

数据挖掘与生活
数据挖掘与生活
前言
写这篇文章的目的是想给公司同事介绍一下数据挖掘的入门知识,旨在增强大家对数据挖掘了解与兴趣,并将这门技术应用到工作和生活中,发挥集体智慧为公司产品增加数据挖掘应用场景。另外对于我自己,以教代学,也可以更好发现自己知识盲点,让输出倒逼输入。
本来是计划写成ppt的,但准备过程中发现ppt实在太花时间了:要找图画图,要做交互,要考虑页面布局,要背演讲稿。最终还是决定写成文章,相对来说容易点,参考性也强一些。
市面上的数据挖掘资料很多,但有些专业性很强,但讲得太抽象,太深奥,有些虽然浅显易懂,但实战意义不强。当然,也有写得比较好的,但相比起来比例还是比较少。
这篇文章我打算按我理解的角度来介绍数据挖掘,重点介绍数据挖掘在生活中的应用,以及非专业人士如何使用数据挖掘解决生活问题。文章中介绍了数据挖掘的一些算法,但很多只是罗列了名词,因为我也没搞清楚这些算法或者没精力详细讲解,只是写出来作为关键字,有兴趣的同学可以自行百度。
写作过程中参考了很多资料文章,无法一一注明了,在此一并做感谢。
文章概述
本文先举了一些生活中使用数据挖掘的案例,让读者对数据挖掘有感性认识。接着介绍了常用的数据挖掘方法,并分别介绍了这些方法的定义和应用场景。
对于每种数据挖掘方法,我都举了一个生活中的小场景作为例子,说明怎么用这个方法来解决这个场景中的问题。例如使用线性回归指导我们买房选房,使用关联分析来辅助彩票选号,用决策树辅助我们阅读体检数据。
另外,我将一些数据处理技巧,例如非数值数据处理方法,文本数据处理方法,算法原理等知识穿插在文章里面,大家在实践时可以参考。
数据挖掘案例
数据挖掘技术在我们生活中随处可见。下面给大家介绍几个案例,让大家对数据挖掘技术有直观感受。

沃尔玛通过数据挖掘发现啤酒与尿布销售关系
20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中。
为了搞清楚具体原因,沃尔玛对这些同时购买啤酒和尿布的顾客展开了调研。最后他们发现,原来购买大部分客户是婴儿父亲。他们在下班回家的路上为孩子买尿布,然后又会顺手购买自己爱喝的啤酒。
在知道这个规律后沃尔玛将这两样商品摆放在一起进行销售、并获得了很好的销售收益。这种现象就是卖场中商品之间的关联性,研究“啤酒与尿布”关联的方法就是购物篮分析。
现在很多购物网站会有推荐商品的功能,在你把某些商品加入购物车后,系统会提示你“购买此商品的人多数会同时购买XXX”,其背后原理,也是依靠“购物篮分析”。
某打车平台通过大数据发现司机与乘客私下交易
某打车平台经过数据挖掘,发现系统中存在大量司机存在相同的操作顺序:“接到订单”->"移动到乘客附近"->"取消订单"->"重新上线"。
经过运营人员分析,这些司机是在借助导航接到乘客后,取消订单,绕过平台与乘客私下交易。这种行为会给乘客出行安全带来安全隐患。
于是该平台新增规定,如果司机上线接单地点与前次取消的订单目的地相近时,就判定司机与乘客私下交易,对其发出警告或者限制其接单。
某购物平台使用数据挖掘提高优惠券营销能力
以优惠券盘活老用户或吸引新用户进店消费是一种重要营销方式。然而随机投放的优惠券对多数用户造成无意义的干扰。对商家而言,滥发的优惠券可能降低品牌声誉,同时难以估算营销成本。 个性化投放是提高优惠券核销率的重要技术,它可以让具有一定偏好的消费者得到真正的实惠,同时赋予商家更强的营销能力。
该购物平台分析通过分析系统消费数据,根据得到优惠券后是否会购买商品的概率,将系统用户划分为几类。针对其中获取到优惠券后大概率会使用的顾客进行集中投放,大大提升了优惠券活动营销效果。
某微博网友质疑天猫双十一销售额数据造假
2019年天猫双十一数据公布后,有网友指出这个数字与4月份一条微博预测的数据十分接近。该博主据此怀疑天猫每年销售额数据是根据公式捏造的。


但其实知道数据挖掘的人会知道,世界上有很多数据都是可以用数据公式预测的。小到公司的业绩,大到全球航空客运量,甚至世界经济总额,人口数量变化,都是可以预测的。
某人使用yolo3辅助自己整理照片
某人为了存储了大量家庭成员生活照片,为了将这些照片按家庭成员分类存储(区分自己夫妻,父母,孩子的照片),他使用labelImg工具对其中一些照片做了标记(父亲,母亲,自己,妻子,孩子,总共5类),并在darknet环境下用yolo3来训练,最终训练出一个模型用于识别照片上家人信息。通过使用这个模型,他就可以很轻易地将照片分类存储。
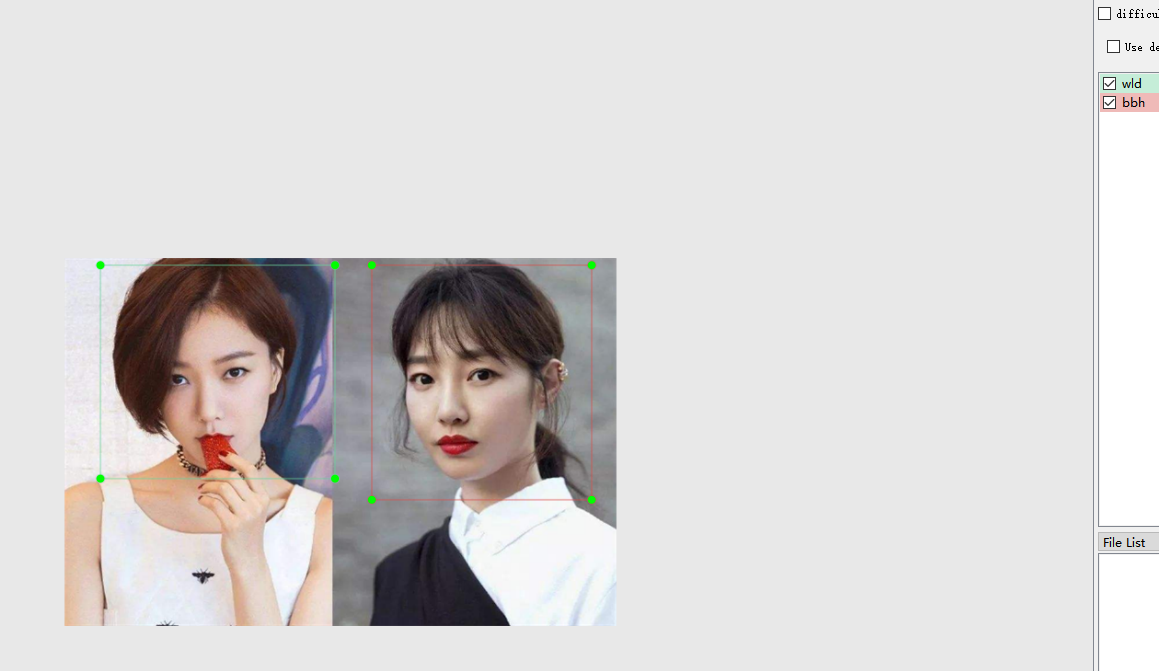
图:训练识别王珞丹和白百何模型的图片打标示例
数据挖掘定义
数据挖掘是指从大量的数据中通过算法找出隐藏于其中有价值的信息的过程。从宏观价值上来说,数据挖掘的价值体现在描述和预测上。
描述:以简洁概要方式描述数据之间规律。例如从房产中介数据中分析影响各种因素对房价的影响。(如房子大小,位置,装修情况等)
预测:是通过对所提供数据集应用特定方法分析所获得的一个或一组数据模型,并将该模型用于预测未来新数据的有关性质。例如根据历史房价信息,预测房价未来几年涨幅。

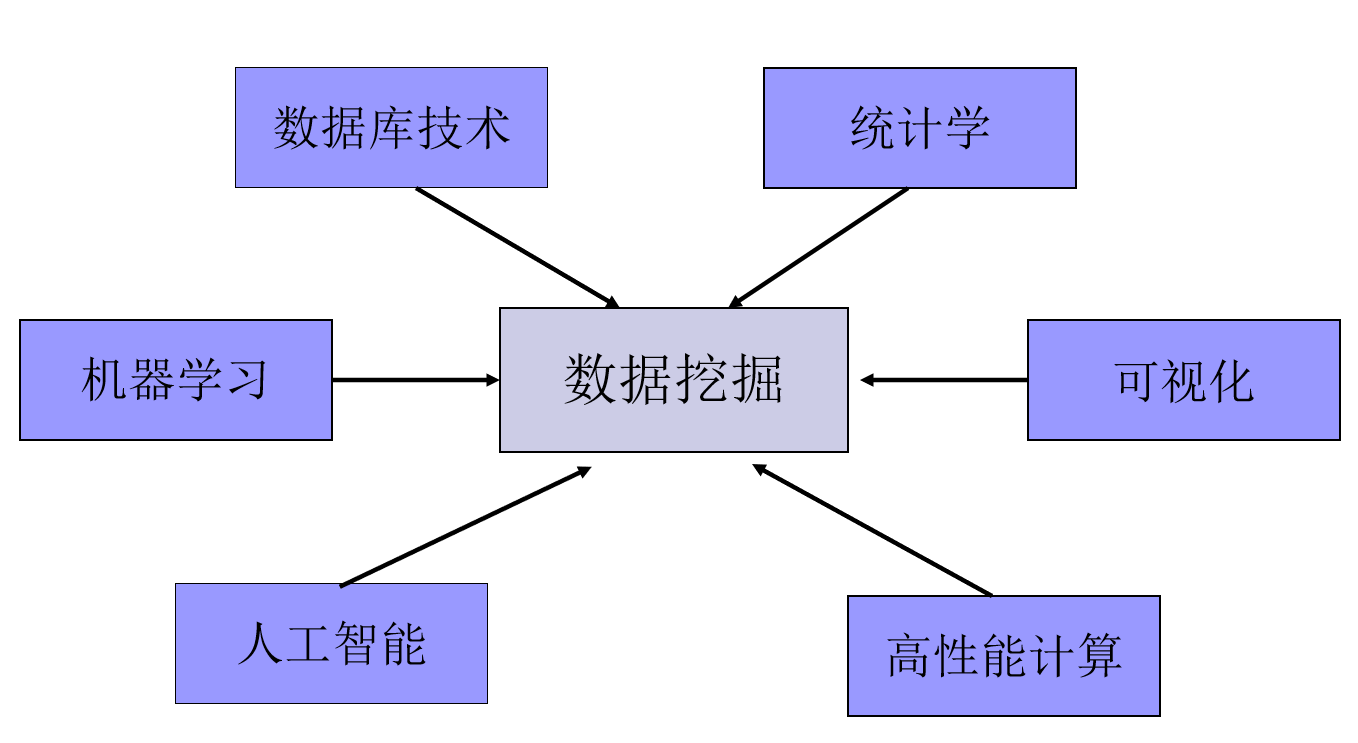
数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
对数据挖掘的错误认识:
1 挖掘出的结果都是正确的
实际:挖掘算法并不保证结果的完全正确,挖掘出的结果只具有概率上的意义,只具有参考价值。
2有数据挖掘就能自动找出系统有价值的信息
实际:数据挖掘只是帮助专业人士更深入、更容易的分析数据。数据挖掘技术可以提供很多模型对数据进行挖掘,但无法告知某个模型对企业的实际价值。
即使得到有用的模型,也要将其与实际生产活动结合才可以体现价值。
常用数据挖掘方法简介
数据挖掘的方法非常多,不过总的来说可以将它们归成几大类。以下是一种归类方法(数据挖掘归类方法有多种,不过大同小异)
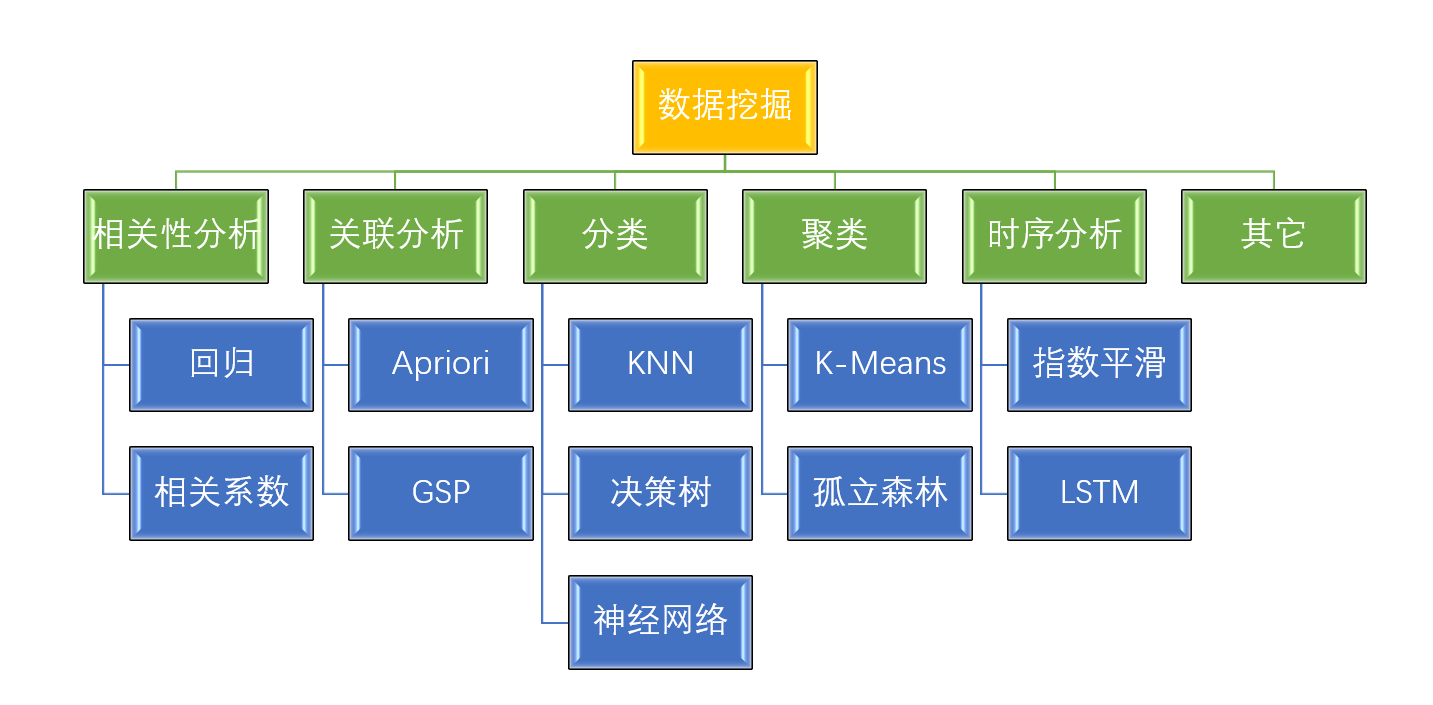
绿色的就是数据挖掘的方法,常见的方法共有五个:相关性分析、关联分析、分类、聚类、时序分析。
每种方法都有多种算法,不同算法适用于不同类型数据,实践时我们可以多尝试几种算法,看哪种算法最适合当前场景。
相关性分析
定义与应用场景
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。
常用算法:
回归
回归分析是处理多变量间相关关系的一种数学方法。它是指研究一组随机变量(Y1 ,Y2 ,…,Yi)和另一组(X1,X2,…,Xk)变量之间关系的统计分析方法。
通常Y1,Y2,…,Yi是因变量,X1、X2,…,Xk是自变量。一般我们会使用数学方程式来表示因变量和自变量之间的关系,用以描述自变量的变化会对因变量产生什么样的影响。
根据回归分析建立的变量间的数学表达式,称为回归方程。
一元线性回归与多元线性回归
线性回归假设输出变量是若干变量的线性组合,并根据这一关系求解线性组合的最优系数。
一个多变量线性回归模型表示为以下的形式:
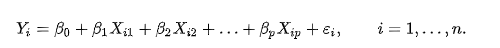
这种模型也称为多元线性回归方程式。如果变量只有一个,那多元线性回归,就会退化成为一元线性回归,回归方程就是我们熟悉的中学知识:直线方程式y = b x + a
方程式中的b,即直线斜率,代表自变量x对y的影响程序。它的绝对值越高,说明x对y的影响越大。
历史上第一个线性回归表达式是用于描述人类子代与父代身高的关系的:
y = 0.516x + 33.73,式中的y和x分别代表子代和父代身高,单位是英寸(一英寸= 2.54厘米)
这个式子表明父代身高比较高时,子代身高大概率会低于父代。反之父代身高较矮时,子代身高有较大可能高于父代。
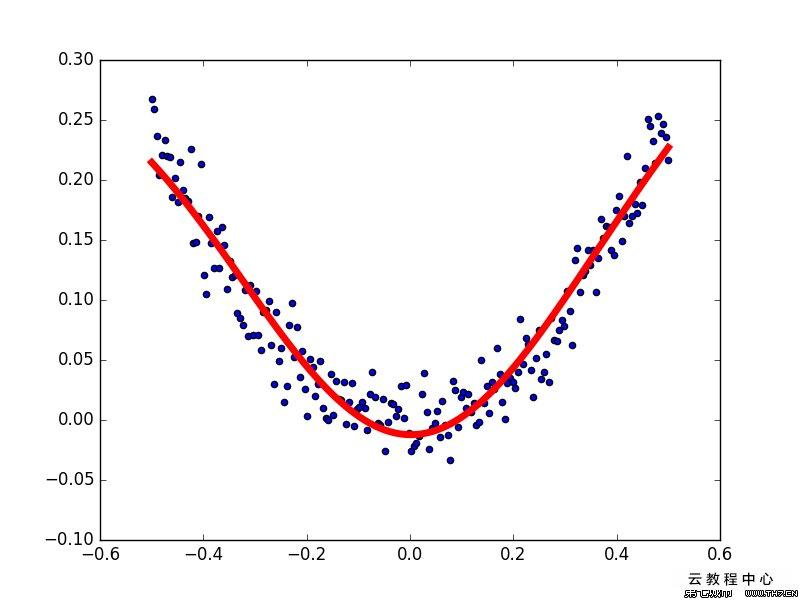
从几何图形上理解,一元线性回归就是找到一条直线,使得每一个y值到直线的距离之和最小。(多元则是找到一个超平面)
线性回归模型简约而不简单,它即能体现回归方法的基本思想,而且又能构造出功能更强大的非线性模型。
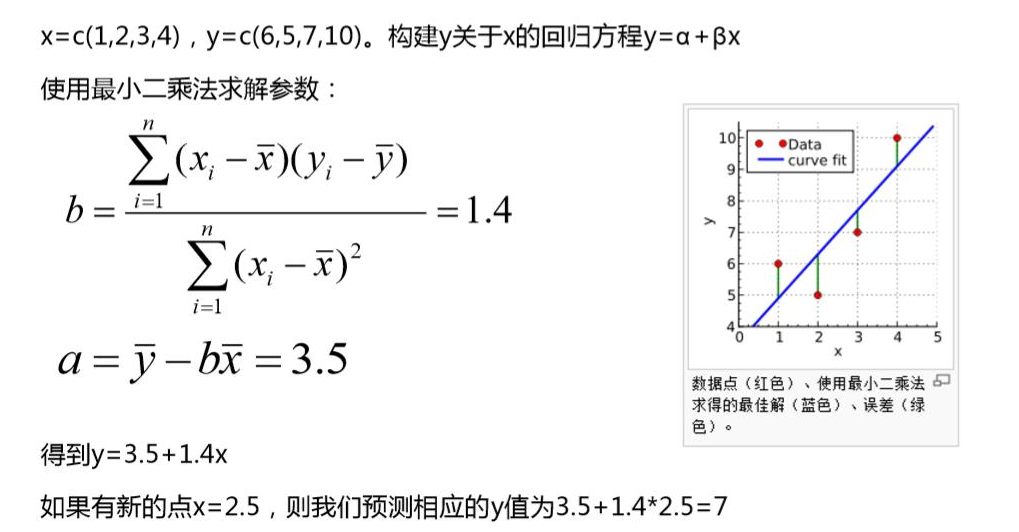
图:一个线性回归计算过程
应用
回归方程式,我们可以预测电影票房,计算王者排名,给法官做刑期建议。
也可以根据公式系数,研究各种变量因素对结果影响大小,例如分析载重和路径分别对油耗影响。
或者根据公式计算结果,寻找与结果差异较大的数据做分析,例如做房地产捡漏。之前我在网上看过一个人使用百度和高德提供的数据,分析开店选址的,也是用到回归的方法。
非线性回归
假设自变量与因变量之间关系是非线性函数的回归分析方法称为非线性回归。
例如抛物线,双曲线,指数增长曲线。
可以使用衍生变量的方法,借助线性回归的方法来计算非线性函数。
衍生变量就是对户现有变量做组合加工,从而生成一个新的变量。通过计算出这个新变量与其它变量的线性关系,从而得出非线性函数。
常见的衍生变量构造方法有分箱、相乘、平方、开方、算比例等。
有了衍生变量后,一元二次回归可以看成是对因变量y与自变量x,衍生变量x*x的线性回归。
举例:我们知道功率(W),电压(U),电流(I)之间有一个关系:功率 = 电流 乘以 电压。
现在假设我们不知道这个规律,只是拿到了一组功率,电压,电流的数据。看一下怎么用衍生变量和线性回归的方法来发现这个规律。
原始数据如下:
| U | I | W |
|---|---|---|
| 220 | 1 | 220 |
| 220 | 2 | 440 |
| 220 | 6 | 1320 |
| 220 | 6 | 1320 |
| 220 | 8 | 1760 |
| 220 | 2 | 440 |
| 5 | 1 | 5 |
| 5 | 2 | 10 |
| 25 | 0.8 | 20 |
| 25 | 0.6 | 15 |
| 360 | 34 | 12240 |
| 360 | 7 | 2520 |
| 360 | 23 | 8280 |
构造衍生变量后变量(尝试加了电流平方,电压平方,电压乘以电流三个变量)如下:
| U | I | UI | I2 | U2 | W |
|---|---|---|---|---|---|
| 220 | 1 | 220 | 1 | 48400 | 220 |
| 220 | 2 | 440 | 4 | 48400 | 440 |
| 220 | 6 | 1320 | 36 | 48400 | 1320 |
| 220 | 6 | 1320 | 36 | 48400 | 1320 |
| 220 | 8 | 1760 | 64 | 48400 | 1760 |
| 220 | 2 | 440 | 4 | 48400 | 440 |
| 5 | 1 | 5 | 1 | 25 | 5 |
| 5 | 2 | 10 | 4 | 25 | 10 |
| 25 | 0.8 | 20 | 0.64 | 625 | 20 |
| 25 | 0.6 | 15 | 0.36 | 625 | 15 |
| 360 | 34 | 12240 | 1156 | 129600 | 12240 |
| 360 | 7 | 2520 | 49 | 129600 | 2520 |
| 360 | 23 | 8280 | 529 | 129600 | 8280 |
接下来我们使用weka进行线性回归。
weka是一个简易的java语言开发的数据挖掘软件,它提供了界面和API,分别方便普通用户和java程序员进行数据挖掘。在百度学术可以搜索到很多使用weka进行商业数据挖掘的论文(见下图),它的使用简介见后面附录。

将这些数据输入到weka,选择“Classify”(分类)下面的线性回归算法。
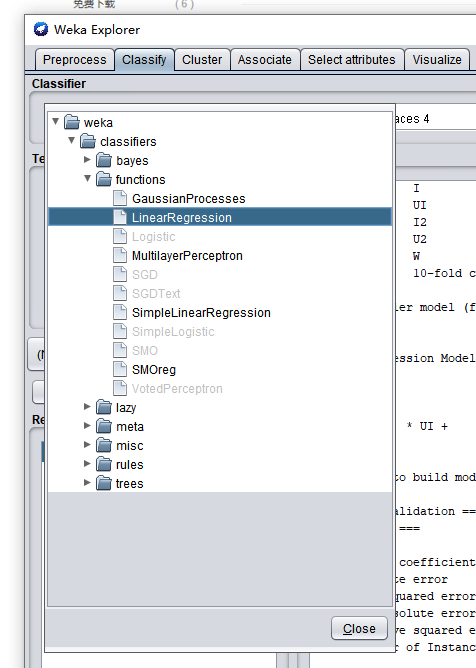
点击执行,程序即输出一个公式
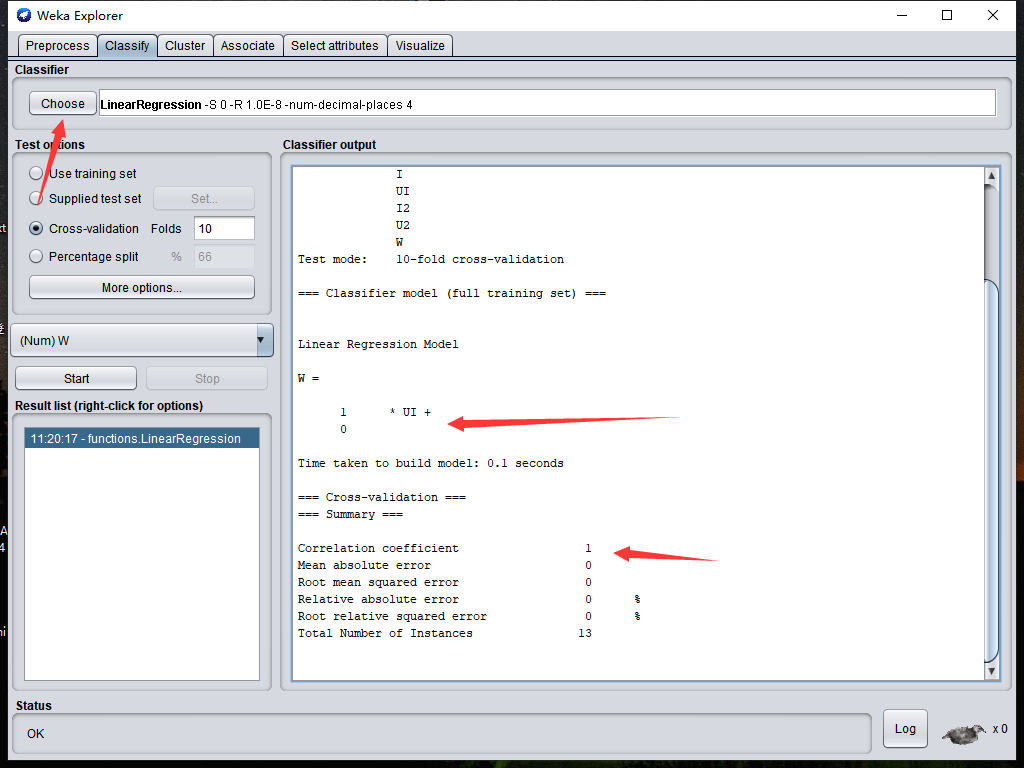
根据这个方程式,我们可以知道功率与衍生变量UI有线性关系。w = 1 * UI
而UI变量我们构造时是使用电压乘以电流。
所以我们发现了功率,电压,电流之间存在关系:功率 = 电流 乘以 电压
知道这个关系后,我们就知道电流跟电压分别对功率的影响。如果后面发现有一些数据,功率与电流和电压之间关系不满足这个方程,那很有可能是数据出了错。
图表相关分析
将数据转换成图表,方便业务人员分析。常见的方法是将数据输出成散点图,并且画出趋势线。

协方差及协方差矩阵

相关系数
相关系数是最早由统计学家卡尔·皮尔逊设计的统计指标,是研究变量之间线性相关程度的量,一般用字母 r 表示。由于研究对象的不同,相关系数有多种定义方式,较为常用的是皮尔逊相关系数。
相关系数是用以反映变量之间相关关系密切程度的统计指标。相关系数是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度;着重研究线性的单相关系数。

实践—使用weka分析影响房产价格因素
https://blog.csdn.net/Shellerine/article/details/53200500?utm_source=blogxgwz4
https://blog.csdn.net/kestory/article/details/90521981


数值数据处理技巧
标准化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。
归一化
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为标量。 在多种计算中都经常用到这种方法。 例如将身高和体重都归一成比例小数数据。
缺失值
实际生产中业务数据往往有缺失,此时我们需要通过各种算法补齐缺失值。例如取众数,取平均值,取近邻值等。
非数值数据处理技巧
有序类别
一些有序的类别高中低,胖瘦,可以直接使用数字代替。
无序类别(使用哑变量,即虚拟变量)
没有大小关系的类别,例如东南西北,男人女人,可以使用哑变量处理。
文本数据
有时候模型的输入是文本数据,例如新闻,社交媒体。我们需要把文本转化为数值矩阵。
有时候模型的输入是文本数据,例如新闻,社交媒体发言等,需要把文本转化为数值矩阵。
常用处理方法有两种:
单词统计(word counts): 统计每个单词出现的次数。
TF-IDF(Term Frequency-Inverse Document Frequency): 统计单词出现的“频率”。
网上有通过数据挖掘分析红楼梦作者的例子,有兴趣的同学可以自行百度。
关联分析
定义与应用场景
关联分析是一种简单、实用的分析技术,就是发现存在于大量数据集中的关联性或相关性,从而描述了一个事物中某些属性同时出现的规律和模式。
关联分析是从大量数据中发现项集之间有趣的关联和相关联系。
关联分析的一个典型例子是购物篮分析。该过程通过发现顾客放入其购物篮中的不同商品之间的联系,分析顾客的购买习惯。通过了解哪些商品频繁地被顾客同时购买,这种关联的发现可以帮助零售商制定营销策略。其他的应用还包括价目表设计、商品促销、商品的排放和基于购买模式的顾客划分。
可从数据库中关联分析出形如“由于某些事件的发生而引起另外一些事件的发生”之类的规则。如“67%的顾客在购买啤酒的同时也会购买尿布”,因此通过合理的啤酒和尿布的货架摆放或捆绑销售可提高超市的服务质量和效益。又如“‘C语言’课程优秀的同学,在学习‘数据结构’时为优秀的可能性达88%”,那么就可以通过强化“C语言”的学习来提高教学效果。
常用算法
穷举法
穷举法不是业务常用的算法,只是我觉得使用穷举的方法来解决“购物篮问题”,比较直观,对于理解其它算法也有帮助,所以把它列出来。
举个例子,假设我们经营一家小超市,里面提供了以下几种商品:面包,牛奶,奶粉,尿布,可乐,鸡蛋。我们想分析一下顾客的购物清单,看里面是否有高关联度的商品。
那我们可以先对商品组合做穷举(例如面包和牛奶,面包和奶粉,面包和尿布,面包和牛奶及鸡蛋等),并分别计算出同时购买了该商品组合的清单数量。
例如我们可能会得出以下数据:
| 商品组合 | 清单数量 | 占比 |
|---|---|---|
| 面包 | 10 | 有购买面包的清单数量/总数量 |
| 面包和牛奶 | 6 | 6 / 10 |
| 面包和尿布 | 3 | 3 / 10 |
| 面包和奶粉 | 0 | 0 / 10 |
| 面包和牛奶及鸡蛋 | 3 | 3 / 6 |
(数据是我为说明算法随手造的,勿当真)
从这个表格数据我们可以分析得出结论:购买了面包的人,有60%机率会同时买牛奶,但只有30%的人会同时买尿布。同时购买了面包和牛奶的人中,有50%的人会再买鸡蛋。
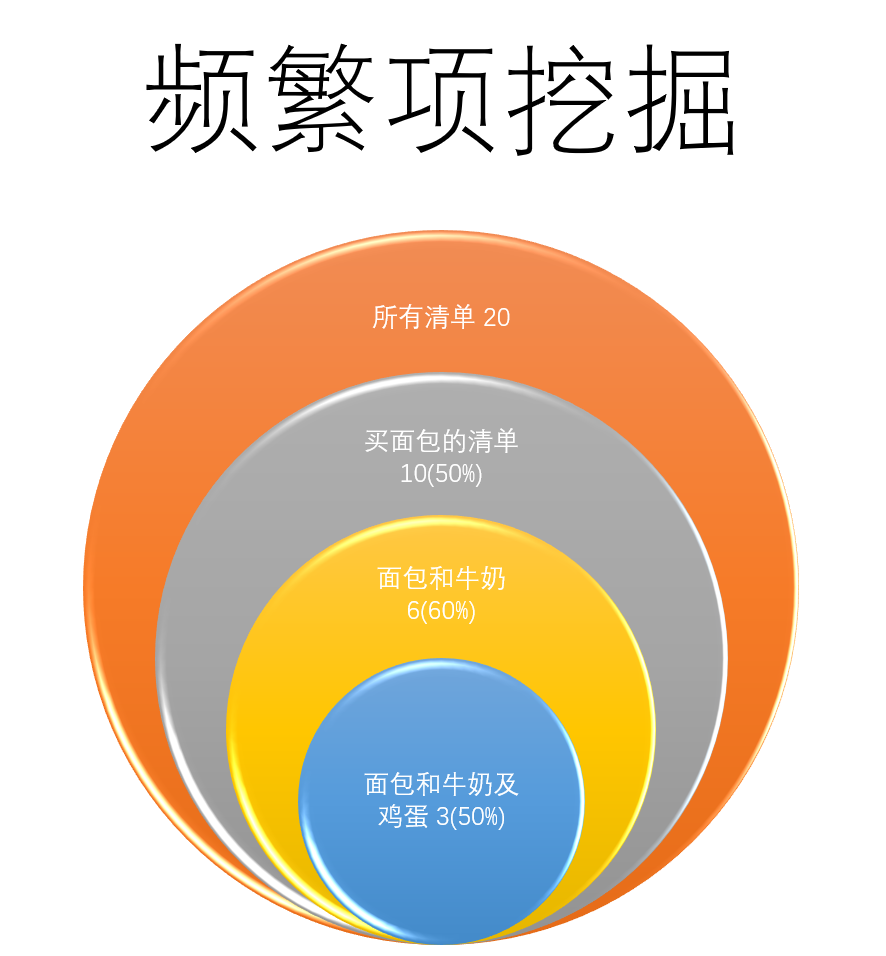
所以我们如果要做促销,那把面包,牛奶,鸡蛋打包成一个商品打折,可能会取到不错的效果。
Apriori(先验)算法
在穷举法的基础上,提出了根据截枝,大大减少组合计算次数,加快计算速度。(举例:如果买牛奶面包的商品人很少,那就不需要统计同时购买了牛奶面包可乐的人有多少,因为没有意义。)
GSP算法
在Apriori算法,增加考虑频繁项顺序。可用于时序(有先后顺序的)频繁项挖掘。
SPADE算法
我也没搞懂。
实践—使用weka发现总是一起出现的彩票号码组合
经常研究彩票的彩民,可以会发现一些号码经常一起出现。(例如出现2同时出现5概率比较高)找出这些组合,有利于提高中奖机率。但由于彩票开奖数据比较大,想找出这些号码组合比较困难。我们可以使用数据挖掘的关联分析算法来解决此类问题。
这里我们使用weka提供的Apriori(中文意思,先验的,推测的)算法进行数据挖掘。
我从福利彩票网站抓取了最近100期的彩票记录数据,处理了一下,转换成Apriori算法需要的矩阵并使用它分析里面是否有频繁项。
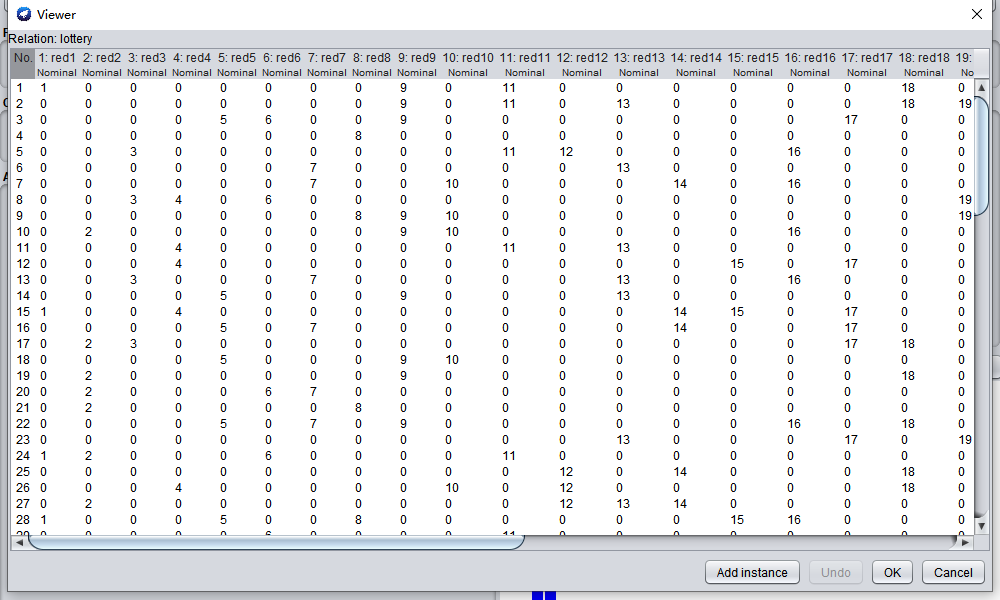
出现概率超过3%,并且支持度超过70%
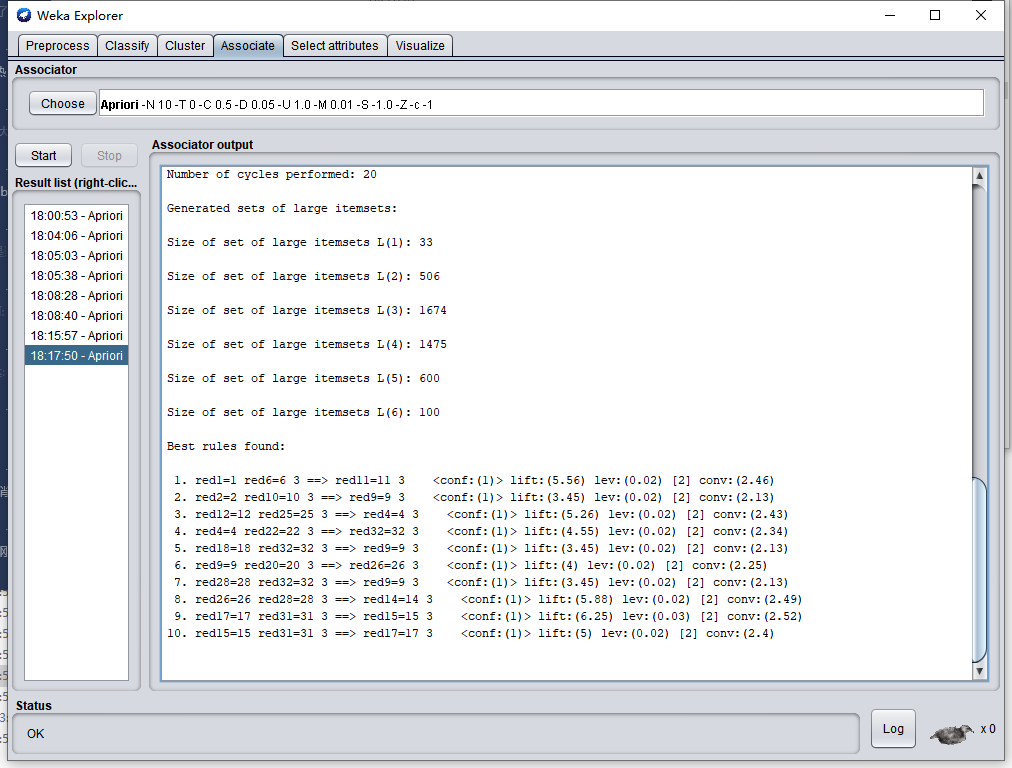
结果说明:过去100期双色球开奖结果中,1、6、11同时出现的次数是3次,并且每次出现1和6的时候,肯定会出现11, 2、10、9也是同理。我们买彩票时可以根据这个挖掘结果来指导选号,以期提高中奖率。
分类
定义与应用场景
分类是基于包含其类别成员资格已知的观察(或实例)的训练数据集来识别新观察所属的一组类别(子群体)中的哪一个的问题。例如,将给定的电子邮件分配给“垃圾邮件”或“非垃圾邮件”类,并根据观察到的患者特征(性别,血压,某些症状的存在或不存在等)为给定患者分配诊断。分类分析,简单地说就是把数据分成不同类别。
分类算法一般使用机器学习里面属性有监督学习算法,即需要输入一些样本,根据样本确定算法参数,从而生成一个适合业务的算法模型。
常用算法
k最近邻分类(即KNN)
有句话说:“想知道自己是什么样的人,那看看自己经常交往的十个人就知道”。KNN分类的原理就是这样,通过观察与新数据距离最近的N个数据的分类标签,数量最多的标签就是新数据的分类。(N需要根据业务人员经验确定,不宜太大)
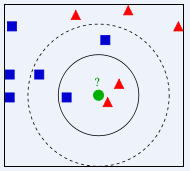
例如以下图:圆圈是新数据,假设规定根据与它最相邻的3个数据来分类,因为其中两个是三角形,一个是正方形,则会认为该数据是三角形。
当N值取5时,最近的5个数据里面有3个是正方形,2个是三角形,则新数据会被认为是正方形。
距离:
数据挖掘有一个的重要概念,就是数据距离:就是。如果是单维数据,要确定距离十分方便,例如有三个人体身高数据,分别是1.6、1.7、1.8,那这三个数据相互的距离直接用数据值相减就可以计算出来。
但我们实际业务数据经常是有多种维度的,例如有三个西瓜,它们数据如下:
| 甜度 | 重量 | 体积 |
|---|---|---|
| 0.8 | 1kg | 8 |
| 0.7 | 1.5kg | 5 |
| 0.5 | 2kg | 12 |
所以我们一般需要使用距离公式来评判数据距离。选择不同公式对分类结果可能产生不同影响。需要根据实际业务需要选择。
常见距离公式有:
欧式距离:
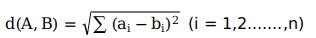
余弦距离:
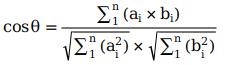
马氏距离:
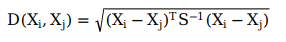
杰卡德距离:
独热编码:
如果数据不是数值型,而是标签型,例如西瓜产地有本地,新疆,云南,西瓜颜色有红色、蓝色、绿色。则需要独热编码对数据进行处理。
决策树
决策树分类是用属性值对样本集逐级划分,直到一个节点仅含有同一类的样本为止。
决策树算法的模型最直观,最易于解释,甚至可以做为普通业务人员指导。下图是判断一个瓜是好瓜还是坏瓜的决策树,其判断过程十分接近人类思维。
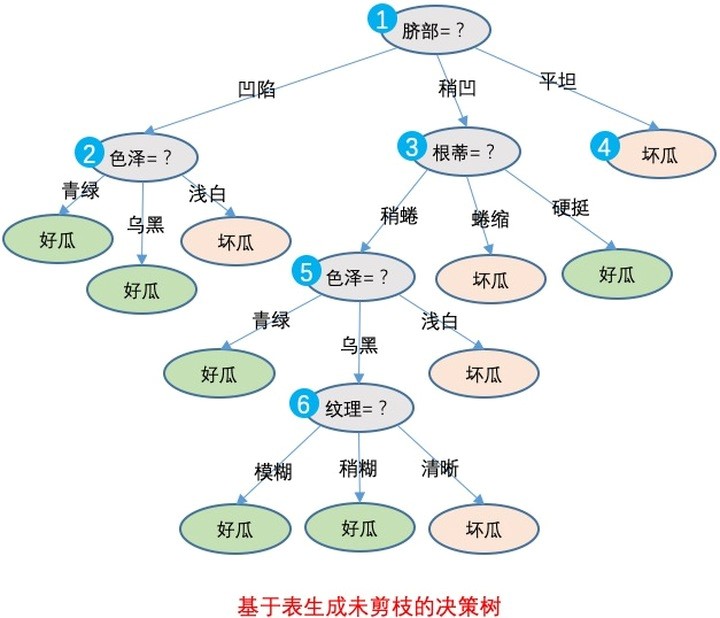
图:使用C45算法生成的决策树
神经网络
神经网络可以认为是大量复杂的算法单元,利用仿生学知识,模拟人类神经传导机制连接起来形成的一种算法。每个算法单元里面有很多不同参数。通过调整参数,可以处理任意分类问题。我们平常总是听到的训练模型,就是在给这些算法单元找合适的参数。
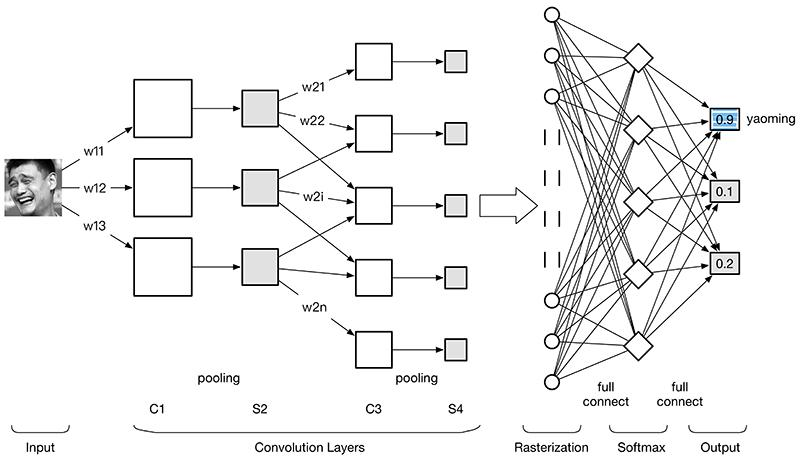
图:使用神经网络识别图像
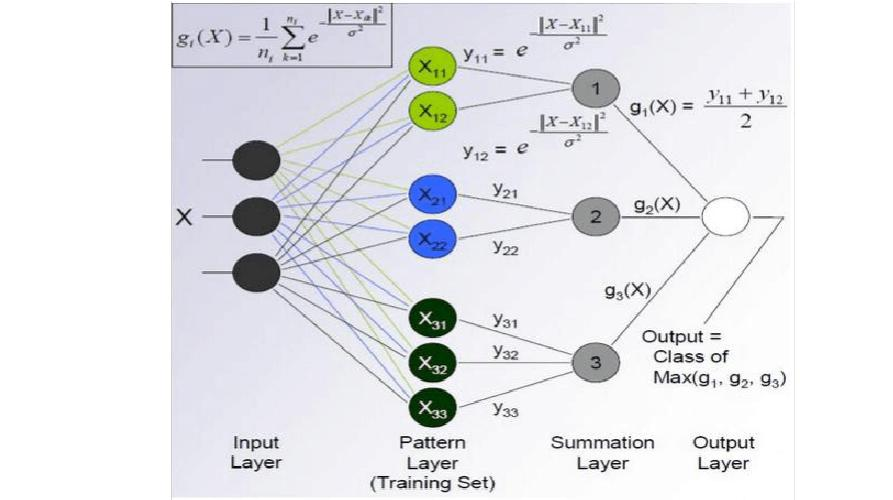
图:使用神经网络实现公式计算
如果神经网络里面的感知器使用的算法是线性算法(类似前面介绍的多元线性回归),则称为线性神经网络,如果使用了卷积算法,则称为卷积神经网络。
阿尔法狗就是使用卷积神经网络的分类应用,它把棋盘当成一个19*19的图像,把下子当成一个分类问题,即输入现在棋盘图像,输出一个与人类高手下子后最接近的棋盘图像。(当然,它还加了其它辅助算法,例如蒙特卡洛树搜索树提高赢棋概率)
贝叶斯分类
支持向量机分类(Support Vector Machine, SVM)
将数据映射到高维度,并寻找一个高维平面将数据分割开来
逻辑回归(logistic回归)
在线性回归的基础上,使用函数将连续输出转换成离散输出
实践—使用weka鉴别病人是否得了糖尿病
这里我们使用weka自带的疑似糖尿病人身体指标数据和检测结果做为训练数据,使用决策树分类算法randomtree来训练模型并用于根据新的病人身体指标预测其是否患糖尿病。
训练数据在data/diabetes.arff这个文件里面,我简单介绍一下:
文件里面包含了一些病人身体指标,例如怀孕次数(preg),饭后2小时血糖浓度(plas),年龄(age)等。对于每个病例,最后都会标记检测结果为阴性或者阳性(tested_negative/ tested_positive),如果为阳性说明得了糖尿病。

我们先使用weka导入这个文件并在Classify这个界面,点击“choose”按钮,选择算法“RandomForest”
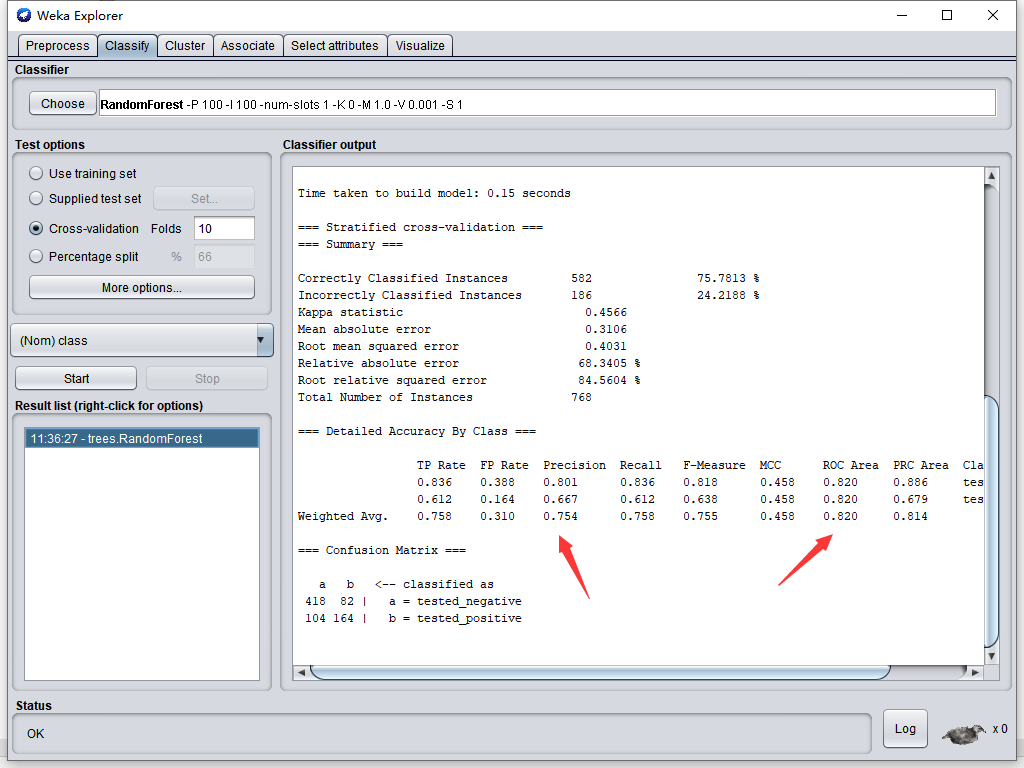
点击"Start",训练出模型。从输出看,模型分类准确率有75%,效果勉强还行(50%即代表瞎猜的)
接着准备测试文件,将data/diabetes.arff复制一份,变成diabetes - test.arff
只保留前两行,并把分类结果改为?,我们用这个来做为测试数据,看模型是否能正确分出结果(实际工作时不应该拿模型数据,而是拿实际未打标数据)
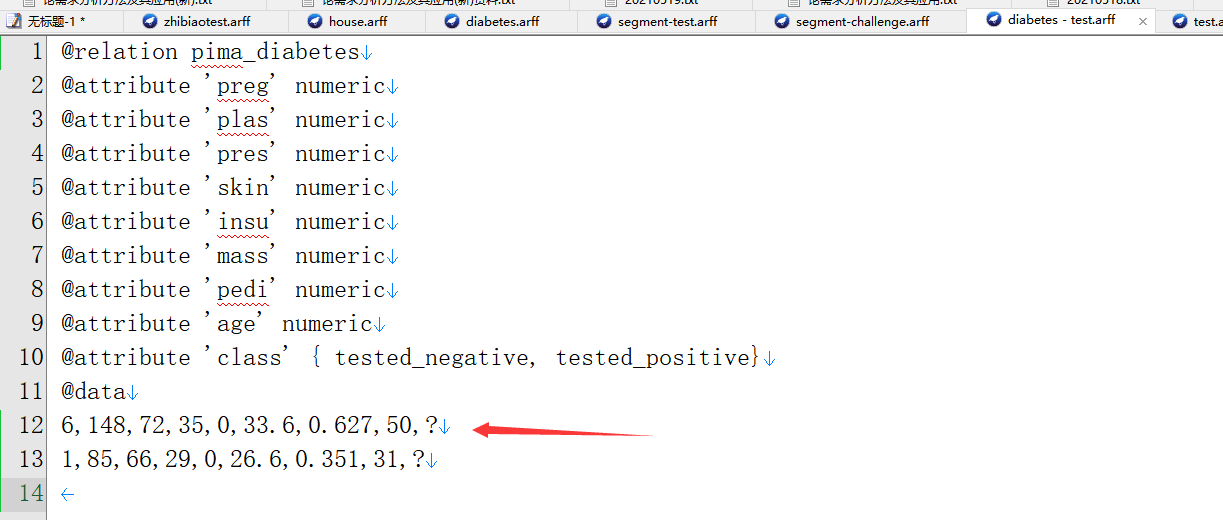
点击"Set…"按钮,选择diabetes - test.arff做为测试集。
在ResultList窗口列表项右击,执行
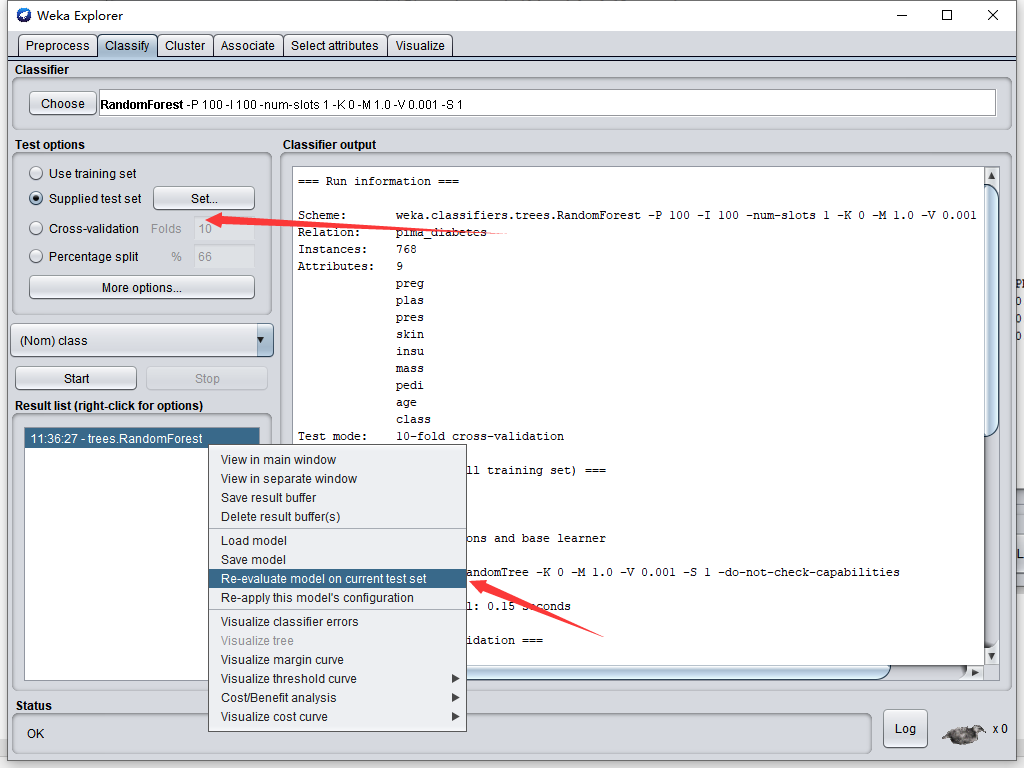
运行后输出界面会刷新,此时再右击Result List窗口
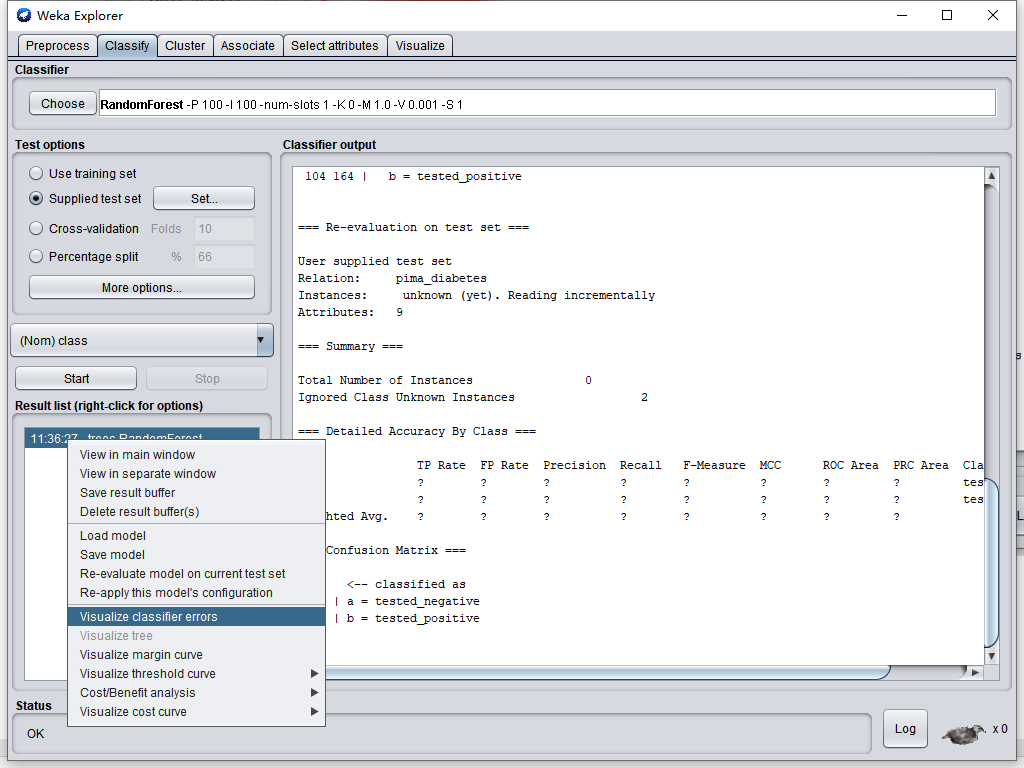
选择Save,将文件保存为
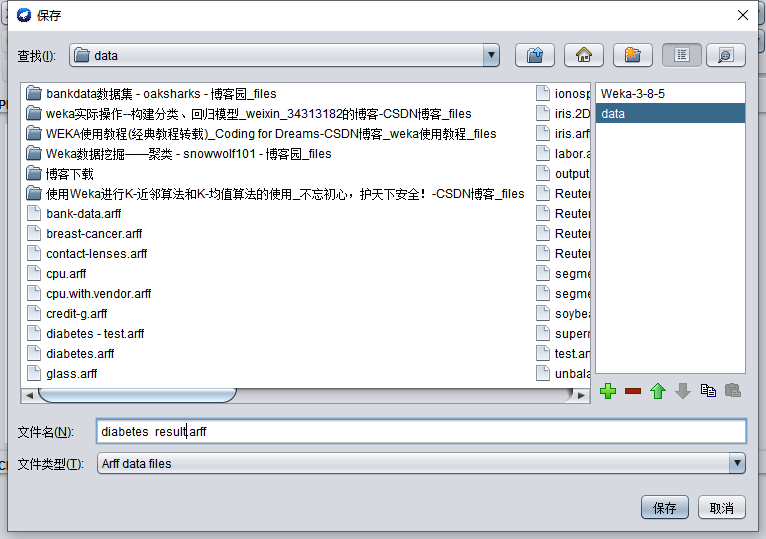
打开文件,会发现结果多了两列,最右边一列是模型分类结果。符合我们预期,一个阳性一个阴性。

聚类
定义与应用场景
聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。
聚类算法一般使用机器学习里面的非监督学习算法。
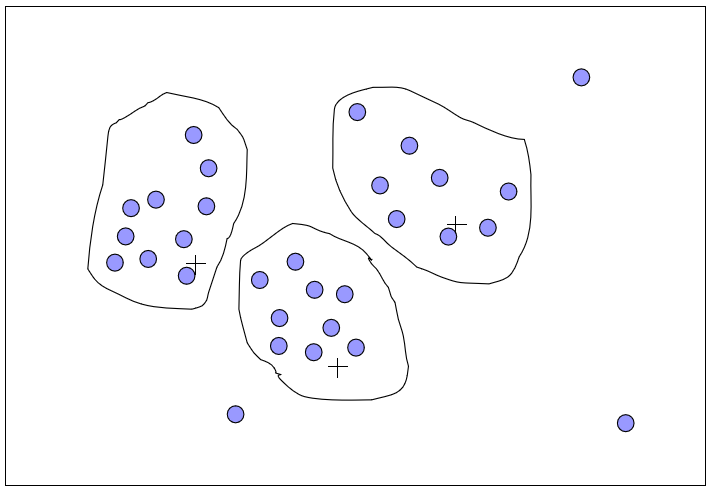
常用算法
随机森林
使用多个弱分类算法组合成一个强分类算法。(类似于民主投票,选谁适合当总统)
孤立森林
孤立森林算法是周志华教授(机器学习经典--西瓜书的作者)提出来的,用于发现异常数据的算法。
使用随机方法将数据集进行多轮切分,在多轮切分中,经常在比较早完全分离出来的数据则认为是异常数据。
下面是一个使用孤立森林算法来发现图片中异常的树木的例子:

第1轮切分,第1次就发现了特别样例。(上方图片只有一棵树,无法再分割)

第二轮切分,第2次就发现了特别样例。(第一次切分出来的图片上下两部分都有树,第二次分出来的4个图片区域,有一块只有一棵树)
这棵“树”实在太奇怪了,导致它总是能很快地跟其它树分离开来。实际上,它是联通的5G基站,伪装成树型,方便部署。
k-均值(k-means)
寻找k个中心点,将离中心点最近的数据归到一类。跟KNN有点像,特别依赖数据距离公式。
EM最大期望算法
DBSCAN
根据数据密度来划分数据。

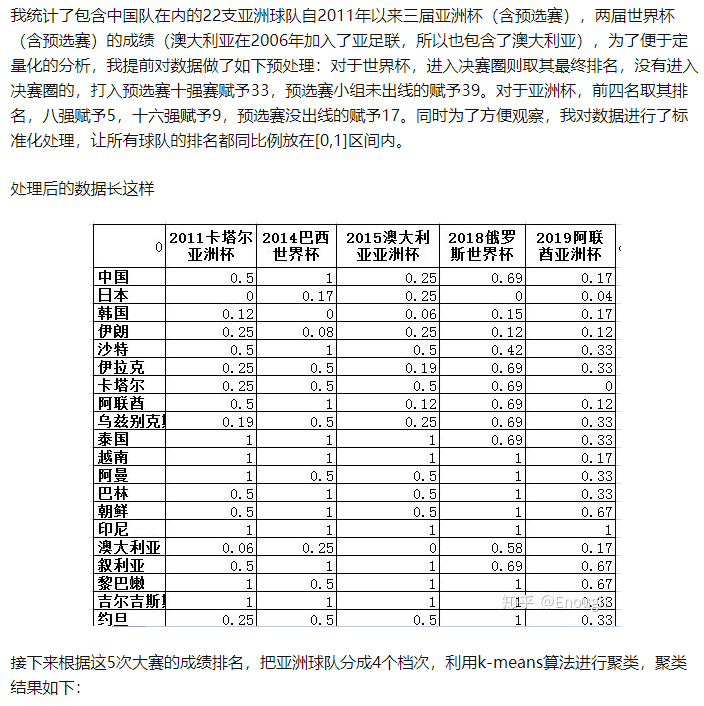
实践—使用kmeans分析中国足球队是亚洲几流球队
https://zhuanlan.zhihu.com/p/62535727 我分析了过去十年五届大赛的成绩,中国男足到底是亚洲几流?

聚类和分类区别联系
聚类分析跟分类分析区别是分类分析需要有已有标签的数据,而聚类分析则不需要。
实践中经常先使用聚类对数据进行探索,之后对有价值的数据开发分类模型用于商业应用。
时序分析
定义与应用场景
时间序列是一系列数据点,使用时间戳进行排序。例如水果的每日价格到电路提供的电压输出的读数,股票每分钟报价等。
虽然在某一给定时刻预测目标的观测值是随机的,但从整个观测序列看,却呈现出某种随机过程(如平稳随机过程)的特性。
随机时间序列方法正是依据这一规律性来建立和估计产生实际序列的随机过程的模型,然后用这些模型进行预测未来数据。
像气温,股票,客流等这些时序数据都适合用时序序列预测技术。
例如我们公司做的动态阈值组件就使用了时序分析的技术
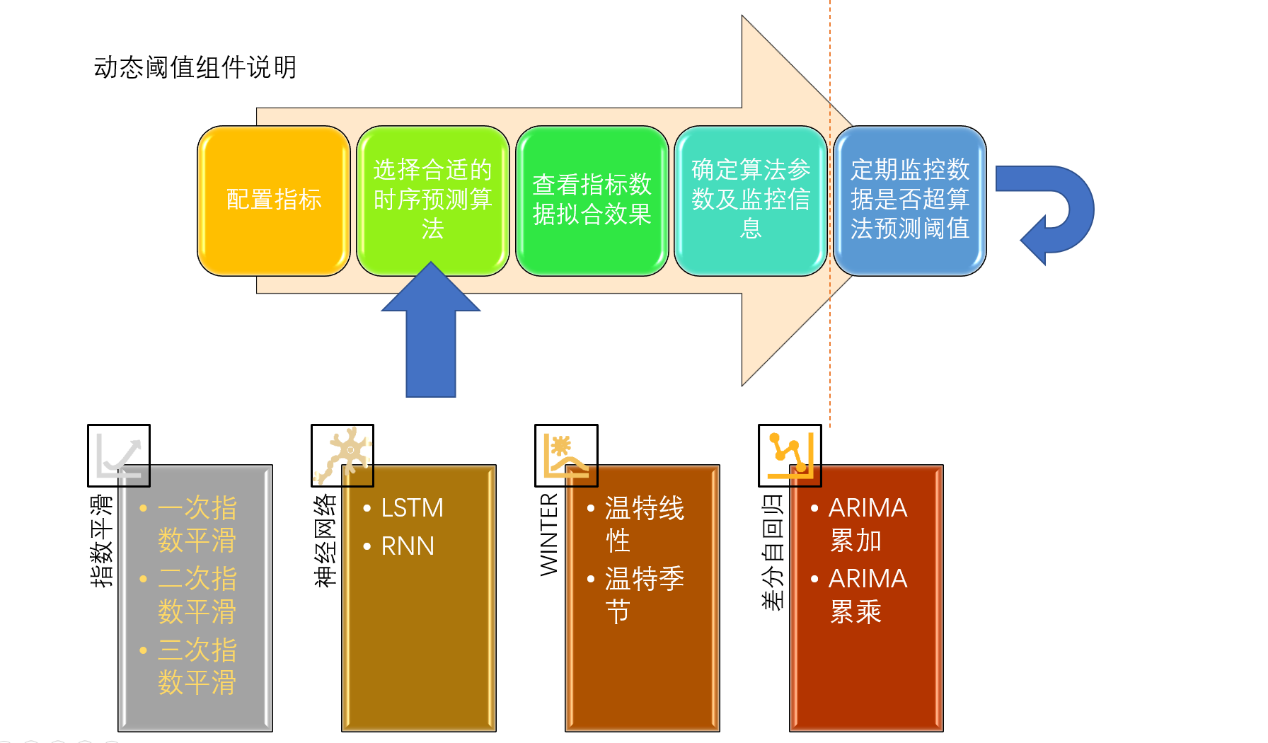
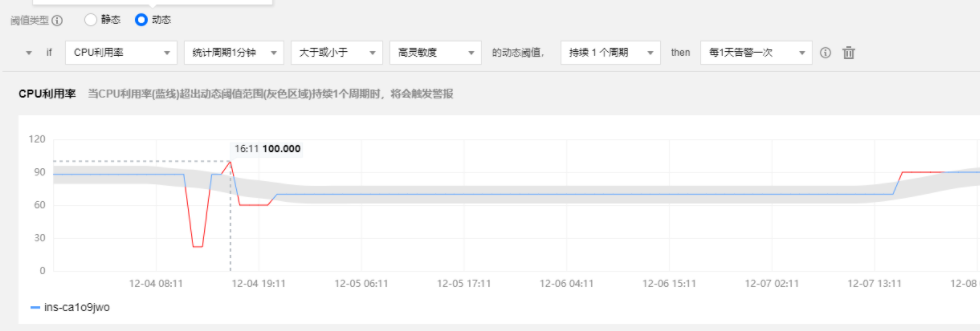
图:通过时序分析模型结合历史数据预测出当前时刻数据上下限,超出阈值的数据认为是异常数据,触发告警。
常用算法:
指数平滑
温特霍特曲线
移动差分自回归
神经网络(RNN和LSTM)
RNN和LSTM是深度学习神经网络算法,深度意思是有多个中间层。
小结练习
1 请分析文章开始的数据挖掘案例,分别使用的是哪种数据挖掘方法
| 案例 | 使用技术 |
|---|---|
| 沃尔玛通过数据挖掘发现啤酒与尿布销售关系 | 关联分析 |
| 某打车平台通过大数据发现司机与乘客私下交易 | |
| 某购物平台使用数据挖掘提高优惠券营销能力 | |
| 某微博网友质疑天猫双十一销售额数据造假 | |
| 某人使用yolo3辅助自己整理照片 |
2 使用今天学习的数据挖掘知识,开发一款类似今日头条的信息流软件,实现高准确率信息推荐
一点鸡汤:
数据挖掘的场景多种多样,但核心的挖掘算法却相对有限。这跟我们以前学的数学,物理有点类似,很多题目看起来十分复杂,但都是通过一些基本的定理,定律可以解决。其实在职场中,想做好工作,也有类似这样的“定理”,“定律”这样的东西。例如《高效能人士的七个习惯》里面提到的:主动积极、以终为始、要事第一、双赢思维、知彼知己、统合综效、不断更新。
说明:
本文大部分资料抄自网上,我自己做了点加工整理,仅供学习交流用。由于来源太多,并且资料整理时间太长,无法一一注明,请作者见谅。欢迎转载,如果有侵权地方请联系我修改。
数据挖掘的知识范围很广,本文虽然只是介绍了入门知识,但限于作者水平,文章中难免出现有错漏地方,欢迎各位留言指正。
数据挖掘在网上资料非常丰富,如果各位对本文介绍的知识有兴趣,可以到百度输入关键字,查找相关资料。
这里介绍几个:
数据挖掘技术及应用(我见过的最全面的理论+最佳案.ppt
数据挖掘技术在电网企业中的应用需求分析.pdf
基于数据挖掘的电力设备状态检修技术研究综述.doc
面向智能电网大数据的数据挖掘算法概述.pdf
数据挖掘技术及其在电力系统中的应用.pdf
电力行业数据挖掘.pptx
不过学技术,关键不在于掌握资料的多与少,而在于你是否去运用它。希望大家在个平时生活中多想一下,哪些例子是使用了数据挖掘,自己能用数据挖掘来解决什么问题。
附录1:练习题答案
1
| 案例 | 使用技术 |
|---|---|
| 沃尔玛通过数据挖掘发现啤酒与尿布销售关系 | 关联分析 |
| 某打车平台通过大数据发现司机与乘客私下交易 | 关联分析 |
| 某购物平台使用数据挖掘提高优惠券营销能力 | 聚类 |
| 某微博网友质疑天猫双十一销售额数据造假 | 相关性分析 |
| 某人使用yolo3辅助自己整理照片 | 分类 |
2
网上还有很多练习题,涉及到了很多知识点(不包括本文介绍的):
数据挖掘150道试题 测测你的专业能力过关吗?
附录2:weka使用
WEKA数据挖掘工具操作实验.ppt
https://max.book118.com/html/2017/0127/87028147.shtm
WEKA使用教程
https://blog.csdn.net/yangliuy/article/details/7589306
CC中英字幕 - Weka在数据挖掘中的运用(Data Mining with Weka)
https://www.bilibili.com/video/BV1Hb411q7Bf?from=search&seid=17226336668903912022

 浙公网安备 33010602011771号
浙公网安备 33010602011771号