

词向量学习笔记
ML调参菜鸟学习笔记
在莫烦Python中的NLP课程做的一点笔记
每一篇文章都可以用词语的出现频率来表示,颜色深的地方,数字的值越大。将文章按照向量的表现形式,投射到一个空间中,他们就有了自己的位置。
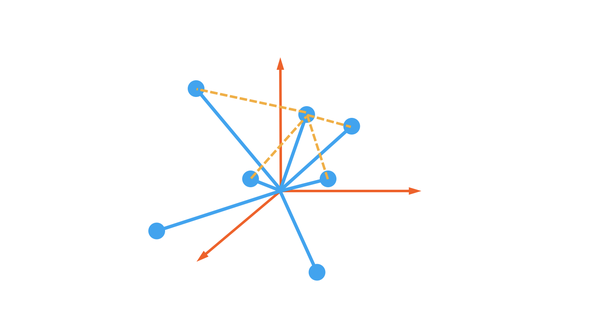
因为每篇文章向量中的数值不同,所有在空间中也会分散开来。在这种可以被计算的空间中,我们就可以比较每一个点之间的距离,离得越近,就可以说他们越像。
物以类聚,人以群分,越相似,他们就离得越近。不管是什么,图片,文章,句子,词语,声音,只要是能够被数值化,被投射到某个空间中,计算机就能计算他们的相似度。
词向量
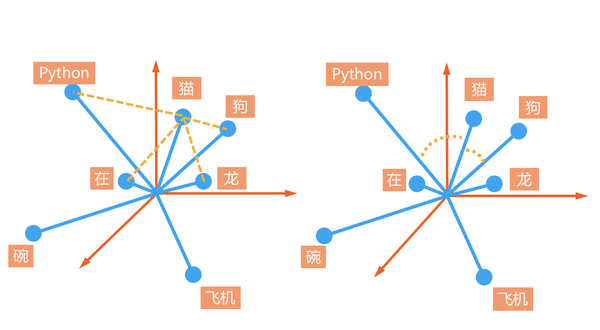
我们用空间中点与点之间的直线距离可以判断词汇的相似程度,而有时候我们并不在乎距离的长短(或强度的大小),只要是词语在一个方向上,我们就认为他们是相近的,这时我们就能用cosine 相似度来测量两个向量的夹角大小。点与点的距离和向量夹角这两种测量方式会带来什么样的差别呢。
在词向量训练的过程中,相似词总会被聚集到一块地方且方向大概都相同,比如这里的猫狗龙。而差异较大的词会被拉远,且方向有可能不同,所以和猫狗这些动物相比,没有生命的飞机,碗等都离得很远。
所以如果只想测量两个词的相似度,角度信息也足够了。但点与点的距离还透露了更多的信息,只要两个词总在一起出现,他们之间的关联性应该越强,距离应该也越近。我们想一想,如果一个词不仅出现的频率高,而且任何句子中都能出现,比如“在”,“你”,“吗”这一类的词,为了得到这些词的位置,机器需要不断计算他们之间的相关性。
这个过程我们称之为机器学习或者模型训练。这些词每次训练的时候都想被拉扯到独立的空间,但是被太多不同方向的词拉来拉去,比如”在”这个字,训练“在这”的时候“在”字被拉扯到靠近“这”字的方向。训练“在家”的时候,“在”字将会更靠近“家”字,后面的训练也一样,所以“在”字因为频率太高,和很多字都能混搭,它就算是之中机器认为的“中性词”,越有区分力的词可能越远离中心地带,因为他们和其他词都不像,而越通用,在每种场景都有的词,就可能越靠近原点。这时,点与点的距离就能告诉我们词的频率性特征。
训练词向量完全不需要像监督学习那样人工给数据打标签,我们可以直接在原始语料上做非监督学习。有取上下文预测中心词,也有取中心词预测上下文。
词向量用法
得到词向量之后,有种用法很简单,就是直接把词向量当成词语特征输入进另一个模型中。这样就能用更加丰富的词向量信息来表示一个词语ID,在这种情况下,我们说词向量是一种预训练特征。eg:用word2vec的方法预先训练好了词语的特征表达,然后在其他场景中拿着预训练的结果直接使用。
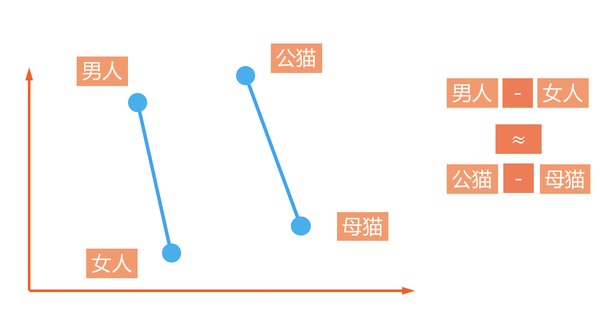
还有更funny的用法,用词向量进行加减运算:eg:男人的词向量减掉女人的词向量,差不多就等于公猫的词向量减去母猫的词向量。
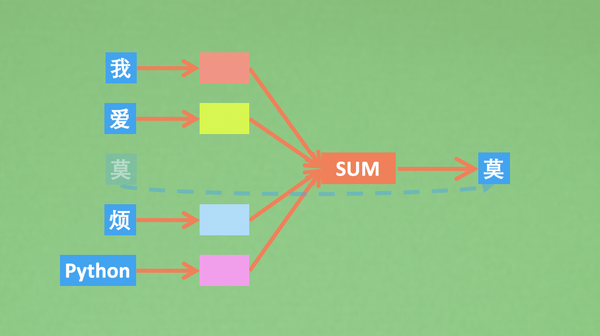
CBOW
continuous bag of words,简称CBOW,
CBOW中的词向量组件,最为核心的就是self.embeddings,词向量就存在于这里。
from tensorflow import keras
import tensorflow as tf
class CBOW(keras.Model):
def __init__(self,v_dim,emb_dim):
super().__init__()
self.embeddings = keras.layers.Embeding(
input_dim = v_dim , output_dim = emb_dim,
embeddings_initializer = keras.initializers.RandomNormal(0.,0.1),
)
接下来就是模型的预测是如何进行的了,我们用class的call功能定义模型的前向预测部分。说白了,其实也就是把预测时的embedding词向量给拿出来, 然后求一个词向量平均,这样输出就够了。在用这个平均的向量预测一下目标值.
class CBOW(keras.Model):
...
def call(self, x, training=None, mask=None):
# x.shape = [n, skip_window*2]
o = self.embeddings(x) # [n, skip_window*2, emb_dim]
o = tf.reduce_mean(o, axis=1) # [n, emb_dim]
return o
在求loss的时候我们稍微做一些手脚,这样可以在训练拥有庞大词汇的模型上有好处。使用nce_loss能够大大加速softmax求loss的方式,它不关心所有词汇loss, 而是抽样选取几个词汇用来传递loss,因为如果考虑所有词汇,那么当词汇量大的时候,会很慢。
class CBOW(keras.Model):
def __init__(self, v_dim, emb_dim):
...
# noise-contrastive estimation
self.nce_w = self.add_weight(
name="nce_w", shape=[v_dim, emb_dim],
initializer=keras.initializers.TruncatedNormal(0., 0.1)) # [n_vocab, emb_dim]
self.nce_b = self.add_weight(
name="nce_b", shape=(v_dim,),
initializer=keras.initializers.Constant(0.1)) # [n_vocab, ]
self.opt = keras.optimizers.Adam(0.01)
# negative sampling: take one positive label and num_sampled negative labels to compute the loss
# in order to reduce the computation of full softmax
def loss(self, x, y, training=None):
embedded = self.call(x, training)
return tf.reduce_mean(
tf.nn.nce_loss(
weights=self.nce_w, biases=self.nce_b, labels=tf.expand_dims(y, axis=1),
inputs=embedded, num_sampled=5, num_classes=self.v_dim))
def step(self, x, y):
with tf.GradientTape() as tape:
loss = self.loss(x, y, True)
grads = tape.gradient(loss, self.trainable_variables)
self.opt.apply_gradients(zip(grads, self.trainable_variables))
return loss.numpy()
from utils import process_w2v_data
def train(model, data):
for t in range(2500):
bx, by = data.sample(8)
loss = model.step(bx, by)
if t % 200 == 0:
print("step: {} | loss: {}".format(t, loss))
if __name__ == "__main__":
d = process_w2v_data(corpus, skip_window=2, method="cbow")
m = CBOW(d.num_word, 2)
train(m, d)
在这里,我们已经能够训练出词向量,除了可视化展示出来。
句子都是由词语组成的,那么有一种理解句子的方式,就是将这个句子的所有词向量都加起来,然后就变成了句子的理解。不过这种空间上的向量相加,从直观上理解,就不是特别成立,因为词向量相加之后,还是在这个词空间中的某个点,要说变成了句向量,好像不行,要是说他是一个词语的理解,好像也不行。
所以一般更常用的就是将这些训练好的词向量当作预训练模型,然后放入另一个神经网络(比如RNN)当成输入,使用另一个神经网络加工之后,训练句向量。
Skip-Gram
Skip-Gram要解决的问题和CBOW一样,就是为了让计算机理解词语,而这种理解,并不像我们人类理解词语那样。计算机能够理解的都只是一些数字,所以我们挑选了数字形式的理解,成为Vector向量。
NLP中,词语的Vector,我们称之为词向量。
CBOW有着这样的结构:使用上下文来预测上下文之间的结果(周边词预测中心词)
而Skip-Gram则是把这个过程反过来,使用文中的某个词,然后预测这个词周边的词(中心词预测周边词)
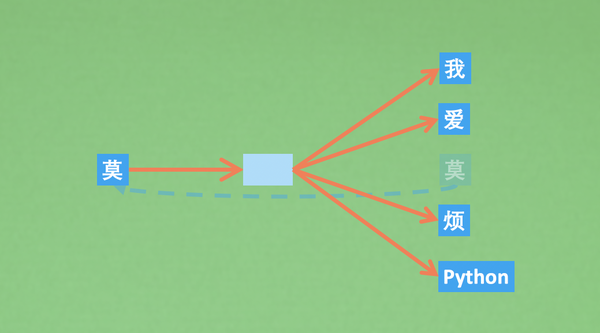
Skip-Gram相比CBOW中最大的不同就是剔除掉了中间的那个sum求和的过程,因为词向量求和这个过程不太符合直观上的逻辑,所以Skip-Gram更易于接受。
但是Skip-Gram和CBOW训练出的词向量不能表达一词多义的情况。如果这个词向量的表示能够考虑到句子上下文的信息,那么这个词向量就能表达词语在不同句子中的不同含义了。
向量表示是深度学习成功的关键。对句子的理解就是在多维空间中给这个句子安排一个合适的位置。
句向量
Seq2Seq生成模型
随着深度学习的发展,我们也能利用像循环神经网络或者自注意力这样的机制,去用模型直接理解整个句子,最终实现了END-TO-END的句子理解。如果用一句话来说明这样技术的核心,那么:向量表示是深度学习成功的关键,对句子的理解,就是在多维空间中给这个句子安排一个合适的位置。
Encoder & Decoder
There is two problems:
1,How to transform raw data to vector data
怎样从原始的数据变成向量数据
2.How to make vector data become other representation
怎么样加工向量化的数据,使其变成各种其他的表达形式
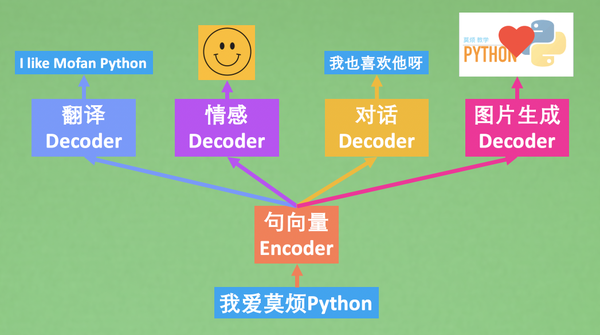
-
我们用
Encoder将原始的我爱莫烦Python转变成标准的向量表达; -
在用各种
Decoder将向量化表达转变成其他的表达形式,其中就可以是翻译,图片,情感和对话。
句子翻译
在NLP的翻译应用领域,Seq2Seq的意思是将一个sequence转换成另一个sequence。也就是用Encoder压缩并提炼出来第一个sequence的信息,然后用Decoder将这个信息转换成另一个语言。
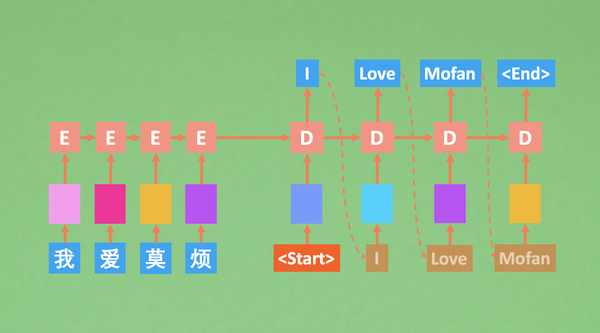
在seq2seq中,decoder在训练时和句子生成时时不同的,为了方便训练,尤其是在刚开始训练时,decoder的输入如果是True Label,那么可以大大的减少训练难度,不管在训练时有没有预测错,下一步在decoder的输入都是正确的。
而在生产环境中,真的做翻译任务时,我们就希望有一种decoder的sample方式。使decoder下一步的预测基于decoder上一步的预测,而不是true label。
CNN的语言模型
用N个不同长度时间窗口,以CNN卷积的方法在句子中依次滑动,让模型拥有N种阅读的眼界宽度,综合N种宽度的信息总结出这句话的内容。
在翻译的模型中,实际上是要构建一个Encoder,一个Decoder。这节CNN做文字翻译的内容中,我们更关注的是用CNN的方法来做Encoder,让计算机读懂句子,至于Decoder,我们还是使用Seq2Seq当中的RNN decoder来实现。
Attention注意力机制
可不可以绕过RNN,直接在词向量阶段就开始使用注意力?在理解一句话时:
-
我们可以选择先读一遍,基于读过之后的理解上,再为后续处理分配不同的注意力;or
-
我们不通读,而是跳着读关键词,直接用注意力方法找出并运用这些关键词
第二种方法在语言的理解上能够更胜一筹,而且在同等量级的网络上,要比第一种方法快很多。而且基于第二种方法在扩展一点,我理解句子的时候可以不仅仅只过目一遍,还可以像多层RNN一样,在理解的基础上再次理解。
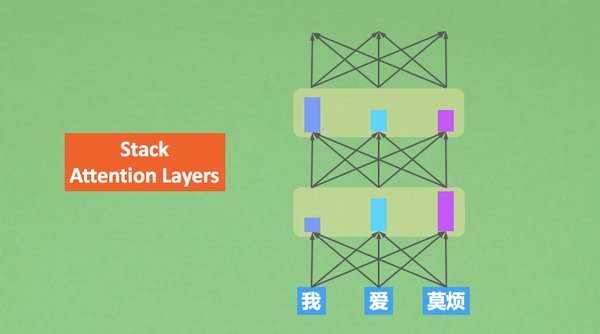
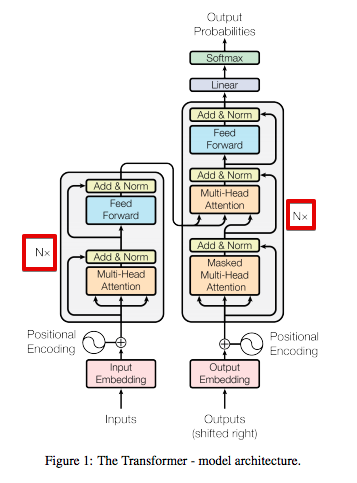
Transformer 这种模型是一种 seq2seq 模型,是为了解决生成语言的问题。它也有一个 Encoder-Decoder 结构,只是它不像RNN中的 Encoder-Decoder。 之后我们将要介绍的 BERT 就是这个 Transformer 的Encoder部分,GPT就是它的 Decoder 部分,目前我们可以这样理解。
为了完成对语言的理解和任务的输出,使用Encoder对语言信息进行压缩和提炼,然后用Decoder产生相对的内容。详细说明的话,就是Encoder负责仔细阅读,一遍一遍地阅读,每一遍阅读都是重新使用注意力关注到上一次地理解,对上次的理解进行再一次转义,Decoder任务同Seq2Seq的decoder任务一样,同时接收Encoder的理解和之前预测的结果信息,生成下一步的预测结果。
不过,Transfrom的核心点,它的attention是怎么做的呢?
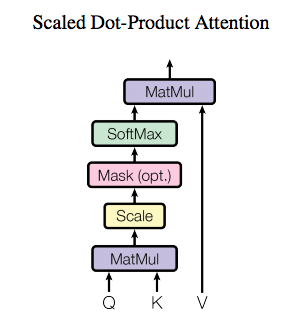
其中有三个东西Query(Q),Key(K),Value(V)。用这三个东西的核心内容就是,快速准确地找到核心内容,换句话说:用我的搜索(Query)找到关键内容(Key),在关键内容上花时间花功夫(Value)。
我拿着我的Query去和Key做对比,得到一个要注意的程度,也就是attention,根据attention去判断我们需要花多久时间来看Value。这就是Transformer的注意力方式。
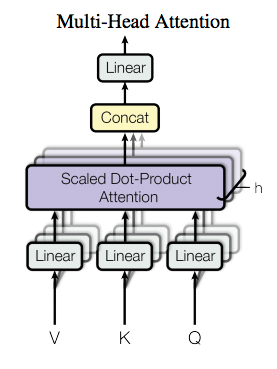
为了增强注意力,Transform还做了一件事,就是Multi-head Attention 多头注意力。
最后一个重点是Decoder怎么样拿到Encoder对句子的理解的?或者Encoder是怎么样引起Decoder的注意的? 在理解这个问题之前,我们需要知道Encoder和Decoder都存在注意力,Encoder里的的注意力叫做自注意力(self-attention), 因为Encoder在这个时候只是自己和自己玩,自己捣鼓一句话的意思。而Decoder说:你把你捣鼓到的意思借我参考一下吧。 这时Self-attention在transformer中的意义才被凸显出来。
在Decoding时,decoder会向encoder借一下Key和Value,Decoder自己可以提供Query(已经预测出来的token)。使用我们刚刚提到的K,Q,V结合方式计算。 不过这张图里面还有些细节没有提到,比如 Decoder 先要经过Masked attention再和encoder的K,V结合,然后还有有一个feed forward计算,还要计算残差。 因为这些比起怎么Attention,都略显不那么重要,一个个深入的话,这篇文章就太长了。不过我可以简单提一下。
-
Masked attention: 不让decoder在训练的时候用后文的信息生成前文的信息;
-
Feed forward: 这个encoder,decoder都有,做一下非线性处理;
-
残差计算:这个也是encoder和decoder都有,为了更有效的backpropagation。
预训练模型
基于预训练模型,我们能够用较少的模型,较快的速度得到一个适合于我们自己数据的新模型,而且这个模型效果也不会太差。
预训练模型的核心价值就是:
-
手头只有小数据集,也能得到一个好模型
-
训练速度大大提升,不用从头开始训练
可以用作预训练模型的架构,如GPT、BERT
ELMO
传统的使用skip-gram和cbow训练出来的词向量,在ELMO看来,是有问题的,ELMO的全称是:Embeddings from Language Models,他的主要目标是:找出词语在句子中的意思
具体来说,ELMO还是想用一个向量来表示词语,不过这个词语的向量会包含上下文的信息。
想要让模型给出的词向量拥有上下文信息。我们就在词向量中加上从前后文来的信息就好了,这就是ELMo最核心的思想。
可以理解为ELMO就是一种双向RNN架构,ELMO中有两个RNN(LSTM),一个从前往后看句子,一个从后往前看句子,每一个词向量的表达,就是这几个信息的累计:
-
从前往后的前文信息
-
从后往前的后文信息
-
当前词语的词向量信息
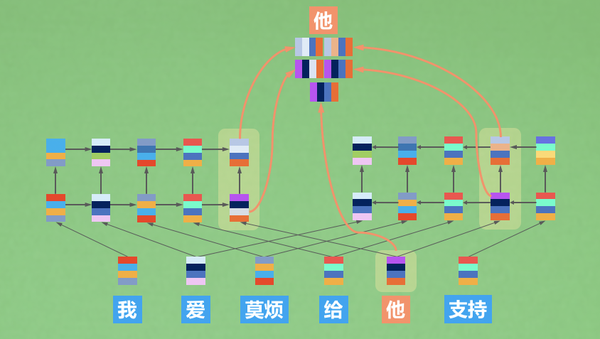
How to train
一般来说,我们希望预训练模型是在无监督的条件下被训练的,所谓NLP的无监督学习,就是拿着一大堆文本,用他们的前文预测后文,后文预测前文,或者两个一起混合预测。不管是BERT还是GPT,都是这样的方式。
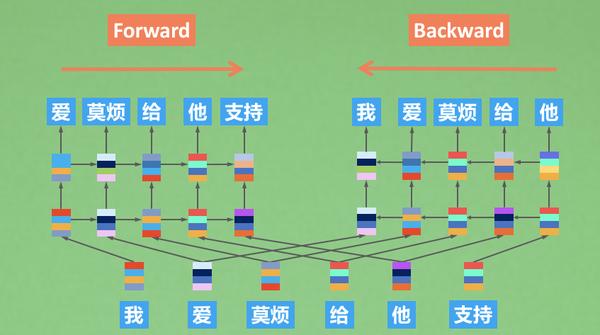
ELMO的训练,就是这种形式,他的前向LSTM预测后文的信息,后向LSTM预测前文的信息。训练一个顺序阅读者和一个逆序阅读者,在下游任务的时候,分别让顺序阅读者和逆序阅读者,提供他们从不同角度看到的信息,这就是ELMO的训练和使用。
Transformer同样可以做预训练,而且训练效果和结果比ELMO更好。
GPT单向语言模型
有没有什么好办法可以享受准确率的同时又不费时间又不费力的训练模型呢,预训练就是解决方法
GPT,Generative Pre-Training(GPT)模型成功的将Transformer里的注意力运用在语言模型中,并且能够让模型精准地预测出答案。
GPT主要的目标还是当好一个预训练模型该有的样子。用非监督的人类语言数据,训练一个预训练模型,然后拿着这个模型进行finetune, 基本上就可以让你在其他任务上也表现出色。因为下游要finetune的任务千奇百怪,在这个教学中,我会更专注GPT模型本身。 告诉你GPT模型到底长什么样,又会有什么样的特性。至于后续的finetune部分,其实比起模型本身,要容易不少。
具体到GPT的模型,其实它和Transformer有着目不可分的联系。它更像是Transformer Decoder和Encoder的结合。用着Decoder的Future Mask(Look Ahead Mask),但是结构上更像Encoder。
与Transformer Decoder的不同之处是,它没有借用到Encoder提供的 self-attention 信息。所以GPT的Decoder要比Transformer少一些层。 那么最终的模型乍一看的确和Transformer的某一部分很像,不过就是有两点不同。
-
Decoder 少了一些连接 Encoder 的层;
-
只使用Future Mask (Look ahead mask)做注意力。
BERT
BERT和GPT还有ELMO是一个性质的东西。
它存在的意义是要变成一种预训练模型,提供NLP中对句子的理解。ELMO用了双向LSTM作为句子信息的提取器,同时还能表达词语在句子中的不同含义,GPT呢,它是一种单向的语言模型,同样也可以用attention的方式提取到更加丰富的语言意思信息。BERT,它就是和GPT是同一个家族,都是从Transformer演变而来的。
BERT算是一种双向的语言模型,而这种双向性,其实正是原封不动的Transformer的Encoder部分。
BERT的Mask具体就是三种方式:
随机选取15%的词做如下改变:
-
80%的时间,将它替换成[Mask]
-
10%的时间,将它替换为其他任意词
-
10%的时间,不变
预测[Mask]是BERT的一项最主要的任务,在非监督学习中,我们还能借助上下文做件事,就是让模型判断,相邻的这两句话是否是上下文关系。
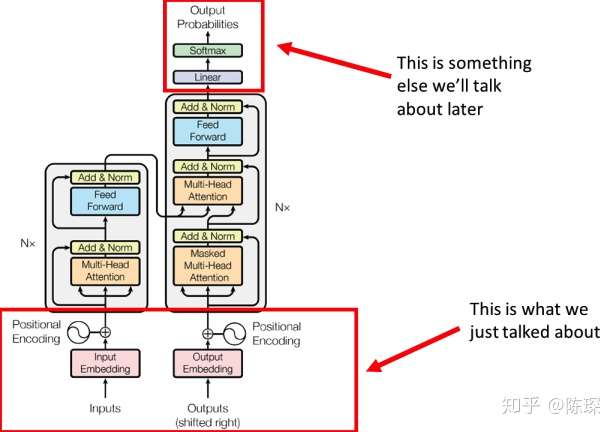
Transformer
Transformer分为三个部分:
-
Embedding部分
-
Encoder部分
-
Decoder部分
主要目的都一样,Encoder负责仔细阅读,一遍一遍地阅读,每一遍阅读都是重新使用注意力关注到上次的理解,对上次的理解进行再一次转义。Decoder任务同Seq2Seq的decoder任务一样,同时接收Encoder的理解和之前预测的结果信息,生成下一步的预测结果。
对Input的represent:
首先用常用的表达categorical的特征的方法即one-hot encoding对句子进行表达。one-hot指的是一个向量只有一个元素是1,其余的都为0,很直接的,vector的长度就是由词汇表vocabulary的长度决定的,如果想要表达10000个word,那么就需要10000维的向量。
word embedding
我们不直接输入简单的one-hot vector,原因是one-hot编码这种表达的方式十分稀疏,且不能表达word与word之间的特征。我们在这里对词使用Embedding,在Pytorch里,一般是使用nn.Embedding来做,或者是使用one-hot vector 与权重矩阵W相乘所得.
nn.Embedding 包含一个权重矩阵 W,对应的 shape 为 ( num_embeddings,embedding_dim )。num_embeddings 指的是词汇量,即想要翻译的 vocabulary 的长度。embedding_dim 指的是想用多长的 vector 来表达一个词,可以任意选择,比如64,128,256,512等。在 Transformer 论文中选择的是512(即 d_model =512)。
其实可以形象地将 nn.Embedding 理解成一个 lookup table(查询表),里面对每一个 word 都存了向量 vector 。给任意一个 word,都可以从表中查出对应的结果。
处理 nn.Embedding 权重矩阵有两种选择:
-
使用 pre-trained 的 embeddings 并固化,这种情况下实际就是一个 lookup table。
-
对其进行随机初始化(当然也可以选择 pre-trained 的结果),但设为 trainable。这样在 training 过程中不断地对 embeddings 进行改进。⚓️
Transformer 选择的是后者。
class Embeddings(nn.Module):
def __init__(self,d_model,vocab):
super(Embeddings,self).__init__()
self.lut = nn.Embedding(vocab,d_model)
self.d_model = d_model
def forward(self, x ):
return self.lut(x) * math.sqrt(self.d_model)
Positional Embedding (位置嵌入)
我们对每一个word进行embedding作为input表示.但是还有问题,embedding本身不包含在句子中的相对位置信息.
RNN为什么在任何地方都可以对同一个word使用同样的向量呢?因为RNN是按顺序对句子进行处理的,一次一个word,但是在Transformer里,输入句子的所有word是同时处理的.没有考虑词的排序和位置信息.
所以,在Transformer里,加入了positional Embedding这个方法来解决这个问题.
positional Embedding 和 word Embedding 相加就得到Embedding with position
可以通过训练学习positional encoding 向量或是使用公式来计算positional encoding向量,一般使用公式来计算.
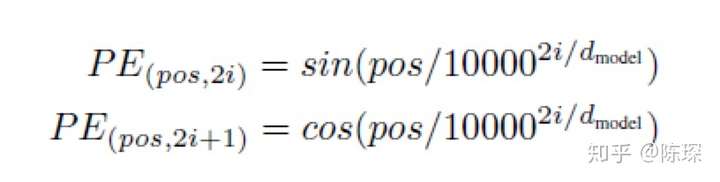
-
pos 指的是这个 word 在这个句子中的位置
-
i指的是 embedding 维度。比如选择 d_model=512,那么i就从1数到512
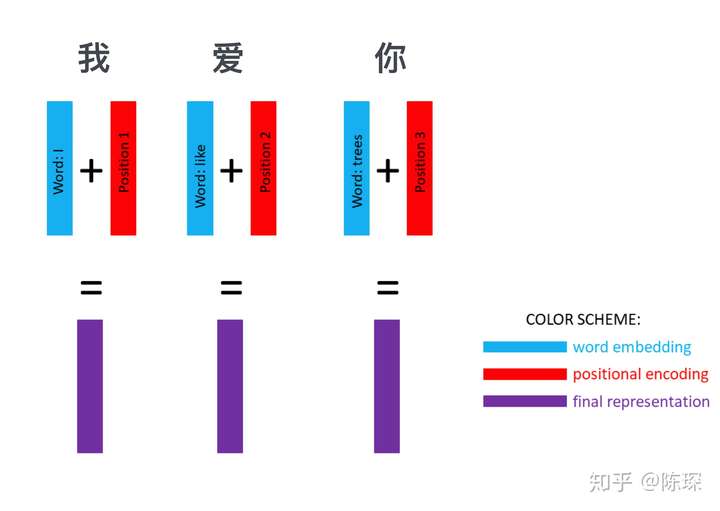
经过 word embedding 和 positional embedding 后可以得到一个句子的 representation,比如”我爱你“这个句子,就被转换成了三个向量,每个向量都包含 word 的特征和 word 在句子中的位置信息:
我们对输出的结果做同样的操作,这里即中英翻译的结果 ”I Love You“。使用word embedding 和 positional encoding 对其进行 represent。
Input Tensor 的 size 为 [nbatches, L, 512]:
-
nbatches 指的是定义的 batch_size
-
L 指的是 sequence 的长度,(比如“我爱你”,L = 3)
-
512 指的是 embedding 的 dimension
Encoder
Encoder相对Decoder会稍微麻烦一些.Encoder由6个相乘的Layer堆叠而成.每个Layer包含2个sub-layer
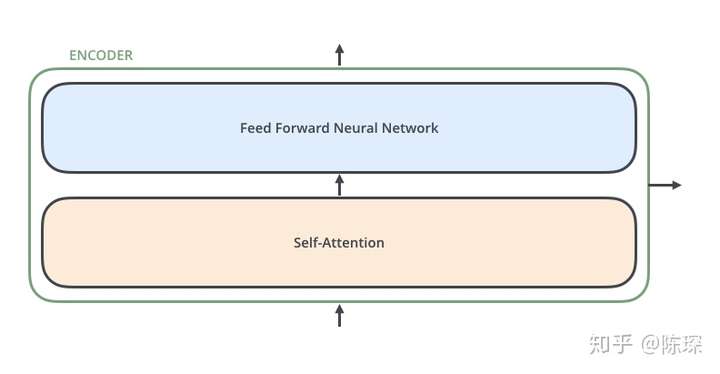
-
第一个是 multi-head self-attention mechanism
-
第二个是 simple , position-wise fully connected feed-forward network
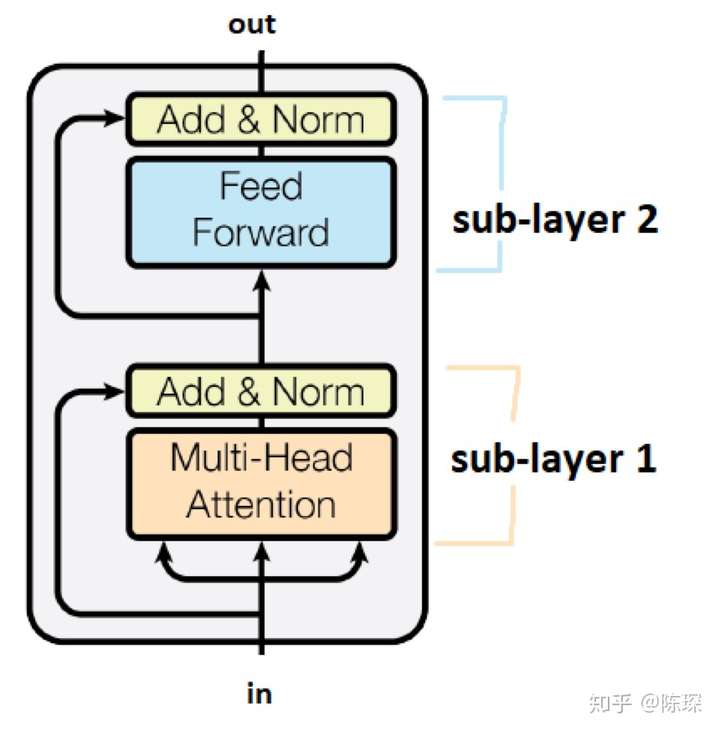
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
-
class “Encoder” 将 <layer> 堆叠N次。是 class “EncoderLayer” 的实例。
-
“EncoderLayer” 初始化需要指定<size>,<self_attn>,<feed_forward>,<dropout>:
-
<size>对应d_model,论文中为512
-
<self_attn>是class MultiHeadedAttention的实例,对应sub-layer 1
-
<feed_forward>是class PositionwiseFeedForward的实例,对应sub-layer 2
-
<dropout>对应dropout rate
-
我们把 attention 机制的输入定义为 x。x 在 Encoder 的不同位置,含义有所不同。在 Encoder 的开始,x 的含义是句子的 representation。在 EncoderLayer 的各层中间,x 代表前一层 EncoderLayer 的输出
使用不同的 linear layers 基于 x 来计算 keys,queries和values:
-
key = linear_k(x)
-
query = linear_q(x)
-
value = linear_v(x)
linear_k, linear_q, linear_v 是相互独立、权重不同的。
计算得到 keys(K), queries(Q)和values(V) 值之后,按论文中如下公式计算 Attention:
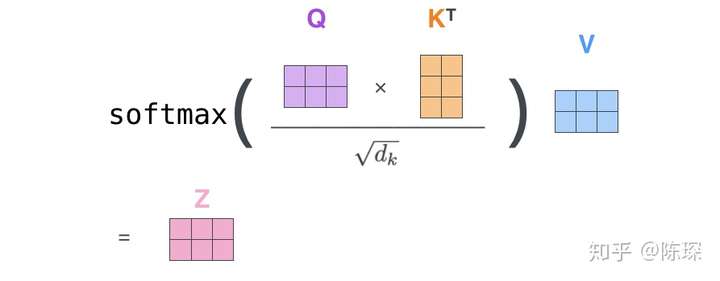
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号