

实验5 文件应用编程
task3
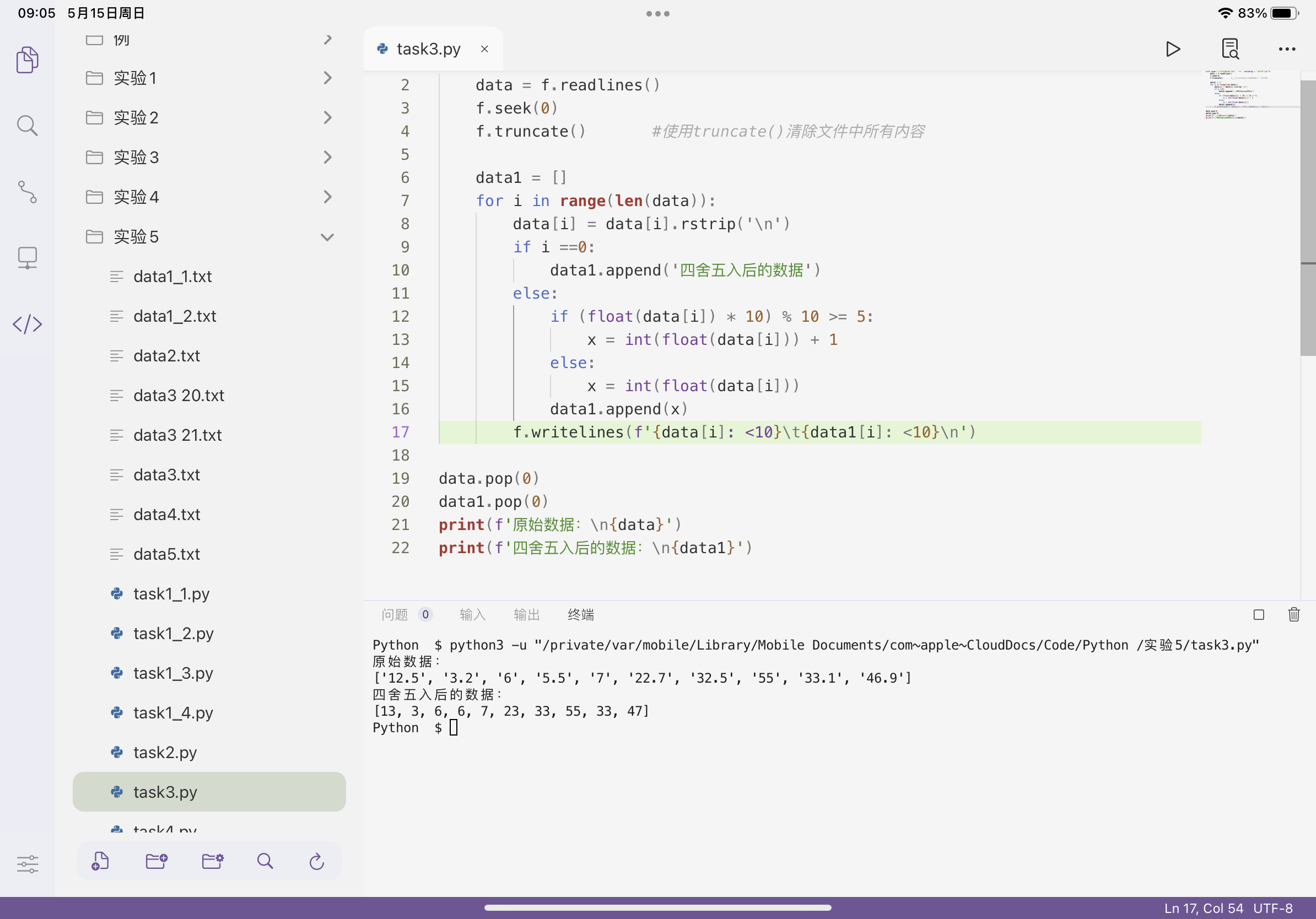
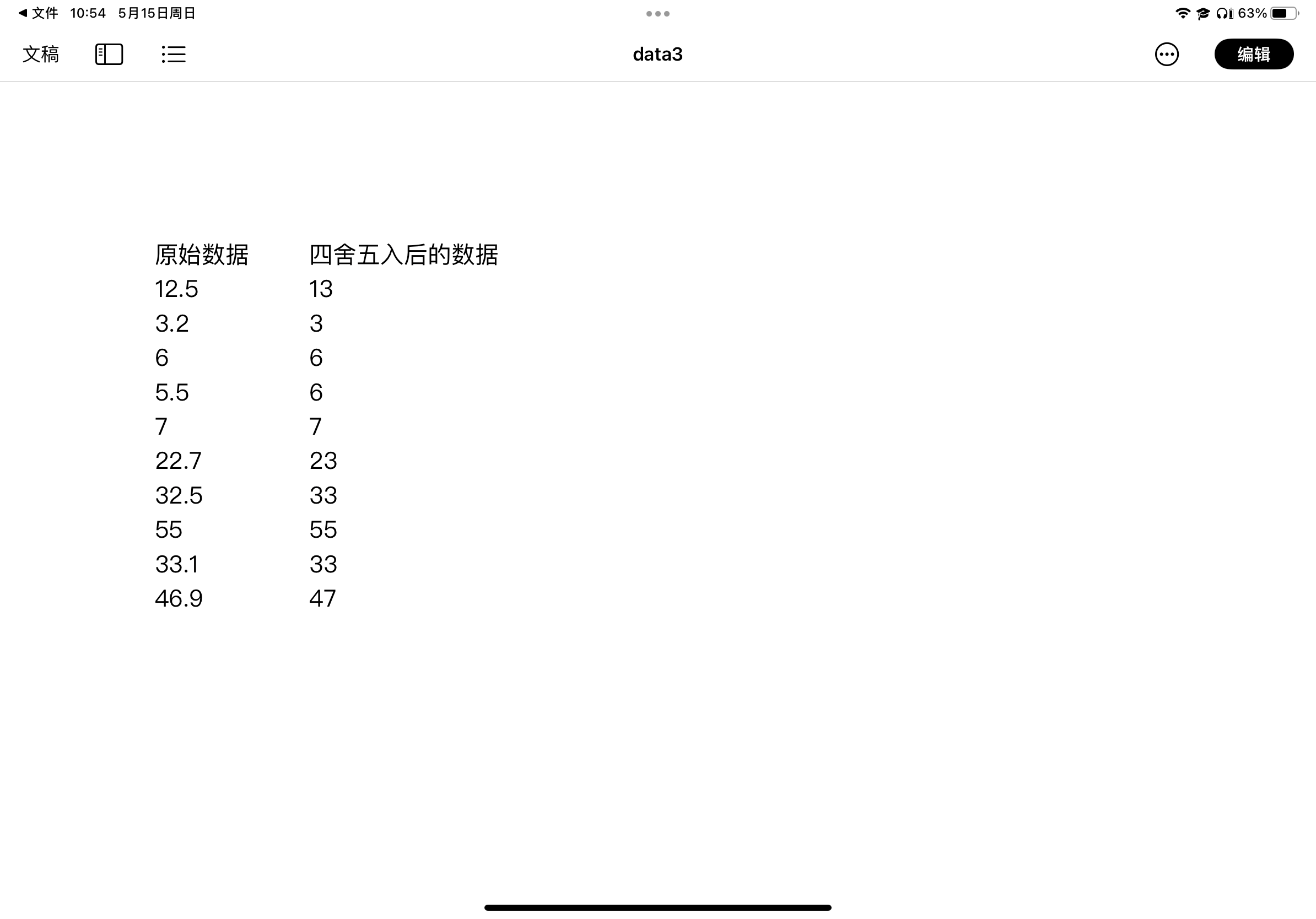
1 with open('实验5/data3.txt', 'r+', encoding = 'utf-8')as f: 2 data = f.readlines() 3 f.seek(0) 4 f.truncate() #使用truncate()清除文件中所有内容 5 6 data1 = [] 7 for i in range(len(data)): 8 data[i] = data[i].rstrip('\n') 9 if i ==0: 10 data1.append('四舍五入后的数据') 11 else: 12 if (float(data[i]) * 10) % 10 >= 5: 13 x = int(float(data[i])) + 1 14 else: 15 x = int(float(data[i])) 16 data1.append(x) 17 f.writelines(f'{data[i]: <10}\t{data1[i]: <10}\n') 18 19 data.pop(0) 20 data1.pop(0) 21 print(f'原始数据:\n{data}') 22 print(f'四舍五入后的数据:\n{data1}')
task4
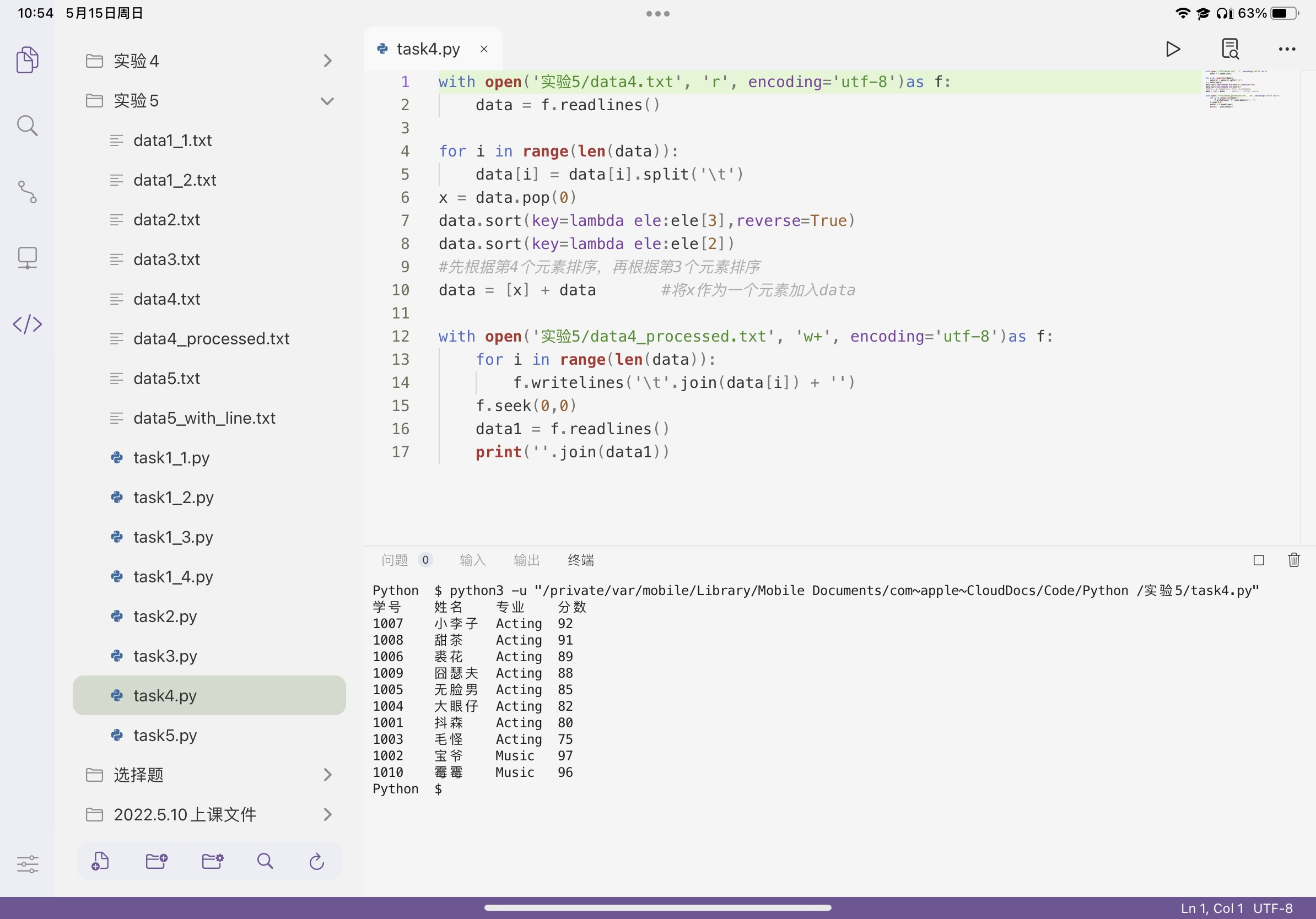
1 with open('实验5/data4.txt', 'r', encoding='utf-8')as f: 2 data = f.readlines() 3 4 for i in range(len(data)): 5 data[i] = data[i].split('\t') 6 x = data.pop(0) 7 data.sort(key=lambda ele:ele[3],reverse=True) 8 data.sort(key=lambda ele:ele[2]) 9 #先根据第4个元素排序,再根据第3个元素排序 10 data = [x] + data #将x作为一个元素加入data 11 12 with open('实验5/data4_processed.txt', 'w+', encoding='utf-8')as f: 13 for i in range(len(data)): 14 f.writelines('\t'.join(data[i]) + '') 15 f.seek(0,0) 16 data1 = f.readlines() 17 print(''.join(data1))

task5
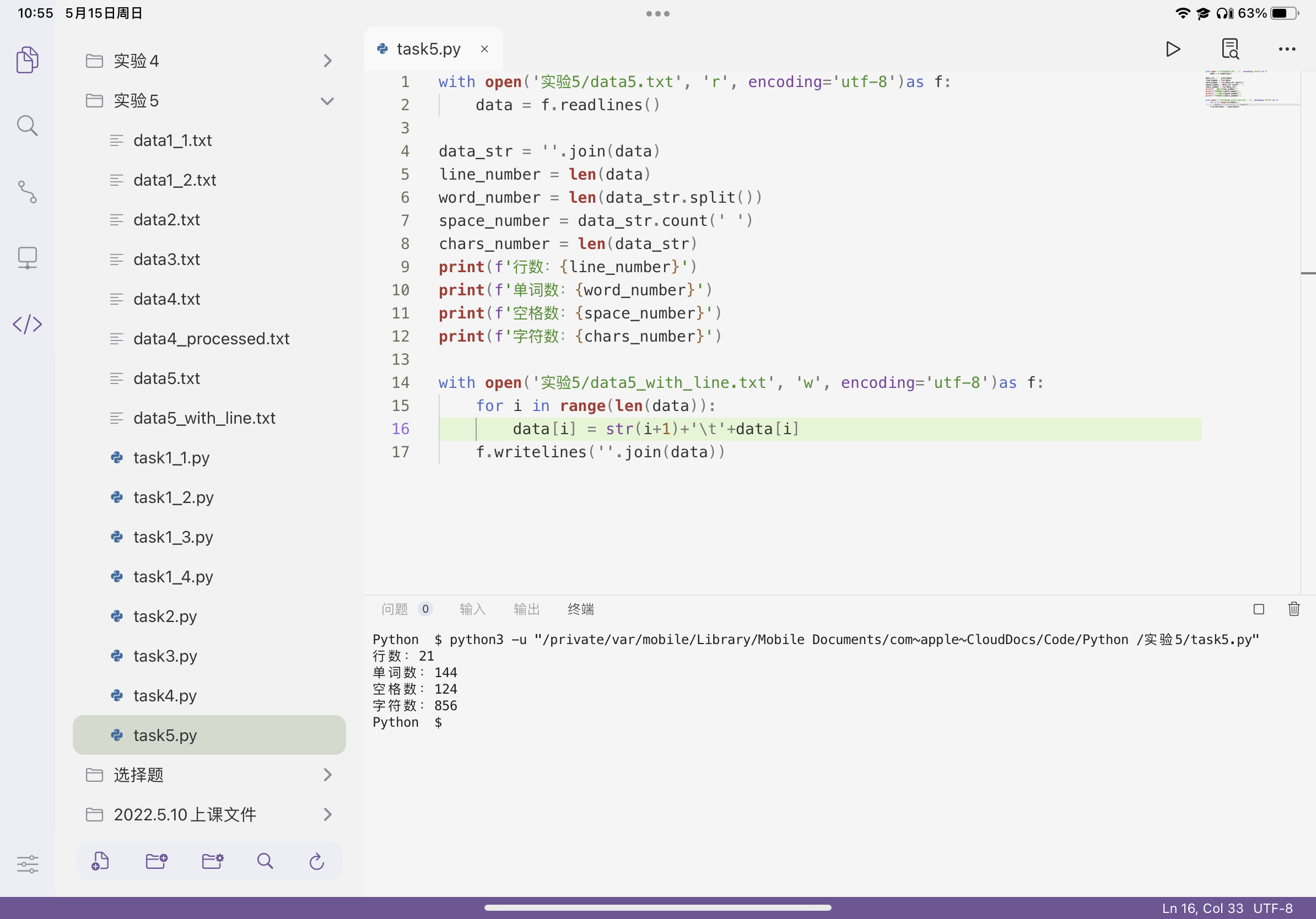
1 with open('实验5/data5.txt', 'r', encoding='utf-8')as f: 2 data = f.readlines() 3 4 data_str = ''.join(data) 5 line_number = len(data) 6 word_number = len(data_str.split()) 7 space_number = data_str.count(' ') 8 chars_number = len(data_str) 9 print(f'行数:{line_number}') 10 print(f'单词数:{word_number}') 11 print(f'空格数:{space_number}') 12 print(f'字符数:{chars_number}') 13 14 with open('实验5/data5_with_line.txt', 'w', encoding='utf-8')as f: 15 for i in range(len(data)): 16 data[i] = str(i+1)+'\t'+data[i] 17 f.writelines(''.join(data))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号