STL常用容器用法
STL容器就是将运用最广泛的一些数据结构实现出来
常用的数据结构:数组, 链表,树, 栈, 队列, 集合, 映射表 等
这些容器分为序列式容器和关联式容器两种:
| 序列式容器 | 强调值的排序,序列式容器中的每个元素均有固定的位置 |
| 关联式容器 | 二叉树结构,各元素之间没有严格的物理上的顺序关系 |
String容器
Stirng 本质上是C++风格的字符串,是一个类。
string和char * 区别:
- char * 是一个指针
- string是一个类,类内部封装了char*,管理这个字符串,是一个char*型的容器。
构造函数原型:
string();//创建一个空的字符串 例如: string str; 无参构造
string(const char* s);//使用字符串s初始化 有参构造string(const string& str);//使用一个string对象初始化另一个string对象 拷贝构造string(int n, char c);//使用n个字符c初始化 重载 有参构造
赋值的函数原型:
string& operator=(const char* s);//char*类型字符串 赋值给当前的字符串string& operator=(const string &s);//把字符串s赋给当前的字符串string& operator=(char c);//字符赋值给当前的字符串string& assign(const char *s);//把字符串s赋给当前的字符串string& assign(const char *s, int n);//把字符串s的前n个字符赋给当前的字符串string& assign(const string &s);//把字符串s赋给当前字符串string& assign(int n, char c);//用n个字符c赋给当前字符串
string字符串拼接函数原型:
string& operator+=(const char* str);//重载+=操作符string& operator+=(const char c);//重载+=操作符string& operator+=(const string& str);//重载+=操作符string& append(const char *s);//把字符串s连接到当前字符串结尾string& append(const char *s, int n);//把字符串s的前n个字符连接到当前字符串结尾string& append(const string &s);//同operator+=(const string& str)string& append(const string &s, int pos, int n);//字符串s中从pos开始的n个字符连接到字符串结尾
string str1 = "aaaaa1111";
string str2(10, 'b');
str2.append(str1,4,3);
//bbbbbbbbbba11
string查找替换函数原型:
int find(const string& str, int pos = 0) const;//查找str第一次出现位置,从pos开始查找int find(const char* s, int pos = 0) const;//查找s第一次出现位置,从pos开始查找int find(const char* s, int pos, int n) const;//从pos位置查找 s的前n个字符 第一次位置int find(const char c, int pos = 0) const;//查找字符c第一次出现位置int rfind(const string& str, int pos = npos) const;//查找str最后一次位置,从pos开始查找int rfind(const char* s, int pos = npos) const;//查找s最后一次出现位置,从pos开始查找int rfind(const char* s, int pos, int n) const;//从pos查找s的前n个字符最后一次位置int rfind(const char c, int pos = 0) const;//查找字符c最后一次出现位置string& replace(int pos, int n, const string& str);//替换从pos开始n个字符为字符串strstring& replace(int pos, int n,const char* s);//替换从pos开始的n个字符为字符串s
string str1= "abcdefghijkabcdefghijk";
cout << str1.find("de") << endl;//
cout << str1.find("df") << endl;
cout << str1.find("efg",1,2) << endl;
//rfind形参与find一致 从右往左寻找字符串
cout << str1.rfind("de") << endl;
cout << str1.replace(3, 5, "111") << endl;
//3
//4294967295
//4
//14
//abc111ijkabcdefghijk
调试的时候出现了问题 即直接输出find()没有找到结果时 返回4294967295,明显是因为find返回值为无符号型整数
查看相关实现string.find在未找到时会返回string::npos
定义为
static const size_t npos = -1;
size_t类型是无符号整数类型
因此调用时需要注意
int pos =find("df");//进行转化为带符号型
string字符串比较函数原型:
int compare(const string &s) const;//与字符串s比较int compare(const char *s) const;//与字符串s比较
比较方式:
- 字符串比较是按字符的ASCII码进行对比
= 返回 0
> 返回 1
< 返回 -1
字符函数原型:
char& operator[](int n);//通过[]方式取字符char& at(int n);//通过at方法获取字符
string插入和删除函数原型:
string& insert(int pos, const char* s);//插入字符串string& insert(int pos, const string& str);//插入字符串string& insert(int pos, int n, char c);//在指定位置插入n个字符cstring& erase(int pos, int n = npos);//删除从Pos开始的n个字符
string子串函数原型:
string substr(int pos = 0, int n = npos) const;//返回由pos开始的n个字符组成的字符串
vector容器
- vector数据结构和数组非常相似,也称为单端数组
- vector与普通数组不同之处在于数组是静态空间,而vector可以动态扩展
- 动态扩展并不是在原空间之后续接新空间,而是找更大的内存空间,然后将原数据拷贝新空间,释放原空间
- vector容器的迭代器是支持随机访问的迭代器
** vector创建函数原型:**
vector<T> v;//采用模板实现类实现,默认构造函数vector(v.begin(), v.end());//将v[begin(), end())区间中的元素拷贝给本身。vector(n, elem);//构造函数将n个elem拷贝给本身。vector(const vector &vec);//拷贝构造函数。
vector赋值函数原型:
vector& operator=(const vector &vec);//重载等号操作符assign(beg, end);//将[beg, end)区间中的数据拷贝赋值给本身。(传入迭代器)assign(n, elem);//将n个elem拷贝赋值给本身。
vector容量大小操作 函数原型:
-
empty();//判断容器是否为空 -
capacity();//容器的容量 -
size();//返回容器中元素的个数 -
resize(int num);//重新指定容器的长度为num,若容器变长,则以默认值填充新位置。 //如果容器变短,则末尾超出容器长度的元素被删除。
//如果容器变长,默认填充0,可重载替换 -
resize(int num, elem);//重新指定容器的长度为num,若容器变长,则以elem值填充新位置。 //如果容器变短,则末尾超出容器长度的元素被删除
插入删除函数原型:
push_back(ele);//尾部插入元素elepop_back();//删除最后一个元素insert(const_iterator pos, ele);//迭代器指向位置pos插入元素eleinsert(const_iterator pos, int count,ele);//迭代器指向位置pos插入count个元素eleerase(const_iterator pos);//删除迭代器指向的元素erase(const_iterator start, const_iterator end);//删除迭代器从start到end之间的元素clear();//删除容器中所有元素
for ( vector<int>::iterator it = p.begin(); it != p.end(); it++)// 迭代器遍历
{
cout << *it << " ";
}
vector<int>::iterator it = p.begin();
//注意 const vector对应const_iterator迭代器
while (it != p.end())
{
cout << *it << " ";
it++;
}
-
iterator,const_iterator作用:遍历容器内的元素,并访问这些元素的值。iterator可以改元素值,但const_iterator不可改。跟C的指针有点像
(容器均可以++iter,而vector还可以iter-n, iter+n,n为一整型,iter1-iter2:结果是difference_type类型,表两元素的距离.) -
const_iterator 对象可以用于const vector 或非 const vector,它自身的值可以改(可以指向其他元素),但不能改写其指向的元素值.
-
const iterator与const_iterator是不一样的:声明一个 const iterator时,必须初始化它。一旦被初始化后,就不能改变它的值,它一旦被初始化后,只能用它来改它指的元素,不能使它指向其他元素。
数据存取函数原型:
at(int idx);//返回索引idx所指的数据operator[];//返回索引idx所指的数据front();//返回容器中第一个数据元素back();//返回容器中最后一个数据元素 注意是最后一个end()-1的指代
容器互换原型:
swap(vec);// 将vec与本身的元素互换
可以通过swap互换容器实现内存压缩
p.swap(vector<int>(p));//匿名变量交换空间后销毁
vector<int>(p).swap(p);
vector预留空间
可以减少vector在动态扩展容量时的扩展次数
reserve(int len);//容器预留len个元素长度,预留位置不初始化,元素不可访问。
vector<int> v;
//预留空间
v.reserve(100000);
//或者初始化就给定大小
vector<int> v(100000);
deque容器
双端数组,可以对头端进行插入删除操作
deque与vector区别:
- vector对于头部的插入删除效率低,数据量越大,效率越低
- deque相对而言,对头部的插入删除速度回比vector快
- vector访问元素时的速度会比deque快,这和两者内部实现有关
deque内部工作原理:
deque内部有个中控器,维护每段缓冲区中的内容,缓冲区中存放真实数据
中控器维护的是每个缓冲区的地址,使得使用deque时像一片连续的内存空间
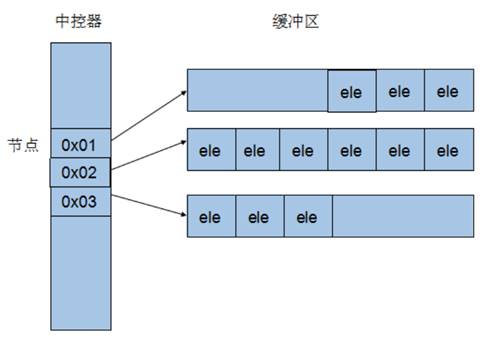
- deque容器的迭代器也是支持随机访问的
deque构造原型: //和vector类似
deque<T>deqT; //默认构造形式deque(beg, end);//构造函数将[beg, end)区间中的元素拷贝给本身。左开右闭deque(n, elem);//构造函数将n个elem拷贝给本身。deque(const deque &deq);//拷贝构造函数
deque赋值函数原型:
-
deque& operator=(const deque &deq);//重载等号操作符 -
assign(beg, end);//将[beg, end)区间中的数据拷贝赋值给本身。 -
assign(n, elem);//将n个elem拷贝赋值给本身。
deque大小操作:
-
deque.empty();//判断容器是否为空 -
deque.size();//返回容器中元素的个数 -
deque.resize(num);//重新指定容器的长度为num,若容器变长,则以默认值填充新位置。 //如果容器变短,则末尾超出容器长度的元素被删除。
-
deque.resize(num, elem);//重新指定容器的长度为num,若容器变长,则以elem值填充新位置。 //如果容器变短,则末尾超出容器长度的元素被删除。
deque无容量的概念
resize()改的是size大小 ,vector的capacity不变
deque插入删除函数原型:
两端插入操作:
push_back(elem);//在容器尾部添加一个数据push_front(elem);//在容器头部插入一个数据pop_back();//删除容器最后一个数据pop_front();//删除容器第一个数据
相比vector多了前插尾插
指定位置操作:
-
insert(pos,elem);//在pos位置插入一个elem元素的拷贝,返回新数据的位置。 -
insert(pos,n,elem);//在pos位置插入n个elem数据,无返回值。 -
insert(pos,beg,end);//在pos位置插入[beg,end)区间的数据,无返回值。 -
clear();//清空容器的所有数据 -
erase(beg,end);//删除[beg,end)区间的数据,返回下一个数据的位置。 -
erase(pos);//删除pos位置的数据,返回下一个数据的位置。
deque存取操作: 与vector一致
at(int idx);//返回索引idx所指的数据operator[];//返回索引idx所指的数据front();//返回容器中第一个数据元素back();//返回容器中最后一个数据元素
排序:
头文件 algorithm
sort(iterator beg, iterator end) //对beg和end区间内元素进行排序
stack容器
stack是一种先进后出**(First In Last Out,FILO)的数据结构,它只有一个出口
栈中只有顶端的元素才可以被外界使用,因此栈不允许有遍历行为
栈中进入数据称为 --- 入栈 push
栈中弹出数据称为 --- 出栈 pop
构造函数:
stack<T> stk;//stack采用模板类实现, stack对象的默认构造形式stack(const stack &stk);//拷贝构造函数
赋值操作:
stack& operator=(const stack &stk);//重载等号操作符
数据存取:
push(elem);//向栈顶添加元素pop();//从栈顶移除第一个元素top();//返回栈顶元素
大小操作:
empty();//判断堆栈是否为空size();//返回栈的大小
queue容器
Queue是一种先进先出(First In First Out,FIFO)的数据结构,它有两个出口
队列容器允许从一端新增元素,从另一端移除元素
队列中只有队头和队尾才可以被外界使用,因此队列不允许有遍历行为
队列中进数据称为 --- 入队 push
队列中出数据称为 --- 出队 pop
常用接口
构造函数:
queue<T> que;//queue采用模板类实现,queue对象的默认构造形式queue(const queue &que);//拷贝构造函数
赋值操作:
queue& operator=(const queue &que);//重载等号操作符
数据存取:
push(elem);//往队尾添加元素pop();//从队头移除第一个元素back();//返回最后一个元素front();//返回第一个元素
大小操作:
empty();//判断堆栈是否为空size();//返回栈的大小
list容器
功能:将数据进行链式存储
链表(list)是一种物理存储单元上非连续的存储结构,数据元素的逻辑顺序是通过链表中的指针链接实现的
链表的组成:链表由一系列结点组成
结点的组成:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域
STL中的链表是一个双向循环链表
由于链表的存储方式并不是连续的内存空间,因此链表list中的迭代器只支持前移和后移,属于双向迭代器
list的优点:
- 采用动态存储分配,不会造成内存浪费和溢出
- 链表执行插入和删除操作十分方便,修改指针即可,不需要移动大量元素
list的缺点:
- 链表灵活,但是空间(指针域) 和 时间(遍历)额外耗费较大
List有一个重要的性质,插入操作和删除操作都不会造成原有list迭代器的失效,这在vector是不成立的。
常用接口
构造函数:
list<T> lst;//list采用采用模板类实现,对象的默认构造形式:list(beg,end);//构造函数将[beg, end)区间中的元素拷贝给本身。list(n,elem);//构造函数将n个elem拷贝给本身。list(const list &lst);//拷贝构造函数。
交换赋值函数:
assign(beg, end);//将[beg, end)区间中的数据拷贝赋值给本身。assign(n, elem);//将n个elem拷贝赋值给本身。list& operator=(const list &lst);//重载等号操作符swap(lst);//将lst与本身的元素互换。
大小操作:
-
size();//返回容器中元素的个数 -
empty();//判断容器是否为空 -
resize(num);//重新指定容器的长度为num,若容器变长,则以默认值填充新位置。 //如果容器变短,则末尾超出容器长度的元素被删除。
-
resize(num, elem);//重新指定容器的长度为num,若容器变长,则以elem值填充新位置。 //如果容器变短,则末尾超出容器长度的元素被删除。 -
size();//返回容器中元素的个数 -
empty();//判断容器是否为空 -
resize(num);//重新指定容器的长度为num,若容器变长,则以默认值填充新位置。
//如果容器变短,则末尾超出容器长度的元素被删除。 -
resize(num, elem);//重新指定容器的长度为num,若容器变长,则以elem值填充新位置。
//如果容器变短,则末尾超出容器长度的元素被删除。
插入删除:
- push_back(elem);//在容器尾部加入一个元素
- pop_back();//删除容器中最后一个元素
- push_front(elem);//在容器开头插入一个元素
- pop_front();//从容器开头移除第一个元素
- insert(pos,elem);//在pos位置插elem元素的拷贝,返回新数据的位置。
- insert(pos,n,elem);//在pos位置插入n个elem数据,无返回值。
- insert(pos,beg,end);//在pos位置插入[beg,end)区间的数据,无返回值。
- clear();//移除容器的所有数据
- erase(beg,end);//删除[beg,end)区间的数据,返回下一个数据的位置。
- erase(pos);//删除pos位置的数据,返回下一个数据的位置。
- remove(elem);//删除容器中所有与elem值匹配的元素。
存取:
front();//返回第一个元素。
list容器中不可以通过[]或者at方式访问数据
返回第一个元素 --- front
返回最后一个元素 --- back
反转和排序
reverse();//反转链表sort();//链表排序
对于自定义数据类型,必须要指定排序规则,否则编译器不知道如何进行排序
高级排序只是在排序规则上再进行一次逻辑规则制定,并不复杂
class Person {
public:
Person(string name, int age , int height) {
m_Name = name;
m_Age = age;
m_Height = height;
}
public:
string m_Name; //姓名
int m_Age; //年龄
int m_Height; //身高
};
bool ComparePerson(Person& p1, Person& p2) {
if (p1.m_Age == p2.m_Age) {
return p1.m_Height > p2.m_Height;
}
else
{
return p1.m_Age < p2.m_Age;
}
}
list<Person> L;
L.sort(ComparePerson); //排序
set/multiset容器
所有元素都会在插入时自动被排序
- set/multiset属于关联式容器,底层结构是用二叉树实现。
set和multiset区别:
- set不允许容器中有重复的元素
- multiset允许容器中有重复的元素
常用接口
构造:
set<T> st;//默认构造函数:set(const set &st);//拷贝构造函数
赋值:
set& operator=(const set &st);//重载等号操作符
set容器插入数据时用insert
set容器插入数据的数据会自动排序
大小交换:
size();//返回容器中元素的数目empty();//判断容器是否为空swap(st);//交换两个集合容器
插入删除:
insert(elem);//在容器中插入元素。clear();//清除所有元素erase(pos);//删除pos迭代器所指的元素,返回下一个元素的迭代器。erase(beg, end);//删除区间[beg,end)的所有元素 ,返回下一个元素的迭代器。erase(elem);//删除容器中值为elem的元素。
查找统计:
find(key);//查找key是否存在,若存在,返回该键的元素的迭代器;若不存在,返回set.end();count(key);//统计key的元素个数
查找 --- find (返回的是迭代器)
统计 --- count (对于set,结果为0或者1)
set和multiset区别:
- set不可以插入重复数据,而multiset可以
- set插入数据的同时会返回插入结果,表示插入是否成功
- multiset不会检测数据,因此可以插入重复数据
set容器排序:
set容器默认排序规则为从小到大,可以利用仿函数,可以改变排序规则
示例一 set存放内置数据类型
#include <set>
class MyCompare
{
public:
bool operator()(int v1, int v2) {
return v1 > v2;
}
};
void test01()
{
set<int> s1;
s1.insert(10);
s1.insert(40);
s1.insert(20);
s1.insert(30);
s1.insert(50);
//默认从小到大
for (set<int>::iterator it = s1.begin(); it != s1.end(); it++) {
cout << *it << " ";
}
cout << endl;
//指定排序规则
set<int,MyCompare> s2;
s2.insert(10);
s2.insert(40);
s2.insert(20);
s2.insert(30);
s2.insert(50);
for (set<int, MyCompare>::iterator it = s2.begin(); it != s2.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
int main() {
test01();
system("pause");
return 0;
}
总结:利用仿函数可以指定set容器的排序规则
示例二 set存放自定义数据类型
#include <set>
#include <string>
class Person
{
public:
Person(string name, int age)
{
this->m_Name = name;
this->m_Age = age;
}
string m_Name;
int m_Age;
};
class comparePerson
{
public:
bool operator()(const Person& p1, const Person &p2)
{
//按照年龄进行排序 降序
return p1.m_Age > p2.m_Age;
}
};
void test01()
{
set<Person, comparePerson> s;
Person p1("刘备", 23);
Person p2("关羽", 27);
Person p3("张飞", 25);
Person p4("赵云", 21);
s.insert(p1);
s.insert(p2);
s.insert(p3);
s.insert(p4);
for (set<Person, comparePerson>::iterator it = s.begin(); it != s.end(); it++)
{
cout << "姓名: " << it->m_Name << " 年龄: " << it->m_Age << endl;
}
}
int main() {
test01();
system("pause");
return 0;
}
map/multimap容器
-
map中所有元素都是pair
-
pair中第一个元素为key(键值),起到索引作用,第二个元素为value(实值)
-
所有元素都会根据元素的键值自动排序
-
map/multimap属于关联式容器,底层结构是用二叉树实现。
优点: -
可以根据key值快速找到value值
map和multimap区别:
- map不允许容器中有重复key值元素
- multimap允许容器中有重复key值元素
pair对组创建
- 成对出现的数据,利用对组可以返回两个数据
创建方式:
pair<type, type> p ( value1, value2 );pair<type, type> p = make_pair( value1, value2 );
map函数常用接口
构造:
-
map<T1, T2> mp;//map默认构造函数: -
map(const map &mp);//拷贝构造函数
赋值: -
map& operator=(const map &mp);//重载等号操作符
map<int,int>m; //默认构造
m.insert(pair<int, int>(1, 10));
m.insert(pair<int, int>(2, 20));
m.insert(pair<int, int>(3, 30));
map中所有元素都是成对出现,插入数据时候要使用对组
大小
size();//返回容器中元素的数目empty();//判断容器是否为空swap(st);//交换两个集合容器
插入删除
insert(elem);//在容器中插入元素。clear();//清除所有元素erase(pos);//删除pos迭代器所指的元素,返回下一个元素的迭代器。erase(beg, end);//删除区间[beg,end)的所有元素 ,返回下一个元素的迭代器。erase(key);//删除容器中值为key的元素。
void printMap(map<int,int>&m)
{
for (map<int, int>::iterator it = m.begin(); it != m.end(); it++)
{
cout << "key = " << it->first << " value = " << it->second << endl;
}
cout << endl;
}
四种插入方式
map<int, int> m;
//第一种插入方式
m.insert(pair<int, int>(1, 10));
//第二种插入方式
m.insert(make_pair(2, 20));
//第三种插入方式
m.insert(map<int, int>::value_type(3, 30));
//第四种插入方式
m[4] = 40;
查找统计
find(key);//查找key是否存在,若存在,返回该键的元素的迭代器;若不存在,返回set.end();count(key);//统计key的元素个数
map排序
map容器默认排序规则为 按照key值进行 从小到大排序,可以利用仿函数,可以改变排序规则(同set)
#include <map>
class MyCompare {
public:
bool operator()(int v1, int v2) {
return v1 > v2;
}
};
void test01()
{
//默认从小到大排序
//利用仿函数实现从大到小排序
map<int, int, MyCompare> m;
m.insert(make_pair(1, 10));
m.insert(make_pair(2, 20));
m.insert(make_pair(3, 30));
m.insert(make_pair(4, 40));
m.insert(make_pair(5, 50));
for (map<int, int, MyCompare>::iterator it = m.begin(); it != m.end(); it++) {
cout << "key:" << it->first << " value:" << it->second << endl;
}
}
int main() {
test01();
system("pause");
return 0;
}
unordered_map
map和unordered_map区别
map: map内部实现了一个红黑树(红黑树是非严格平衡二叉搜索树,而AVL是严格平衡二叉搜索树),红黑树具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素。因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行的操作。map中的元素是按照二叉搜索树(又名二叉查找树、二叉排序树,特点就是左子树上所有节点的键值都小于根节点的键值,右子树所有节点的键值都大于根节点的键值)存储的,使用中序遍历可将键值按照从小到大遍历出来。unordered_map: unordered_map内部实现了一个哈希表(也叫散列表,通过把关键码值映射到Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用)。因此,其元素的排列顺序是无序的。
map优缺点
优点:
- 有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作。红黑树,内部实现一个红黑书使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高
缺点:
- 空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间
unorder_map优缺点
优点:
- 因为内部实现了哈希表,因此其查找速度非常的快
缺点:
- 哈希表的建立比较耗费时间
unordered_map的用法和map是一样的,提供了 insert,size,count等操作,并且里面的元素也是以pair类型来存贮的。但其底层实现是完全不同的。
对于unordered_map或unordered_set容器,其遍历顺序与创建该容器时输入的顺序不一定相同,因为遍历是按照哈希表从前往后依次遍历的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号