【论文笔记】Adversarial Training for Weakly Supervised Event Detection
简介
- 事件检测
事件检测(ED)的目的是检测事件触发器(通常是在实例中引发事件的单词或短语),然后识别它们的特定事件类型。
- 特征工程,如token级特征和结构化特征。
- 神经网络模型,将文本语义信息直接嵌入到低维空间中,基于这些特征向量检测事件触发器,采用有监督学习的方法对人类标注数据进行模型训练。
神经网络模型对人工标注数据的需求是实践中的瓶颈。
- 弱监督学习
参考资料 https://baijiahao.baidu.com/s?id=1594091883249224246&wfr=spider&for=pc
目前广泛采用的弱监督方法充分利用了大量的原始数据,特别是一些具体的信息提取工作,探索了弱监督自动标注ED训练数据的方法,这种弱监督方法可以有效地推广到实际的ED应用中,而不需要大量的劳动。
弱监督方法虽然取得了很好的结果,但仍然存在一些严重的问题:
- 会受到数据中不可避免的噪声的影响
- 现有的弱监督ED模型采用复杂的预定义规则和不完全的知识库来自动获取数据,导致数据的自动标注覆盖率低、主题偏差大
- 本文提出的模型
为了构建一个覆盖范围更广的大规模数据集,减少主题偏差
避免采用复杂的预定义规则和繁重的语义组件分析工具包,提出了一个简单的基于触发器的潜在实例发现策略
一个假设:如果一个给定的单词作为已知事件实例中的触发器,那么提到这个单词的所有实例也可以表示一个事件
与复杂的规则相比,该策略在单词、触发器和事件类型之间的相关性方面限制较少。因此,我们的策略可以在不需要任何人工设计的情况下,获得覆盖更多主题和实例的候选集。
进一步提出了一种对抗性训练机制,它不仅可以从候选集中提取出信息实例,而且可以提高ED模型在诸如远程监控等噪声场景下的性能:
- 将数据集分为可靠集和不可靠集
- 设计了一个鉴别器(判断给定实例的信息量和注释是否正确)和一个生成器(从原始数据中选择最易混淆的实例来欺骗鉴别器)
- 以可靠数据为正实例,以生成器选择的数据为负实例,对判别器进行训练
- 训练生成器选择数据以欺骗鉴别器
- 在训练过程中,生成器可以提供大量的潜在噪声数据来增强鉴别器,鉴别器可以影响生成器选择那些信息量更大的数据
- 由于噪声数据对生成器和鉴别器的优化都没有影响,本文将短语视为单词
- 当生成器和鉴别器达到平衡时,鉴别器可以提高对噪声的抵抗能力,更好地对事件进行分类,生成器可以有效地为鉴别器选择信息实例
- 本文提出的实验
在半监督和远程监督两种情况下进行了实验。
实验结果表明,基于触发器的潜在实例发现策略和对抗性训练方法能够协同获得更为多样化和精确的训练数据,并减少噪声问题的副作用,从而显著优于现有的ED模型。
相关工作
- 基于特征的方法。依赖于人工设计的特征来检测事件触发器和事件类型。
- 神经网络方法
- 利用外部知识、上下文信息、文档级信息和多模式集成来提高ED系统的性能
- 先进的体系结构,如注意机制、图卷积网络和生成对抗网络
以上所有的监督方法都依赖于人工标注的数据,而且由于人工标注代价昂贵,数据往往被限制在小范围内。
- 无监督方法和各种弱监督方法。
- 采用远程监控的方式为低资源语言创建训练实例
- 采用WordNet和基于规则的方法生成没有事件类型标签的开放域数据
- 在知识库中利用远程监控从现有结构化事件知识中生成大规模数据
- 用自举进行半监督学习
由于现有知识库的覆盖率低,以及缺乏先进的去噪机制,这些弱监督的方法仍然遭受低覆盖率和噪声数据的问题。
近年来,在Szegedy的启发下,对抗性训练被广泛应用于文本分类、文本生成等领域。对抗训练也被用于信息提取。这些对抗性信息提取方法要么通过在嵌入数据中加入简单的噪声扰动来产生对抗性实例,要么主要采用模型去噪,而忽略了从原始数据中发现更多的训练实例。与这些方法相比,我们的对抗方法从真实数据中提取对抗实例,而不是产生伪噪声扰动。此外,我们的方法不仅去除了自动标记的数据,而且还标记了未标记的实例,以扩展数据集以获得更高的覆盖率。因此,我们的方法可以有效地缓解ED中的低覆盖率、话题偏差和噪声问题。
模型
框架
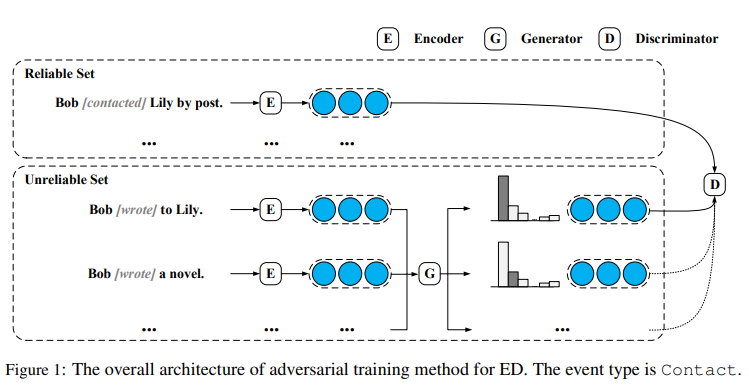
实例编码器
选择CNN和BERT作为实例编码器
CNN 在将实例\(x\)中的所有单词表示为它们的输入嵌入(包括单词嵌入和位置嵌入,它们对候选触发器的相对位置进行编码)后,CNN在输入嵌入上滑动卷积核以获得隐藏嵌入
BERT 类似于CNN,在将实例\(x\)中所有单词的词条、段和位置嵌入相加作为输入嵌入后,BERT采用多层双向变压器编码器得到隐藏嵌入
由于候选触发器\(t\)将实例\(x\)分为两部分,因此对隐藏的嵌入采用动态多池操作来实现实例嵌入
其中,\([·]_j\)是向量的第\(j\)个值,\(i\)是触发器\(t\)的位置。由于CNN和BERT采用动态多池操作,因此本文将它们命名为“DMCNN”和“DMBERT”
对抗策略
对抗策略的总体框架由一个鉴别器和一个生成器组成:
- 鉴别器检测数据集中每个实例的事件触发器和事件类型,当给定一个有噪声的实例时,鉴别器也要抵抗噪声,并明确指出没有触发器和事件。
- 生成器用于从不可靠的数据集\(\mathcal{U}\)中选择实例,以尽可能地混淆鉴别器。
假设每个实例\(x∈\mathcal{R}\)显式地表示其标记的触发器\(t\)和事件类型\(e\)
假设每个实例\(x∈\mathcal{U}\)在对抗训练中不可信,即存在一定的错误标记概率
因此,我们设计了一个判别器来判断给定的实例是否能够暴露其标记事件类型,其目的是使条件概率\(p(e|x,t),x\in \mathcal{R}\)和\(1-p(e|x,t),x\in \mathcal{U}\)最大化。
发生器被训练,以从\(\mathcal{U}\)中选择最令人困惑的实例来愚弄判别器,即通过\(p(e|x,t),x\in \mathcal{U}\)选择实例。训练过程是一个对抗性的min-max博弈
其中\(P_R\)是可靠的数据分布,生成器根据概率分布\(P_U\)从不可靠的数据中抽取对抗性示例
虽然\(\phi D\)和\(\phi G\)是冲突的,但\(\mathcal{U}\)中的噪声数据对\(\phi D\)和\(\phi G\)都有副作用
当生成器和鉴别器经过充分训练达到平衡时,生成器倾向于选择那些概率比噪声更高的信息实例,鉴别器增强了对噪音和能更好地分类事件
鉴别器
给定实例\(x\)及其标记的触发器\(t\)和事件类型\(e\),鉴别器负责判断给定实例是否公开其标记的触发器和事件类型。在用实例\(x\)的嵌入\(x\)表示实例\(x\)之后,我们实现了如下的鉴别器
其中e是事件类型\(e\in \mathcal{E}\)的嵌入
一个最优化的鉴别器会在\(\mathcal{R}\)中给那些实例分配高分,同时不信任那些实例和它们在\(\mathcal{U}\)中的标签,因此损失函数
在对鉴别器进行优化时,我们将编码器和\(D(e|x,t)\)的分量作为参数进行更新。这个损失函数\(\mathcal{L}_D\)对应于\(\phi _D\)
生成器
生成器的目的是从\(\mathcal{U}\)中选择最混乱的实例来欺骗鉴别器。
设计生成器来优化概率分布\(P(\mathcal{U})\)以选择实例.
生成器计算所有\(\mathcal{R}\)中的混淆分数,以评估他们的困惑,并进一步计算混淆概率\(P(\mathcal{R})\)
其中x是编码器计算的实例x的嵌入。W和b是分离超平面的参数
认为实例的鉴别器计算出的分数越高,实例就越混乱,因为它们更容易欺骗鉴别器做出错误的决定。
期望优化的生成器更加关注那些最令人困惑的实例。
因此,给定一个实例\(x∈\mathcal{U}\)及其不可靠的标记触发器t和事件类型\(e\),损失函数
其中\(P(e|x,t)\)由鉴别器计算。在优化生成器时,我们将计算\(P_{\mathcal{U}}(x)\)的组件作为参数进行更新
损失函数\(\mathcal{L}_G\)对应于\({\phi}_G\)
在标记为NA的\(\mathcal{U}\)中可能存在一些实例,这些实例总是被错误地预测到其他一些事件中
特别使用所有可行事件的平均得分来代替公式(8)中的\(P(e|x,t)\)
其中\(\mathcal{E}\)表示事件类型的集合
训练和应用细节
由于\(\mathcal{R}\)和\(\mathcal{U}\)中可能存在大量的实例,直接计算\(\mathcal{L}_D\)和\(\mathcal{L}_G\)是非常耗时的,因此频繁地遍历\(\mathcal{R}\)和\(\mathcal{R}\)的整个数据集也变得困难。
为了提高训练效率,对\(\mathcal{R}\)和\(\mathcal{R}\)的子集进行采样以逼近基本概率分布,并将一个新的损失函数形式化为优化,
其中\(\widetilde{\mathcal{R}}\)和\(\widetilde{\mathcal{U}}\)是从\(\mathcal{R}\)和\(\mathcal{U}\)采样的子集,而\(P_\widetilde{\mathcal{U}}\)是(7)的近似
α是一个超参数,它控制概率分布的锐度,以避免权重集中在某些特定实例上
全局优化函数
式中,λ是权衡系数
在实践中,对抗性训练中的\(\widetilde{\mathcal{L}}_D\)和\(\widetilde{\mathcal{L}}_G\)是交替优化的
在\(\widetilde{\mathcal{L}}_G\)的学习率中加入了λ,避免了对λ的额外调整
适应弱监督场景
对抗训练策略对各种弱监督ED场景(半监督场景和远程监督场景)的适应性,以及用于对抗训练的可靠集和不可靠集的自动标记和分割方法。
- 基于触发器的潜在实例发现:利用未标记的数据
该策略可以自动标记原始数据的触发器词和事件类型。
基于触发器的策略基于一个启发式假设,即如果给定的单词在已知实例中充当触发器,则在原始数据中提及该单词的所有其他实例都是潜在实例,并且还可以表示事件。
- 半监督场景下采用对抗性训练策略
首先利用小尺度标记数据对编码器和鉴别器进行预训练,使其在一定程度上获得检测事件触发器和识别事件类型的能力。
然后,基于我们的实例发现策略,以标记数据中的触发词作为启发式种子,构造一个大规模的潜在候选集。
我们使用预先训练的编码器和鉴别器,为候选集合中的所有实例自动标记触发器和事件类型,以建立有噪声的大规模数据。
以小尺度标号数据为可靠集R,以大尺度自动标号数据为不可靠集U,对编码器、鉴别器、发生器进行优化,共同进行对抗训练。
在对抗性训练中,当鉴别器和发生器经过一定的训练阶段达到平衡时,将生成器推荐的不可靠集U中被鉴别器正确标记的所有实例从U调整到R。
迭代地进行对抗训练,可以识别U中的信息实例,滤除U中的噪声实例,并利用大规模的未标记数据丰富小规模的训练标记的数据。
- 远程监控场景下采用对抗性训练策略
首先使用全自动标记的数据对编码器和鉴别器进行预训练。
然后,编码器和鉴别器用于计算自动标记集中所有实例的置信度得分。
通过设置特定的阈值,我们可以将整个自动标记集分成两部分:分数高于阈值的实例加入到可靠集R中,分数较低的实例加入到不可靠集U中
待整个自标记集分解为R和U后,我们可以进行对抗性训练,以减少这些噪声在U中的副作用,并增强鉴别器以更好地识别事件。
直观地说,从自标记集中分离出来的可靠集R可以作为种子,以类似的方式在半监督场景中利用更多的原始数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号