使用ai的方法给epub文件中的汉字加拼音
前言
方便小孩阅读,对epub文件加拼音。
使用ai的方法解决多音字问题。
方法
使用python中调用ai的方法。
(1)Python环境的安装,这里直接安装python3.0以上:
https://www.python.org/downloads/windows/
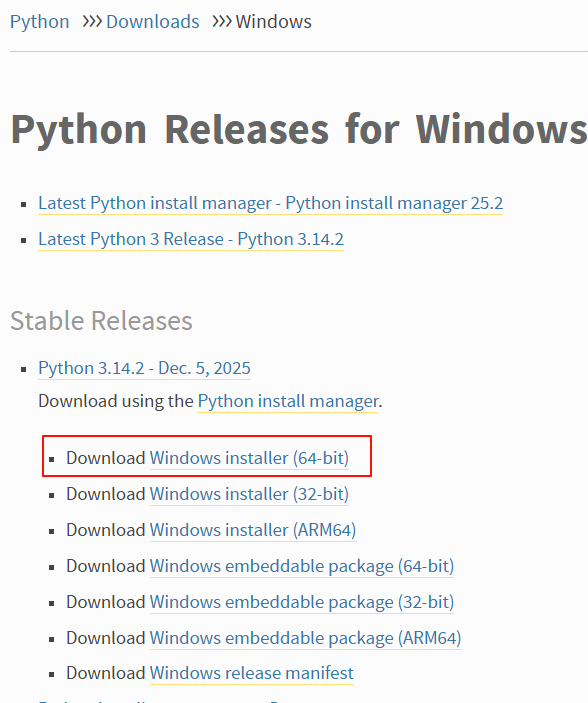
安装时需要打勾添加进系统环境变量。
在cmd中确认是否安装完毕:出现下述界面表示python环境部署完毕。
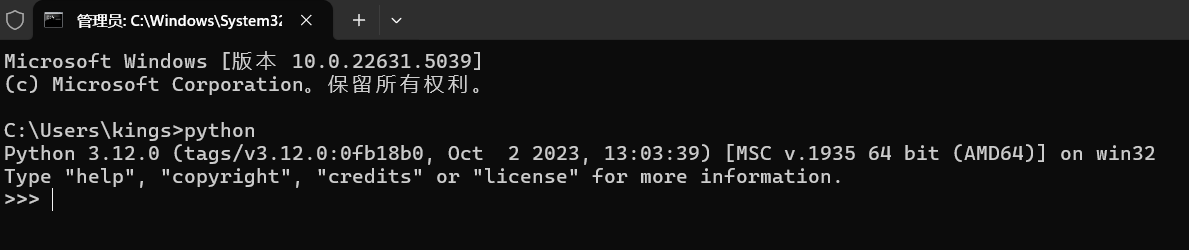
(2)安装相关的库:
> pip install openai ebooklib bs4 pypinyin
(3)在文件夹下增加此代码文件add_pinyin_doubao.py,内容如下:
# -*- coding: utf-8 -*-
# add_pinyin_doubao.py —— 2025-12-07 终极无敌永不崩溃版
# 豆包一键加注音神器,10万字小说 25~35 秒出书,兼容一切 EPUB!
import os
import re
import time
import threading
import uuid
from concurrent.futures import ThreadPoolExecutor, as_completed
from openai import OpenAI
from ebooklib import epub
from bs4 import BeautifulSoup
from pypinyin import pinyin, Style
# ====================== 配置区 ======================
os.environ["ARK_API_KEY"] = "" # ← 填你的豆包 Key!
# 一键切换模型(改这一行就行)
MODEL_NAME = "doubao-1-5-pro-32k-250115" # Pro:最准
# MODEL_NAME = "doubao-seed-1-6-flash-250828" # Seed:最快最省(推荐)
# MODEL_NAME = "doubao-seed-1-6-lite-250828" # 最便宜
MAX_WORKERS = 128
API_CONCURRENCY = 256
API_RETRY = 3
SLEEP_AFTER_API = 0.06
# ====================================================
client = OpenAI(
base_url="https://ark.cn-beijing.volces.com/api/v3",
api_key=os.environ.get("ARK_API_KEY"),
timeout=60
)
PROMPT = """请把下面这段话转换成纯拼音(头顶带声调符号),一个汉字严格对应一个拼音,用空格隔开。
不要出现任何标点符号,轻声写原音节(如吗→ma),ü 一定要带点:ǖǘǚǜ
例如:
我叫李华,住在“长寿桥”。
→ wǒ jiào lǐ huá zhù zài cháng shòu qiáo
现在转换:
{text}"""
api_sema = threading.Semaphore(API_CONCURRENCY)
PINYIN_RE = re.compile(r'[āáǎàōóǒòēéěèīíǐìūúǔùǖǘǚǜüa-zA-Z]+')
PUNCT_CHARS = r'''!"#$%&\'()*+,-./:;<=>?@[\]^_`{|}~,。!?;:、“”‘’()【】《》'''
punctuation_pattern = f'[{re.escape(PUNCT_CHARS)}]'
def num2tone(s):
tone_map = {'a': 'āáǎà', 'o': 'ōóǒò', 'e': 'ēéěè', 'i': 'īíǐì', 'u': 'ūúǔù', 'ü': 'ǖǘǚǜ'}
s = s.replace('v', 'ü')
m = re.match(r'^([a-zü]+)(\d)$', s, re.I)
if not m:
return s
base, tone = m.group(1).lower(), int(m.group(2))
for ch in 'aoeiuü':
if ch in base:
return base.replace(ch, tone_map[ch][tone - 1] if tone <= 4 else ch)
return base
def local_pinyin_fallback(text: str):
raw = pinyin(text, style=Style.TONE3, heteronym=False, errors='ignore')
return [num2tone(item[0]) if item else '' for item in raw]
def api_get_pinyin_list(text):
for attempt in range(1, API_RETRY + 1):
if not api_sema.acquire(timeout=60):
return local_pinyin_fallback(text)
try:
resp = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": PROMPT.format(text=text)}],
temperature=0.0,
max_tokens=4096
)
raw = resp.choices[0].message.content.strip()
lst = PINYIN_RE.findall(raw.lower())
lst = [p.replace('v', 'ü') for p in lst]
time.sleep(SLEEP_AFTER_API)
return lst
except Exception as e:
print(f"\n[第{attempt}次] API调用失败: {e}")
if attempt == API_RETRY:
print("→ 改用本地pypinyin兜底")
return local_pinyin_fallback(text)
time.sleep(2 ** (attempt - 1))
finally:
api_sema.release()
return []
def text_to_ruby_local(text: str) -> str:
chinese_chars = [c for c in text if '\u4e00' <= c <= '\u9fff']
if not chinese_chars:
return text
marks = []
clean_text = re.sub(punctuation_pattern, lambda m: (marks.append(m.group()), "__MARK__")[1], text)
py_list = api_get_pinyin_list(clean_text)
if len(py_list) != len(chinese_chars):
py_list = local_pinyin_fallback(clean_text)
result = []
py_idx = 0
i = 0
while i < len(text):
ch = text[i]
if re.match(punctuation_pattern, ch):
result.append(ch)
elif '\u4e00' <= ch <= '\u9fff':
py = py_list[py_idx] if py_idx < len(py_list) else ''
result.append(f"<ruby><rb>{ch}</rb><rt>{py}</rt></ruby>")
py_idx += 1
else:
result.append(ch)
i += 1
return ''.join(result)
def is_html_item(item):
return (hasattr(epub, 'ITEM_DOCUMENT') and item.get_type() == epub.ITEM_DOCUMENT) or \
getattr(item, 'media_type', '').startswith('application/xhtml+xml')
# ====================== 永久解决所有 write_epub 崩溃的核心函数 ======================
def fix_epub_before_write(book):
"""彻底解决 uid/None/ncx/Chapter 等所有历史遗留崩溃问题"""
# 1. 修复所有 item 的 uid 和 file_name
for item in book.get_items():
if not getattr(item, 'uid', None):
item.uid = str(uuid.uuid4())
if not getattr(item, 'file_name', None):
item.file_name = f"{item.uid}.xhtml"
# 2. 递归修复 TOC(只认 Section 和 Link!)
def walk_toc(items):
if not items:
return
for item in items:
if isinstance(item, epub.Section):
if not getattr(item, 'uid', None):
item.uid = str(uuid.uuid4())
elif isinstance(item, epub.Link):
if not getattr(item, 'uid', None):
item.uid = str(uuid.uuid4())
elif isinstance(item, tuple) and len(item) >= 1:
walk_toc([item[0]])
if len(item) > 1:
walk_toc(item[1:])
elif hasattr(item, '__iter__') and not isinstance(item, str):
walk_toc(item)
walk_toc(book.toc)
# 3. 终极保险:禁用老旧 ncx(现代阅读器全靠 nav.xhtml)
try:
book.set_option('no_ncx', True)
except:
pass # 老版本 ebooklib 没有这个选项,直接忽略
def main():
print("豆包拼音添加器 2025.12 终极无敌永不崩溃版 启动!")
epubs = [f for f in os.listdir('.') if f.lower().endswith('.epub') and '_终极拼音' not in f]
if not epubs:
print("没找到epub文件,请把小说epub拖到这个文件夹")
input("回车退出...")
return
src = epubs[0]
dst = src.replace('.epub', '_终极拼音.epub')
print(f"使用模型:{MODEL_NAME}")
print(f"处理:{src} → {dst}")
book = epub.read_epub(src)
entries = []
item_map = {}
for item in book.get_items():
if not is_html_item(item):
continue
href = getattr(item, 'file_name', f"item_{id(item)}.xhtml")
item_map[href] = item
soup = BeautifulSoup(item.get_content(), 'html.parser')
for idx, p_tag in enumerate(soup.find_all('p')):
text = p_tag.get_text()
if text.strip():
entries.append((href, idx, text))
total = len(entries)
print(f"发现 {total} 段,开始并行加拼音...")
results = []
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
future_to_info = {executor.submit(text_to_ruby_local, text): (href, idx)
for href, idx, text in entries}
for future in as_completed(future_to_info):
href, idx = future_to_info[future]
try:
ruby_text = future.result()
results.append((href, idx, ruby_text))
except Exception as e:
print(f"\n段落处理异常: {e},保留原文")
results.append((href, idx, text))
print(f"\r进度:{len(results)}/{total} ({len(results)/total*100:.1f}%)", end="")
print("\n\n写回EPUB...")
# 关键修复:永别 uid/ncx 崩溃!
fix_epub_before_write(book)
from collections import defaultdict
grouped = defaultdict(list)
for href, idx, ruby in results:
grouped[href].append((idx, ruby))
for href, items in grouped.items():
item = item_map.get(href)
if not item:
continue
soup = BeautifulSoup(item.get_content(), 'html.parser')
p_tags = soup.find_all('p')
for idx, ruby in sorted(items):
if idx < len(p_tags):
p_tags[idx].clear()
p_tags[idx].append(BeautifulSoup(ruby, 'html.parser'))
item.set_content(str(soup).encode('utf-8'))
epub.write_epub(dst, book)
print(f"\n成功!生成:{dst}")
try:
os.startfile(dst)
print("已自动打开文件,快欣赏你的带拼音神书吧!")
except:
print("请手动打开输出文件查看")
input("\n按回车退出...")
if __name__ == "__main__":
main()
(4)把需要增加拼音的书籍放置在py代码的同级目录:
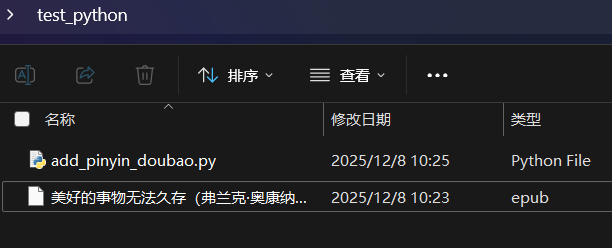
(5)在命令行中执行:
> python .\add_pinyin_doubao.py

等待完成。
结果


Note
注意,拼音的多音字准确性取决于大模型,测试下来,豆包pro,seed系列都是准的,推荐使用doubao-1-5-pro-32k。
deepseek不准,对有些多音字识别有问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号