Tempdb总结
Tempdb
系统数据库是一个全局资源,可供连接到 SQL Server 实例的所有用户使用,并可用于保存下列各项:
-
显式创建的临时用户对象,例如全局或局部临时表、临时存储过程、表变量或游标。
-
SQL Server 数据库引擎创建的内部对象,例如,用于存储假脱机或排序的中间结果的工作表。
-
由使用已提交读(使用行版本控制隔离或快照隔离事务)的数据库中数据修改事务生成的行版本。
-
由数据修改事务为实现联机索引操作、多个活动的结果集 (MARS) 以及 AFTER 触发器等功能而生成的行版本。
tempdb 中的操作是最小日志记录操作。 这将使事务产生回滚。 每次启动 SQL Server 时都会重新创建 tempdb,从而在系统启动时总是具有一个干净的数据库副本。 在断开联接时会自动删除临时表和存储过程,并且在系统关闭后没有活动连接。 因此 tempdb 中不会有什么内容从一个 SQL Server 会话保存到另一个会话。 不允许对 tempdb进行备份和还原操作。

在SQL SERVER 2000时代,TempDB的文件数需要和CPU核数保持1:1的关系,在SQL SERVER 2005和2008版本这条建议也适用,但由于SQL SERVER 2005+后的优化措施,你不再需要严格按照1:1的比例关系设置CPU核数和TempDB文件数,而是文件数和CPU核数的比例保持在1:2或是1:4就行了。
[题外话:在SQL PASS 2011我的好朋友Bob Ward,也是SQL CSS最牛的人。给出了一个新的公式:如果CPU核数小于等于8,使其比例保持在1:1,而如果CPU核数大于8,使用8个文件,当你发现闩锁争用现象时,每次额外加4个文件]
增加Tempdb文件数,只能有一个文件组(primary):
USE [master]
GO
ALTER DATABASE [tempdb] MODIFY FILE ( NAME = N'tempdev', SIZE = 307200KB )
GO
ALTER DATABASE [tempdb] MODIFY FILE ( NAME = N'templog', SIZE = 307200KB )
GO
ALTER DATABASE [tempdb] ADD FILE ( NAME = N'tempdev1', FILENAME = N'D:\Tempdb\tempdb1.ndf' , SIZE = 307200KB , FILEGROWTH = 102400KB )
迁移Tempdb数据库到其他独立磁盘:
select * from sys.sysfiles ---找到数据库逻辑名
USE master;
GO
ALTER DATABASE tempdb
MODIFY FILE (NAME = tempdev, FILENAME = 'D:\Tempdb\tempdb.mdf');
GO
ALTER DATABASE tempdb
MODIFY FILE (NAME = templog, FILENAME = 'D:\Tempdb\templog.ldf');
GO
重启生效!
收缩Tempdb及报错处理:
重要说明:如果运行 DBCC SHRINKDATABASE,则 tempdb 数据库不能正在发生其他活动。要确保在运行 DBCC SHRINKDATABASE 时其他进程无法使用tempdb,必须以单用户模式启动 SQL Server。
1. dbcc shrinkdatabase (tempdb, 'target percent')
-- This command shrinks the tempdb database as a whole2.use tempdb go dbcc shrinkfile (tempdev, 'target size in MB') go -- this command shrinks the primary data file dbcc shrinkfile (templog, 'target size in MB') go -- this command shrinks the log file, look at the last paragraph.
在 SQL Server 7.0 中,事务日志收缩是一个推迟操作,您必须执行日志截断和备份,以帮助进行数据库中的收缩操作。但是,默认情况下,tempdb 将 trunc log on chkpt 选项设置为“打开”(ON);这样,您就无需为该数据库执行日志截断
当正在使用 tempdb 时,如果您尝试通过使用 DBCC SHRINKDATABASE 或 DBCC SHRINKFILE 命令收缩它,可能会收到与以下类型相似的多个一致性错误,并且收缩操作可能失败:
Server:Msg 2501, Level 16, State 1, Line 1 Could not find table named '1525580473'.Check sysobjects.
- 或 -
Server:Msg 8909, Level 16, State 1, Line 0 Table Corrupt:Object ID 1, index ID 0, page ID %S_PGID.The PageId in the page header = %S_PGID.
尽管错误 2501 可能不表示 tempdb 中的任何损坏,但它会导致收缩操作失败。与其不同,错误 8909 可能表示 tempdb 数据库中的损坏。应重新启动 SQL Server 来重新创建 tempdb 并清除一致性错误。但是,请记住像错误 8909 这样的物理数据损坏可能有其他原因,这包括输入/输出子系统问题。
分配页:
全局分配映射表(GAM):有每4 GB数据文件对应1 个GAM页。它始终在数据文件的第2页中,然后每511232页加一页。
共享全局分配映射表(SGAM):该盘区被用作混合(共享)程度的曲目。有每4 GB数据文件的1 SGAM页。它始终是第3页中的数据文件,然后重复每511232页。
页可用空间(PFS):跟踪每一页的分配状态,大约多少可用空间可以使用。每1/2GB数据文件1 个PFS页。它始终是第1页中的数据文件,然后重复每8,088页。
查找有关分配页闩锁争
您可以使用动态管理视图(DMV)SYS .dm_os_waiting_tasks 找到正在等待资源上的任务。等待PAGEIOLATCH或PageLatch等类型的任务正在经历的争夺。资源描述指向的页面正经历争用,你可以简单地分析,资源描述得到PageId。那么它只是一个数学问题来确定它是否是一个分配页。
资源描述(举例):
资源说明会的形式<数据库ID>:<文件ID>:<页码>在tempdb始终是2.数据库ID样本资源描述可能看起来像2:3:18070499。我们希望把重点放在18070499页ID。
用于确定页面类型的公式如下:
GAM: (PageID - 2)%511232
SGAM:(页PageID - 3)%511232
PFS: (PageID - 1)%8088
如果这些式中的一个等于0,则争用该分配的页面。

ML 映射页
ML 代表最小日志(Minimally Logged )。这种页被用来在BULK_LOGGED 恢复模式中,跟踪自上次日志备份以来哪些区经过最小日志的修改操作。这样下次日志备份时除了正常备份日志,还要包括在位图中标明已修改的所有区。这种备份的区加上事务日志 就是自上次事务日志备份以来所发生的变化。一旦ML 页被读取,所有的位图都会被清除。如果你没有使用过BULK_LOGGED 恢复模式,那么ML 页是不会被使用的。
ML 位图与GAM 位图的结构和覆盖区间完全一致,就是位表示的意思不同:
1) 位为1 表示该区自上次日志备份来进过了最小日志操作的修改。
2) 位为0 表示该区未被修改。
DIFF 映射页
DIFF 表示差异(differential )。这种页被用来跟踪自上次完整备份以来哪些区被修改过。说DIFF 位图用来跟踪自上次差异备份以后的变化是一个常见的误解 。一个差异备份包含自上次完整备份以来的所有修改过的区。使用差异备份可以大大节省恢复时间——可以避免必须恢复自上次完整备份到最后一次差异备份期间的日志备份(以后专门介绍)。所有的位图直到下次完整备份才会被清除。注意:所有上面的解释我并没有说是完整的数据库 备份——因为完整或差异备份包括数据库、文件组和文件层次的备份。
DIFF 位图与GAM 位图的结构和覆盖区间完全一致,就是位表示的意思不同:
1 )位为1 表示该区自上次完整备份以来进行了修改。
2 )位为0 表示该区未被修改。
PFS 页
PFS 表示页可用空间。但是PFS 页跟踪的远不止这些。和GAM 区间相似,每个数据库文件同样也被分割成(概念上)PFS 区间。一个PFS 区间是8088 页或约64MB 。PFS 页中不是位图,它是字节图,每个字节表示PFS 区间中的一页(不包括PFS 页本身)。
字节中每位的含义如下:
1 )位0-2 :页中有多少可用空间
a)0x00 表示空
b)0x01 表示1~50% 满
c)0x02 表示51~80% 满
d)0x03 表示81~95% 满
e)0x04 表示96~100% 满
2 )位3 (0x08 ):页中是否至少有一个ghost 记录?
3 )位4 (0x10 ):是否为IAM 页?
4 )位5 (0x20 ):是否为混合页?
5 )位6 (0x40 ):页是否已分配?(分配状态位)
比如一个IAM 页的PFS 字节为0x70 (已分配 + IAM 页 + 混合页)。你可以使用DBCC PAGE 来查看PFS 页。
跟踪可用空间只适用于存储LOB 值(比如SQL SERVER 2000 中的text/image 类型;SQL SERVER 2005 中再加上varchar(max)/varbinary(max)/XML 类型以及行溢出数据)和堆数据页。因为只有这些页存储的数据不用排序, 所以可以在任何位置插入。而像索引是有明确的顺序的,所以插入点是没有选择的。
注意一点:重置PFS字节并不是很直观。PFS字节不会完全重置(译注:比如清0)而是要等到重新分配页时。当页释放时,只是改变了PFS字节中的分配状态位——这样可以很方便的回滚释放动作。
下面是一个例子。在数据库中表T1 只有一行数据。使用DBCC PAGE 检查IAM 页如下:
PFS (1:1) = 0x70 IAM_PG MIXED_EXT ALLOCATED 0_PCT_FULL
如果我在一个显式事务中删除表,再执行DBCC PAGE ,结果如下:
PFS (1:1) = 0x30 IAM_PG MIXED_EXT 0_PCT_FULL
我们如果回滚事务,那么DBCC PAGE 的输出结果又变成:
PFS (1:1) = 0x70 IAM_PG MIXED_EXT ALLOCATED 0_PCT_FULL
T_SQL:
Select session_id,
wait_type,
wait_duration_ms,
blocking_session_id,
resource_description,
ResourceType = Case
When Cast(Right(resource_description, Len(resource_description) - Charindex(':',resource_description, 3)) As Int) - 1 % 8088 = 0 Then 'Is PFS Page'
When Cast(Right(resource_description, Len(resource_description) - Charindex(':',resource_description, 3)) As Int) - 2 % 511232 = 0 Then 'Is GAM Page'
When Cast(Right(resource_description, Len(resource_description) - Charindex(':',resource_description, 3)) As Int) - 3 % 511232 = 0 Then 'Is SGAM Page'
Else 'Is Not PFS, GAM, or SGAM page'
End
From sys.dm_os_waiting_tasks
Where wait_type Like 'PAGE%LATCH_%'
And resource_description Like '2:%'
闩锁(Latch)。闩锁是SQL Server存储引擎使用轻量级同步对象,用来保护多线程访问内存内结构。
锁(Locks) 闩锁(Latches)
- 控制…… 事务 线程
- 保护…… 数据库内容 内存中数据结构
- 模式…… 共享的(Shared), 保持(Keep),
更新(Update), 共享的(Shared),
排它的(Exclusive), 更新(Update),排它的(Exclusive),
意向的(Intension) 销毁(Destroy)
- 死锁…… 检测并解决(detection&resolution) 通过严谨代码来避免
- 保持在…… 锁管理器的哈希表(Hashtable) 保护的数据结构(Protected Data Structure)
从表里可以看到,闩锁支持更细粒度保持(Keep)和销毁(Destroy)模式。保持闩锁主要用来引用计数,例如当你想知道在指定闩锁上有多少其它闩锁在等待。销毁闩锁是最有限制的一个(它甚至会阻塞保持闩锁),当闩锁被销毁时会用到,例如当惰性写入器(Lazy Writer)想要释放内存中的页时。我们先介绍下各种闩锁模式,然后说下各个闩锁模式的兼容性。
NL(空闩锁):
- 内部
- 未使用
KP(保持闩锁):
- 可以由多个任务同时持有
- 只被一个DT模式的闩锁阻塞
SH(共享闩锁):
- 读取数据页的时候使用
- 可以由多个任务同事持有
- 阻塞EX模式和DT模式的闩锁
UP(更新闩锁):
- 写入系统分配页面和tempdb的行版本化页面时使用
- 一个这种模式的闩锁只能被一个单独的任务持有
EX(排它闩锁):
- 写入数据页的时候使用
- 一个这种模式的闩锁只能被一个单独的任务持有
DT(销毁闩锁):
- 很少使用
- 一个这种模式的闩锁只能被一个单独的任务持有
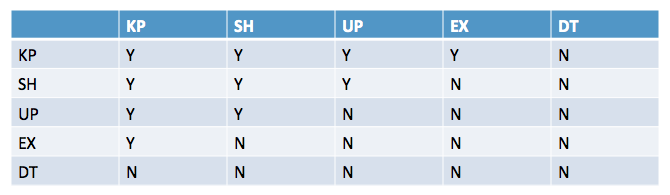
在SQL Server里,一致性不能只用锁来获得。SQL Server还是可以访问没被锁管理器保护的共享数据结构,例如页头。还有SQL Server基于闩锁基础的其他组件也是,有单线程代码路径。好了,我们继续讲解SQL Server里的各种闩锁类型,还有如何对它们进行故障排除
SQL Server区分3个不同闩锁类别
- IO闩锁 PageIOLatch
- 缓冲区闩锁(BUF) PageLatch
- 非缓冲区闩锁(Non-BUF) Latch
通过两个系统视图查看等待详情: sys.dm_os_wait_stats sys.dm_os_latch_stats 查看;
SQL Server 2014内部使用163个闩锁来同步共享数据结构的访问。其中一个著名的闩锁是FGCB_ADD_REMOVE,它用来保护文件组的文件组控制阻塞( File Group Control Block (FGCB)),在以下特定操作期间:
- 文件增长(手动或自动)
- 增加/删除文件组文件
- 重新计算填充比重(Recalculating proportional fill weightings)
- 在循环分配期间,通过文件组的文件回收。
当你看到这个闩锁排在前列是,你肯定有太多自动增长操作的问题,原因是你数据库糟糕的默认配置。当查询尝试读/写保护的数据结构且需要等待一个闩锁时,查询就会进入挂起状态,直到闩锁可以成功获取。因此查询经过的整个查询生命周期包括运行(RUNNING),挂起(SUSPENDED),可运行(RUNNABLE),最后再次运行(RUNNING)。因此,当查询长时间把持闩锁时,强制共享数据结构保护才有意义。那是因为改变查询状态也意味着进行Windows系统里的上下文切换,依据引入的CPU周期是个很昂贵的操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号