centos7设置静态ip并连接外网
此教程可能不具有统一性,非放之四海而皆准,谨慎参考,避免骂娘!
打算学习大数据,第一步就是和Linux又打交道了,我们准备了!四台虚拟机分别为hdf-01到hdf-04。
配置思想如下图(我自己配置的ip与图片中的ip并不相同):

1.虚拟机与宿主机的IP设置
打开vmware的编辑下的虚拟网络编辑器
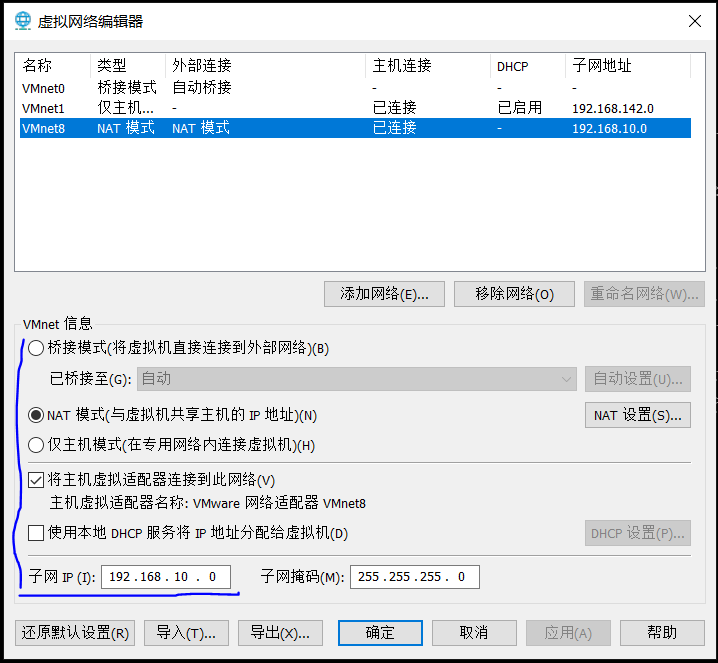
记下子网IP与下图的NAT设置下的网关地址。

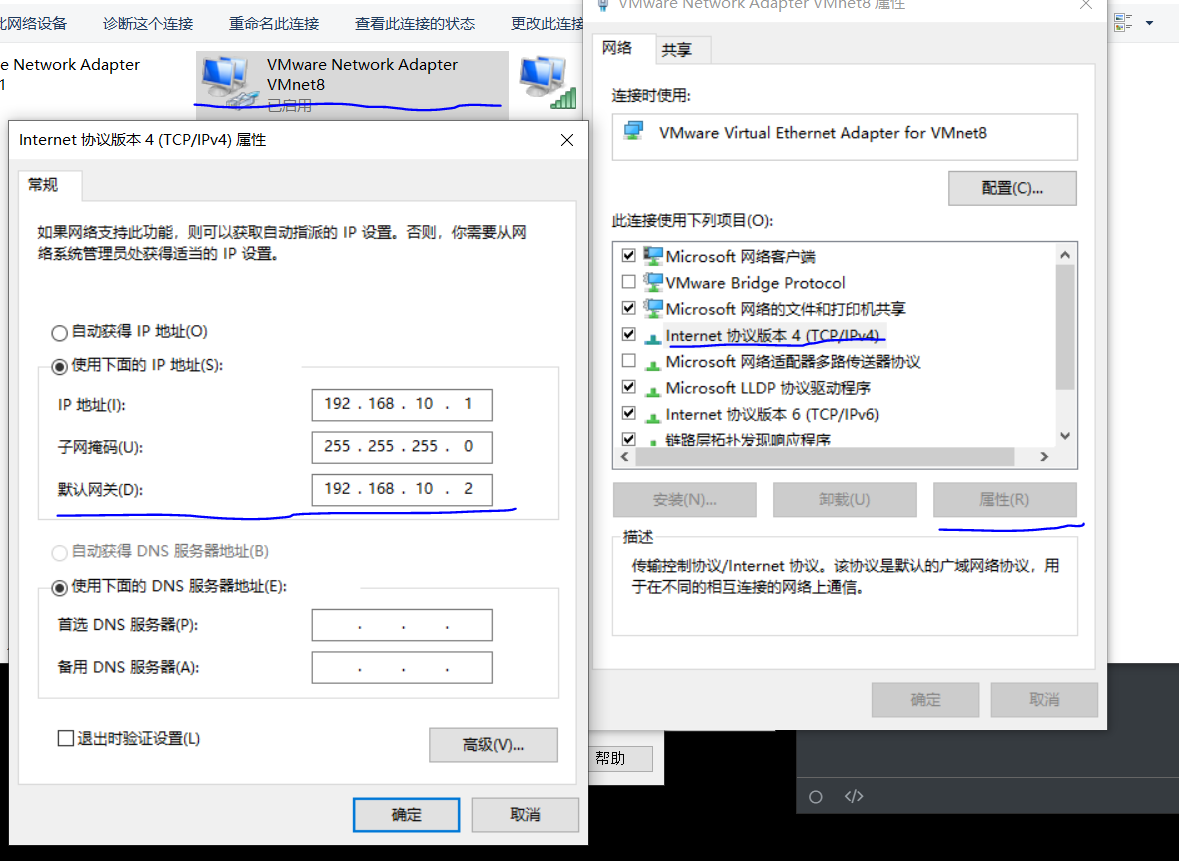
然后打开本机上的网络设置,VMnet8的ipv4属性,设置IP地址。将网关设置与上图的NAT网关相同,IP地址同意网段内随便写,不要重复。
2.对虚拟机的ip设置
打开虚拟机后,进入/etc/sysconfig/network-scripts/,使用 vi 编辑器打开 ifcfg-ens33文件,不同的机器下文件后的数字不尽相同,自己判断。
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static #改为static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=01ad6d15-77de-46d0-9d5f-7143e7c557d4
DEVICE=ens33
ONBOOT=yes # 改为yes,可以自动启动
IPADDR=192.168.10.149 # IP地址改为,与网关同意网段的任意地址(不能重复,不能超过255)
GATEWAY=192.168.10.2 # 网关改成ANT设置中的网关,自己添加的时候一定要注意单词的拼写
NETMASK=255.255.255.0 # 子网掩码,不必多说了
DNS1=8.8.8.8 # DNS写不写都行吧,写上也不费事
DNS2=114.114.114.114
NM_CONTROLLED=no
HWADDR=00:0C:29:D0:5F:CA
这些配置好后,基本上就可以ping通外网了,最后,当前的虚拟机的网络模式要选择好呀!如图

成果

3.scp的使用
多个虚拟机安装软件的时候,比如java运行环境的安装,一个一个的进行安装太过于麻烦,可以安装一个后,使当前的安装好后的文件夹直接贴附于另一台虚拟机下。说干就干,先看安装
yum install openssh-clients # 很简单,一句yes就可以了
我将java的运行环境装在了/apps/jdk8.......,想将这个目录贴于其他主机之上运行下面的代码
scp -r apps/ 192.168.10.146:/ #存放到了根目录下,可以配置host文件映射,使用主机名代替IP地址
4.配置免密登陆
此处的免密登陆是从一台虚拟机到另外的几台虚拟机,是为了hadop启动其他的节点更为方便。首先
ssh-keygen #生成key,之后两次回车即可
此处我在/etc/hosts文件中配置了地址映射,
192.168.10.149 hdf-01
192.168.10.148 hdf-02
192.168.10.147 hdf-03
192.168.10.146 hdf-04
如果没有配置要使用IP地址,然后执行下面命令!
ssh-copy-id hdf-01 #虽然在hdf-01上生成了key,但是也需要在hdf-01上也来一下
..........
ssh-copy-id hdf-04 # 要输入虚拟机登陆的密码
5.安装hadoop集群
在hadoop的安装地址 /apps/hadoop-2.9.2下的etc/hadoop目录中修改hadoop-env.sh
export JAVA_HOME=/apps/jdk1.8.0_241
修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdf-01:9000</value>
</property>
</configuration>
修改hdfs-site.xm
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/dfs/data</value>
</property>
</configuration>
配置环境变量
export JAVA_HOME=/apps/jdk1.8.0_241
export HADOOP_HOME=/apps/hadoop-2.9.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使用scp将hdf-01虚拟机下的hadoop安装到其他机器上
scp -r /apps/hadoop-2.9.2 hdf-02:/apps
......
6.启动HDFS
初始化namenode的元数据目录
在hdf-01上执行命令来初始化元数据存储目录并启动
hadoop namenode -format # 初始化
hadoop-daemon.sh start namenode # 启动namenode进程
然后在windows中用浏览器访问namenode提供的web端口 50070
http://hdf-01:50070 # 需要关闭centos7的防火墙
然后,启动众datanode们(在任意地方)
hadoop-daemon.sh start datanode
7.批量启动脚本来启动HDFS
配置hdf-01到所有集群中所有机器(包括自己)的免密登陆(见上方)
配置完免密,可以执行一次 ssh0.0.0.0
修改hadoop安装目录中 /etc/hadoop/slaves(把需要启动datanode进程的节点列入)
hdf-01
hdf-02
hdf-03
hdf-04
在hdp-01上用脚本:start-dfs.sh 来自动启动整个集群。如果要停止,则用脚本:stop-dfs.sh
8.hdfs常用操作命令
1.上传到hdfs中
hadoop fs -put /本地文件 /aaa
hadoop fs -copyFromLocal /本地文件 /hdfs路径 # copyFromLocal等价于 put
hadoop fs -moveFromLocal /本地文件 /hdfs路径 # 跟copyFromLocal的区别是:从本地移动到hdfs中
2.下载文件到客户端本地磁盘
hadoop fs -get /hdfs中的路径 /本地磁盘目录
hadoop fs -copyToLocal /hdfs中的路径 /本地磁盘路径 ## 跟get等价
hadoop fs -moveToLocal /hdfs路径 /本地路径 ## 从hdfs中移动到本地
3.在hdfs中创建文件夹
hadoop fs -mkdir -p /aaa/xxx
4.移动hdfs中的文件(更名)
hadoop fs -mv /hdfs的路径 /hdfs的另一个路径
5.删除hdfs中文件或者文件夹
hadoop fs -rm -r /aaa
6.修改文件的权限
hadoop fs -chown user:group /aaa
hadoop fs -chmod 700 /aaa
7.追加内容到已存在的文件
hadoop fs -appendToFile /本地文件 /hdfs中的文件
8.显示文本文件的内容
hadoop fs -cat /hdfs中的文件
hadoop fs -tail /hdfs中的文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号