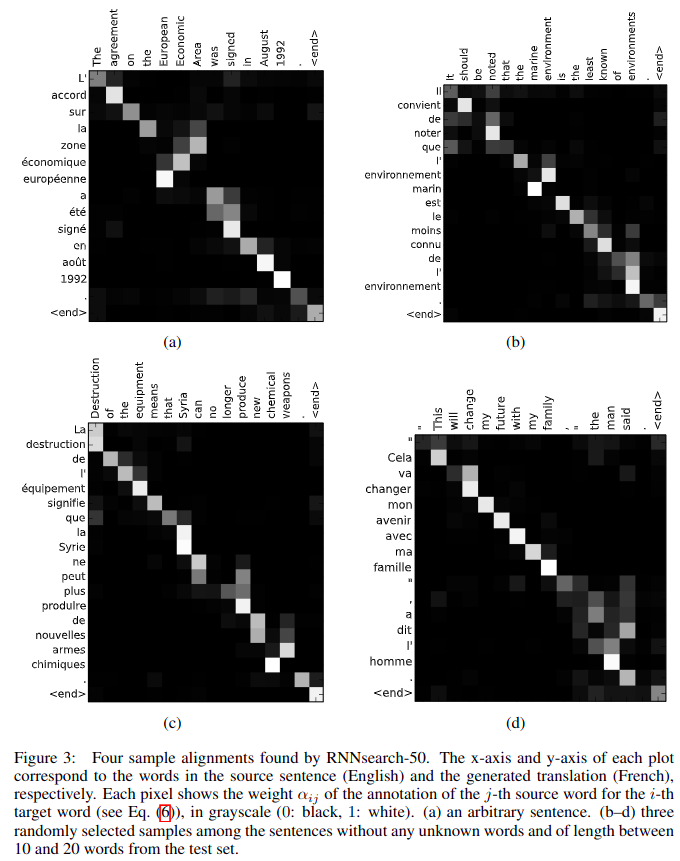
对齐模型结果如上图所示,所选的例子是随机从句长 10-20 且不包含 UNK 的结果中采样得到的。横轴对应源句子(English),纵轴对应目标句子(French),对齐权重由灰度值表示,越亮表示权重越大。通过上图可以清晰地看到在生成目标词时,源句中的哪些词被认为更重要。不难看出,输入与输出句子的词之间的关系在很大程度上是单调的,即权重矩阵近似于单位矩阵,而对于一些输入与输出句子由于语法结构不同导致的一些不对称的语法现象,Attention机制能够自动跳过一些单词,调节语法顺序,使得输入输出得到正确的软对齐。“软”对齐的另一个好处是,它可以自然地处理不同长度的源句子和目标句子,而无需以一种反直觉的方式将某些单词映射到NULL。
5. Conclusion
Attention机制的提出,大大提高了神经机器翻译模型的性能,使得传统的统计机器翻译方法几乎没有了优势,也对NLP中的其他研究领域产生了很大的启发。剩下的挑战就是处理生词和稀有词的问题了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号