MySQL复制(三)延迟和部分复制
1. 延迟复制
1.1 延迟复制简介
1.1.1 简介
即使通常 MySQL 复制很快,但 MySQL 缺省的复制存在延迟,并且用户无法缩短延迟时间。另一方面,有时却需要特意增加复制的延迟。设想这样一种场景,用户在主库上误删除了一个表,并且该操作很快被复制到从库。当用户发现这个错误时,从库早就完成了该事件重放。此时主库、从库都没有那个被误删的表了,如何恢复?如果有备份,可以幸运地从备份恢复,丢失的数据量取决于备份的新旧和从备份时间点到表被删除时间点之间该表上数据的变化量。如果没有备份呢?这种情况下,延迟复制或许可以帮上忙,作为一种恢复数据的备选方案。如果在发现问题时,从库还没有来得及重放相应的中继日志,那么就有机会在从库获得该表,继而进行恢复。这里忽略一些其它数据恢复方案,例如已经存在类似 Oracle 闪回技术(Flashback)在 MySQL 上的实现,实现方式为解析相应的二进制日志事件,生成反向的 SQL 语句。这些程序多为个人作品,并没有被加入 MySQL 发行版本中,因此在易用性、适用性、可靠性等方面还不能与原生的功能相提并论。
MySQL支持延迟复制,以便从库故意执行比主库晚至少在指定时间间隔的事务。在 MySQL 8.0 中,延迟复制的方法取决于两个时间戳:
immediate_commit_timestamporiginal_commit_timestamp
如果复制拓扑中的所有服务器都运行 MySQL 8.0.1 或更高版本,则使用这些时间戳测量延迟复制。如果从库未使用这些时间戳,则执行 MySQL 5.7 的延迟复制。
复制延迟默认为 0 秒。使用CHANGE MASTER TO MASTER_DELAY = N语句将延迟设置为N秒。从主库接收的事务比主库上的提交至少晚N秒才在从库上执行。每个事务发生延迟(不是以前 MySQL 版本中的事件),实际延迟仅强制在gtid_log_event或anonymous_gtid_log_event事件上。二进制日志中的每个 GTID 事务始终都以Gtid_log_event开头,匿名事务没有分配 GTID,MySQL 确保日志中的每个匿名事务都以Anonymous_gtid_log_event开头。对于事务中的其它事件,不会对它们施加任何等待时间,而是立即执行。
START SLAVE和STOP SLAVE立即生效并忽略任何延迟,RESET SLAVE 将延迟重置为 0。
1.1.2 实验
例如,下面将实验环境中一主两从半同步复制中的一个从库设置为延迟 60 秒复制:
# 继续上一章的实验环境
# 从
mysql> change master to master_delay = 60;
ERROR 3085 (HY000): This operation cannot be performed with a running slave sql thread; run STOP SLAVE SQL_THREAD FOR CHANNEL '' first.
mysql> stop slave sql_thread;
Query OK, 0 rows affected (0.00 sec)
mysql> change master to master_delay = 60;
Query OK, 0 rows affected (0.01 sec)
mysql> start slave sql_thread;
Query OK, 0 rows affected (0.00 sec)
mysql>
联机设置延迟复制时,需要先停止sql_thread线程。现在主库执行一个事务,观察从库的变化:
-- 主
mysql> create table test.t3(a int);
Query OK, 0 rows affected (0.01 sec)
mysql>
-- 从
mysql> desc test.t3;
ERROR 1146 (42S02): Table 'test.t3' doesn't exist
-- 60s后
mysql> desc test.t3;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| a | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
1 row in set (0.00 sec)
mysql>
主库上建立了一个表 test.t3,DDL 语句自成一个事务。60 秒后,从库上才出现该表。从库上performance_schema模式下的replication_applier_configuration.desired_delay表列显示使用master_delay选项配置的延迟,replication_applier_status.remaining_delay表列显示剩余的延迟秒数。
-- 从
mysql> select desired_delay from performance_schema.replication_applier_configuration;
+---------------+
| desired_delay |
+---------------+
| 60 |
+---------------+
1 row in set (0.00 sec)
mysql> select remaining_delay from performance_schema.replication_applier_status;
+-----------------+
| remaining_delay |
+-----------------+
| NULL |
+-----------------+
1 row in set (0.00 sec)
mysql>
-- 主
mysql> drop table test.t3;
Query OK, 0 rows affected (0.02 sec)
mysql>
-- 从
mysql> select remaining_delay from performance_schema.replication_applier_status;
+-----------------+
| remaining_delay |
+-----------------+
| 54 |
+-----------------+
1 row in set (0.00 sec)
mysql> select remaining_delay from performance_schema.replication_applier_status;
+-----------------+
| remaining_delay |
+-----------------+
| 23 |
+-----------------+
1 row in set (0.00 sec)
mysql> select remaining_delay from performance_schema.replication_applier_status;
+-----------------+
| remaining_delay |
+-----------------+
| 16 |
+-----------------+
1 row in set (0.00 sec)
mysql> select remaining_delay from performance_schema.replication_applier_status;
+-----------------+
| remaining_delay |
+-----------------+
| NULL |
+-----------------+
1 row in set (0.00 sec)
mysql> desc test.t3;
ERROR 1146 (42S02): Table 'test.t3' doesn't exist
1.1.3 作用
延迟复制可用于多种目的:
- 防止用户在主库上出错。延迟复制时,可以将延迟的从库回滚到错误之前的时间。
- 测试滞后时系统的行为方式。例如,在应用程序中,延迟可能是由从库设备上的重负载引起的。但是,生成此负载级别可能很困难。延迟复制可以模拟滞后而无需模拟负载。它还可用于调试与从库滞后相关的条件。
- 检查数据库过去的快照,而不必重新加载备份。例如,通过配置延迟为一周的从库,如果需要看一下最近几天开发前的数据库样子,可以检查延迟的从库。
1.2 延迟复制时间戳
MySQL 8.0 提供了一种新方法,用于测量复制拓扑中的延迟,或称复制滞后。该方法取决于与写入二进制日志的每个事务(不是每个事件)的 GTID 相关联的以下时间戳:
original_commit_timestamp:将事务写入(提交)到主库二进制日志之后的自 1970 年 1 月 1 日 00:00:00 UTC 以来的微秒数。immediate_commit_timestamp:将事务写入(提交)到从库的二进制日志之后的自 1970 年 1 月1 日 00:00:00 UTC 以来的微秒数。
mysqlbinlog 的输出以两种格式显示这些时间戳,从 epoch 开始的微秒和 TIMESTAMP 格式,后者基于用户定义的时区以获得更好的可读性。例如:
#190516 15:12:18 server id 1125 end_log_pos 239 CRC32 0xc1ebcb7c Anonymous_GTID last_committed=0 sequence_number=1 rbr_only=no original_committed_timestamp=1557990738835397 immediate_commit_timestamp=1557990738838735 transaction_length=192
# original_commit_timestamp=1557990738835397 (2019-05-16 15:12:18.835397 CST)
# immediate_commit_timestamp=1557990738838735 (2019-05-16 15:12:18.838735 CST)
/*!80001 SET @@session.original_commit_timestamp=1557990738835397*//*!*/;
/*!80014 SET @@session.original_server_version=80016*//*!*/;
/*!80014 SET @@session.immediate_server_version=80016*//*!*/;
SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/;
# at 239
通常,original_commit_timestamp在应用事务的所有副本上始终相同。在主从复制中,主库二进制日志中事务的original_commit_timestamp始终与其immediate_commit_timestamp相同。在从库的中继日志中,事务的original_commit_timestamp和immediate_commit_timestamp与主库的二进制日志中的相同,而在其自己的二进制日志中,事务的immediate_commit_timestamp对应于从库提交事务的时间。
在组复制设置中,当原始主服务器是组的成员时,将在事务准备好提交时生成original_commit_timestamp。再具体说,当事务在原始主服务器上完成执行并且其写入集准备好发送给该组的所有成员以进行认证时,生成original_commit_timestamp。因此,相同的original_commit_timestamp被复制到所有服务器应用事务,并且每个服务器使用immediate_commit_timestamp在其自己的二进制日志中存储本地提交时间。
组复制中独有的视图更改事件是一种特殊情况。包含该事件的事务由每个服务器生成,但共享相同的 GTID。因此,这种事务不是先在主服务器中执行,然后复制到该组其它成员,而是该组的所有成员都执行并应用相同的事务。由于没有原始主服务器,因此这些事务的original_commit_timestamp设置为零。
1.3 监控延迟复制
在 MySQL 8 之前的老版本中,监控复制的延迟(滞后)最常用的方法之一是依赖于show slave status输出中的seconds_behind_master字段。但是,当使用比传统主从复制更复杂的复制拓扑,例如组复制时,此度量标准不再适用。MySQL 8 中添加的immediate_commit_timestamp和original_commit_timestamp可提供有关复制延迟的更精细的信息。
- 监控支持这些时间戳的复制延迟的推荐方法是使用以下 performance_schema 模式中的表。
replication_connection_status:与主服务器连接的当前状态,提供有关连接线程排队到中继日志中的最后和当前事务的信息。replication_applier_status_by_coordinator:协调器线程的当前状态,仅在使用多线程复制时显示该信息,提供有关协调器线程缓冲到工作队列的最后一个事务的信息,以及当前正在缓冲的事务。replication_applier_status_by_worker:应用从主服务器接收事务的线程的当前状态,提供有关应用程序线程或使用多线程复制时每个工作线程应用的事务信息。
- 使用这些表,可以监控相应线程处理的最后一个事务以及该线程当前正在处理的事务的信息,包括:
- 事务的 GTID。
- 从库中继日志中检索的事务的
original_commit_timestamp和immediate_commit_timestamp。 - 线程开始处理事务的时间。
- 对于上次处理的事务,线程完成处理它的时间。
- 除 Performance Schema 表之外,
show slave status的输出还有三个字段与延迟复制有关:SQL_Delay:非负整数,表示使用CHANGE MASTER TO MASTER_DELAY = N配置的复制延迟,以秒为单位。与performance_schema.replication_applier_configuration.desired_delay值相同。SQL_Remaining_Delay:当Slave_SQL_Running_State等待主执行事件后的MASTER_DELAY秒时,该字段包含一个整数,表示延迟剩余的秒数。在它他时候,此字段为 NULL。与performance_schema.replication_applier_status.remaining_delay值相同。Slave_SQL_Running_State:一个字符串,指示 SQL 线程的状态(类似于 Slave_IO_State )。该值与 SHOW PROCESSLIST 显示的 SQL 线程的 State 值相同。
当从库的 SQL 线程在执行事件之前等待延迟时,SHOW PROCESSLIST 将其状态值显示为:Waiting until MASTER_DELAY seconds after master executed event。
2. 部分复制
到目前为止,我们讨论的都是 MySQL 实例级的复制,复制拓扑中的所有服务器都包含整个实例的全部数据集,主库的任何数据变化都会原封不动地再从库进行重放。本节说明另一种不同于此的复制——部分复制。
2.1 简介
如果主库未将修改数据的 SQL 语句或变化的数据行写入其二进制日志,则不会复制该事件。如果主库记录了二进制日志并将其中的事件发送到从库,从库也可以自己确定是执行它还是忽略它。这就是实现MySQL部分复制的两种方式。
主库上,可以使用--binlog-do-db和--binlog-ignore-db选项来控制要记录更改的数据库,以控制二进制日志记录。但是不应该使用这些选项来控制复制哪些数据库和表,推荐的方法是在从库上使用过滤来控制从库上执行的事件。在从库端,是否执行接收事件的决定是根据从库上启动的--replicate-*选项做出的。在 MySQL 5.7 中,可以使用CHANGE REPLICATION FILTER语句动态设置由这些选项控制的过滤器,而不用重启 MySQL 实例。无论是使用--replicate-* 选项在启动时创建还是通过CHANGE REPLICATION FILTER运行从库,管理此类过滤器的规则都是相同的。
复制过滤器不能用于为组复制,因为在某些服务器上过滤事务会使组无法就一致状态达成协议。
缺省时没有--replicate-* 选项,从库执行接收的所有事件,这是最简单的情况。否则,结果取决于给定的特定选项。首先检查数据库级选项(--replicate-do-db,--replicate-ignore-db),如果未使用任何数据库级选项,则继续检查可能正在使用的任何表级选项,未匹配的选项不会被执行。对于仅影响数据库的语句(即CREATE DATABASE,DROP DATABASE和ALTER DATABASE),数据库级选项始终优先于任何--replicate-wild-do-table选项。换句话说,对于此类语句,当且仅当没有适用的数据库级选项时,才会检查--replicate-wild-do-table选项。
为了更容易确定选项集合会产生什么影响,建议避免混合使用do和ignore选项或通配符和非通配符选项。如果指定了任何--replicate-rewrite-db选项,则在测试--replicate- *过滤规则之前应用它们。所有复制过滤选项都遵循相同的区分大小写规则,这些规则适用于MySQL服务器中其它位置的数据库和表的名称,包括lower_case_table_names系统变量的效果。
2.2 评估数据库级复制和二进制日志选项
在评估复制选项时,从库首先检查是否存在适用的--replicate-do-db或--replicate-ignore-db选项。使用--binlog-do-db或--binlog-ignore-db时,过程类似,只是在主库上检查选项。检查匹配的数据库取决于正在处理的事件的二进制日志格式。如果使用 ROW 格式,则要更改数据的数据库是要检查的数据库。如果使用 STATEMENT 格式记录了语句,则默认数据库(使用USE语句指定)是要检查的数据库。看下面的实验。
2.2.1 在从库设置过滤器为 replicate_do_db=(db2)
-- 从库关闭延迟复制
stop slave sql_thread;
change master to master_delay = 0;
start slave sql_thread;
-- 主,创建实验环境
create database db1;
create database db2;
create table db2.t1(a int);
-- 从
mysql>
stop slave sql_thread;
change replication filter replicate_do_db=(db2);
start slave sql_thread;
-- 查看 Replicate_Do_DB: db2
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.2.57
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 3209
Relay_Log_File: Mysql57-Slave-relay-bin.000003
Relay_Log_Pos: 484
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB: db2
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
2.2.2 主库设置缺省数据库为db1,然后删除db2.t1
-- 主
mysql> set binlog_format=statement;
Query OK, 0 rows affected (0.00 sec)
mysql> use db1;
Database changed
mysql> drop table db2.t1;
Query OK, 0 rows affected (0.01 sec)
mysql>
2.2.3 检查从库的复制执行情况
-- 从
mysql> desc db2.t1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| a | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
1 row in set (0.01 sec)
从库上并没有删除 db2.t1。原因是在 STATEMENT 格式,过滤器没有匹配缺省数据库 db1。
2.2.4 改变主的缺省数据库为db2,然后创建表db1.t1
-- 主
mysql> use db2;
Database changed
mysql> create table db1.t1(a int);
Query OK, 0 rows affected (0.03 sec)
2.2.5 检查从库的复制执行情况
-- 从
mysql> desc db1.t1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| a | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
1 row in set (0.00 sec)
因为过滤器匹配了缺省数据库,所以语句在从库上执行。
2.2.6 将主库的二进制日志格式改为ROW,再进行测试
-- 主
mysql> use db1;
Database changed
mysql> set binlog_format=row;
Query OK, 0 rows affected (0.00 sec)
mysql> create table db2.t1(a int);
Query OK, 0 rows affected (0.02 sec)
此时从库已经存在 db2.t1,并且 replicate_do_db=(db2),按照文档的说法,此时会执行复制,预想的结果是因为从库上表已经存在而报错,然而并没有。
-- 主
mysql>
drop table db2.t1;
create table db2.t1(a varchar(5));
insert into db2.t1 values('aaa');
当主库删除表 db2.t1,而从库却没删除。再主库建立新表 db2.t1,与从库已存在的 db2.t1 结构不兼容。向主库的 db2.t1 插入记录后,从库的复制却报错了:
# 报错如下
# Last_Error: Column 0 of table 'db2.t1' cannot be converted from type 'varchar(15(bytes))' to type 'int(11)'
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.2.57
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 4326
Relay_Log_File: Mysql57-Slave-relay-bin.000003
Relay_Log_Pos: 1348
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB: db2
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1677
Last_Error: Column 0 of table 'db2.t1' cannot be converted from type 'varchar(15(bytes))' to type 'int(11)'
Skip_Counter: 0
Exec_Master_Log_Pos: 4073
Relay_Log_Space: 2893
Until_Condition: None
Until_Log_File:
可以看到,当缺省数据库与replicate_do_db不同时,create table、drop table语句不会被复制到从库,但DML语句会正常复制。注意,行格式只记录 DML 语句,即使binlog_format = ROW,DDL 语句也始终记录为语句。因此,始终根据基于语句的复制规则筛选所有 DDL 语句。这意味着必须使用USE语句显式选择默认数据库,以便应用 DDL 语句。数据库级过滤选项的检查流程如下图所示。
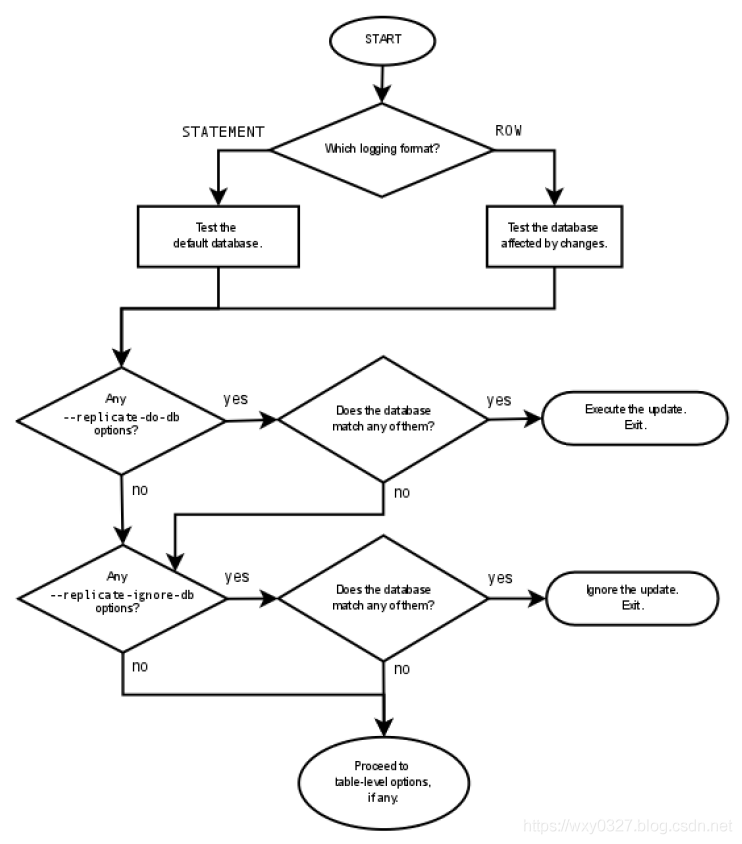
重要的是,此阶段通过的语句尚未实际执行,在检查了所有表级选项 (如果有)。之后,结果允许执行该语句,语句才会真正执行。二进制日志选项的检查步骤简单描述如下:
- (1). 是否有
--binlog-do-db或--binlog-ignore-db选项?
是,继续第 (2) 步;
否,记录语句并退出。 - (2). 是否有默认数据库 (USE选择了任何数据库)?
是,继续第 (3) 步;
否,忽略语句并退出。 - (3). 有一个默认数据库。是否有
--binlog-do-db选项?- 是,它们中的任何一个都匹配数据库吗?
- 是,记录该语句并退出;
- 否,忽略语句并退出。
- 否,继续执行第4步。
- 是,它们中的任何一个都匹配数据库吗?
- (4). 是否有任何
--binlog-ignore-db选项与数据库匹配?- 是,忽略该语句并退出;
- 否,记录语句并退出。
在确定CREATE DATABASE、ALTER DATABASE和DROP DATABASE语句是记录还是忽略时,正在创建、更改或删除的数据库将替换缺省数据库。--binlog-do-db有时可能意味着“忽略其他数据库”。例如,使用基于语句的日志记录时,仅使用--binlog-do-db = sales运行的服务器不会写入默认数据库与sales不同的二进制日志语句。使用具有相同选项的基于行的日志记录时,服务器仅记录那些更改 sales 库数据的更新。
2.3 评估表级复制选项
2.3.1 评估过程
仅当满足以下两个条件之一时,从库才会检查并评估表选项:
- 没有数据库选项。
- 有数据库选项但与语句不匹配。
作为初始规则,如果主库启用了基于语句的复制并且语句出现在存储函数内,则从库执行语句并退出。对于基于语句的复制,复制事件表示语句,构成给定事件的所有更改都与单个 SQL 语句相关联。对于基于行的复制,每个事件表示单个表行中的更改,因此单个语句(如UPDATE mytable SET mycol = 1)可能会产生许多基于行的事件。从事件角度来看,检查表选项的过程对于基于行和基于语句的复制都是相同的。
到达表级选项检查时,如果没有表选项,从库简单地执行所有事件。如果有任何--replicate-do-table或--replicate-wild-do-table选项,则事件必须匹配其中一个才能执行,否则它会被忽略。如果存在任何--replicate-ignore-table或--replicate-wild-ignore-table选项,则执行所有事件,但匹配任何这些选项的事件除外。下图详细地描述了表级选项评估过程,起点是数据库级选项的评估结束,如上节图所示。
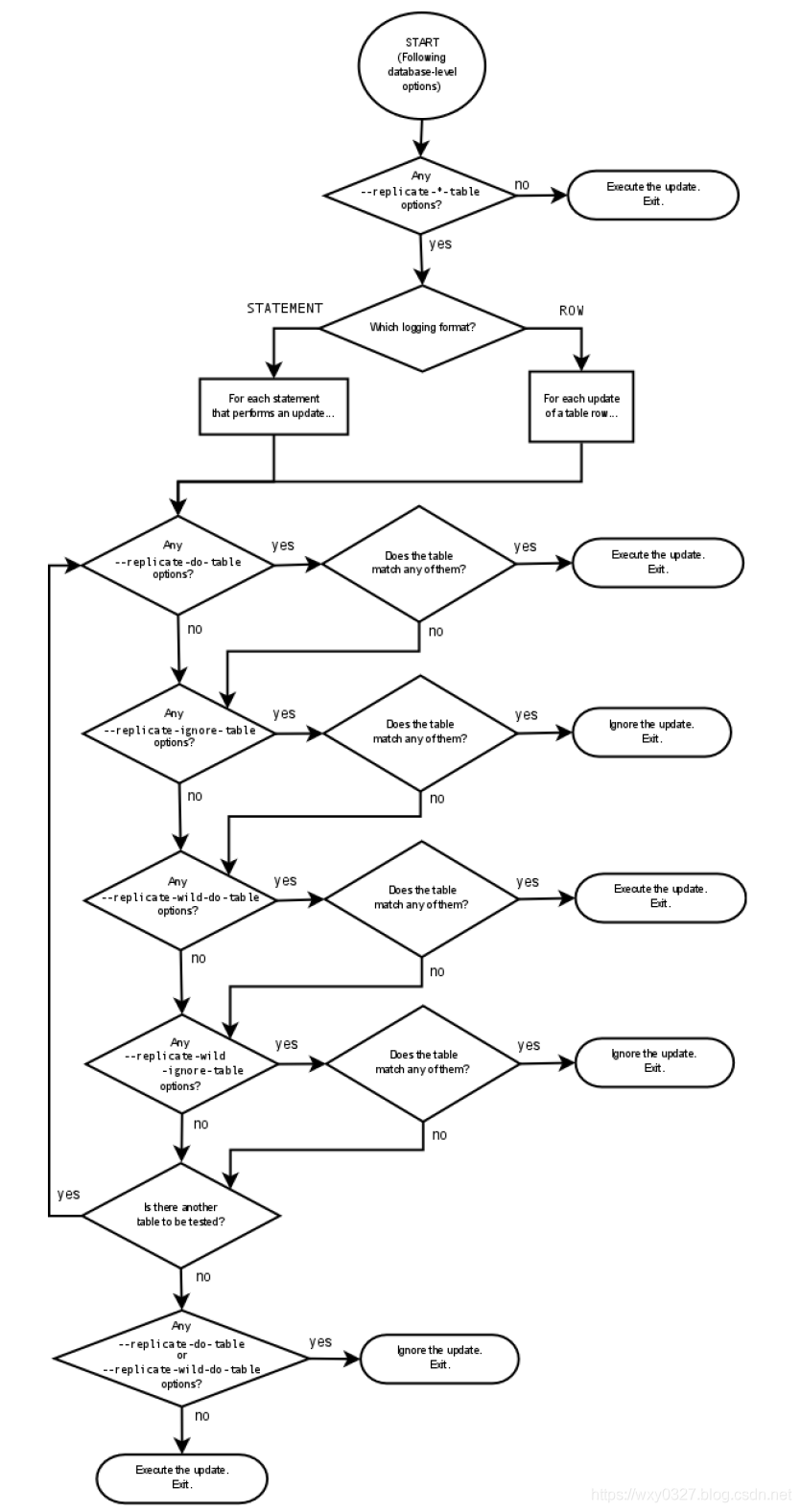
如果单个 SQL 语句中同时含有--replicate-do-table或--replicate-wild-do-table选项包含的表,以及--replicate-ignore-table或--replicate-wild-ignore-table选项包含的另一个表,如果语句是使用binlog_format = ROW记录的 DML 语句,更新的表和忽略的表都可以按预期复制,该更新的行更新,该忽略的行忽略。如果是基于语句的复制,无论是 DDL 还是 DML 语句,如果匹配了--replicate-do-table中的表,语句将被复制,包括--replicate-ignore-table中的表也会更新。这点与 MySQL 8 官方文档中的描述不符:
Statement-based replication stops if a single SQL statement operates on both a table that is included by a --replicate-do-table or --replicate-wild-do-table option, and another table that is ignored by a --replicate-ignore-table or --replicate-wild-ignore-table option. The slave must either execute or ignore the complete statement (which forms a replication event), and it cannot logically do this. This also applies to row-based replication for DDL statements, because DDL statements are always logged as statements, without regard to the logging format in effect. The only type of statement that can update both an included and an ignored table and still be replicated successfully is a DML statement that has been logged with binlog_format=ROW.
2.3.2 实验
下面简单验证一下表级的过滤复制规则。
2.3.2.1 从库中设置表级复制过滤
-- 从
mysql>
stop slave sql_thread;
change replication filter replicate_do_db=();
change replication filter replicate_do_table = (db3.t1), replicate_ignore_table = (db3.t2);
start slave sql_thread;
2.3.2.2 在主库上执行更新,并在从库检查复制情况
# 测试环境主库drop了之前的test,导致从库 Slave_SQL_Running: No
# 解决方法就是从库让指针往下移动
#mysql> stop slave;
#mysql> set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
#mysql> start slave;
-- 主
mysql>
create database db3;
create table db3.t1(a int);
create table db3.t2(a int);
insert into db3.t1 values (1);
insert into db3.t2 values (1);
-- 从
mysql> select * from db3.t1;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
可以看到,create database 以及和表匹配的DDL、DML语句正常复制。
2.3.2.3 在从库执行同样地语句使主从数据一致,以便继续实验
-- 从
mysql>
create table db3.t2(a int);
insert into db3.t2 values (1);
在 MySQL 主从复制中,为主从保证数据一致性,通常将从库设置为只读(read_only=on),这里只是为了方便后续实验才在从库执行写操作。
2.3.2.4 在主库上执行正常的单表更新,并在从库检查复制情况
-- 主
mysql>
update db3.t1 set a=2;
update db3.t2 set a=2;
-- 从
mysql> select * from db3.t1;
+------+
| a |
+------+
| 2 |
+------+
1 row in set (0.00 sec)
mysql> select * from db3.t2;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
符合预期,db3.t1 正常复制,db3.t2 被忽略
2.3.2.5 在一句更新语句中同时包含replicate_do_table与replicate_ignore_table中的表
-- 主
mysql> update db3.t1 t1, db3.t2 t2 set t1.a=3, t2.a=3;
-- 从
mysql> select * from db3.t1;
+------+
| a |
+------+
| 3 |
+------+
1 row in set (0.00 sec)
mysql> select * from db3.t2;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
在binlog_format=row时,两个表的复制符合预期,db3.t1 正常复制,db3.t2 被忽略。将二进制日志格式换成 statement 再试。
-- 主
mysql>
set binlog_format=statement;
update db3.t1 t1, db3.t2 t2 set t1.a=4, t2.a=4;
-- 从
mysql> select * from db3.t1;
+------+
| a |
+------+
| 4 |
+------+
1 row in set (0.00 sec)
mysql> select * from db3.t2;
+------+
| a |
+------+
| 4 |
+------+
1 row in set (0.00 sec)
这个语句还是复制成功了,包括replicate_ignore_table中的 db3.t2,也正常更新。
2.3.2.6 在主库同时删除db1.t1和db1.t2表
-- 主
mysql> drop table db3.t1,db3.t2;
-- 从
mysql> select * from db3.t1;
ERROR 1146 (42S02): Table 'db1.t1' doesn't exist
mysql> select * from db3.t2;
ERROR 1146 (42S02): Table 'db1.t2' doesn't exist
从上复制成功,db3.t2也被删除了。
2.4 复制规则应用
本节提供一些有关复制过滤选项不同组合的说明和用法示例。下表给出了复制过滤规则类型的一些典型组合:
| 条件(选项类型) | 结果 |
|---|---|
没有--relicate-*选项 |
从库执行从主库接收的所有事件。 |
有--replicate-*-db选项,但没有表选项 |
从服务器使用数据库选项接受或忽略事件。 它执行这些选项允许的所有事件,因为没有表限制。 |
有--replicate-*-table选项,但没有数据库选项 |
由于没有数据库条件,因此在数据库检查阶段接受所有事件。 从库仅根据表选项执行或忽略事件。 |
| 数据库和表选项的组合 | 从库使用数据库选项接受或忽略事件。然后,它根据表选项评估这些选项允许的所有事件。 这有时会导致结果看似违反直觉,根据使用的是基于语句还是基于行的复制,结果可能会有所不同。 |
下面是一个更复杂的示例,我们检查基于语句和基于行的设置的结果。假设主库上有两个表 db1.t1 和 db1.t2,并且从库在运行时只有以下选项:
2.4.1 环境初始化
# 从库从库初始化,从库去掉以前的过滤规则
mysql>
stop slave sql_thread;
change replication filter replicate_do_db=(),replicate_ignore_db=(),replicate_do_table = (), replicate_ignore_table = ();
start slave sql_thread;
# 主库
mysql>
drop database db1;
drop database db2;
drop database db3;
2.4.2 主库建立对象
#主
mysql>
create database db1;
create database db2;
create table db1.t1(a int);
create table db2.t2(a int);
2.4.2 从库增加过新的滤规则
#从
mysql>
stop slave sql_thread;
change replication filter replicate_ignore_db = (db1), replicate_do_table = (db2.t2);
start slave sql_thread;
2.4.4 数据测试
# 主库,db1默认数据库,db2插入数据
mysql>
set binlog_format=statement;
use db1;
insert into db2.t2 values (1);
# 查看从库
mysql> select * from db2.t2;
Empty set (0.00 sec)
从库的 db2.t2 表没有数据。USE 语句使 db1 成为默认数据库,与--replicate-ignore-db选项匹配,因此忽略 INSERT 语句,不检查表选项。用row方式再执行一遍:
# 主库
mysql>
set binlog_format=row;
use db1;
insert into db2.t2 values (1);
# 查看从库
mysql> select * from db2.t2;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
这回 db2.t2 复制了一条数据。使用基于行的复制时,缺省数据库对从库读取数据库选项的方式没有影响。因此,USE 语句对如何处理--replicate-ignore-db选项没有影响。此选项指定的数据库与 INSERT 语句更改数据的数据库不匹配,因此从库继续检查表选项。--replicate-do-table指定的表与要更新的表匹配,并插入行。
2.5 部分复制示例
在某些情况下,可能只有一个主库(服务器),并且希望将不同的数据库复制到不同的从库(服务器)。例如,可能希望将不同的销售数据分发到不同的部门,以帮助在数据分析期间分散负载。如图所示,将主库的 db1 复制到从库 1,db2 复制到从库 2。
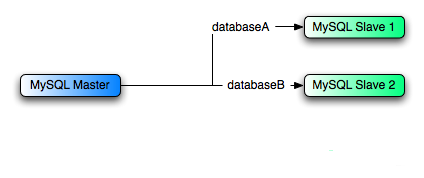
实现时可以先配置正常的一主两从复制,然后通过在每个从库上使用--replicate-wild-do-table配置选项来限制每个从库执行的事件。注意,在使用基于语句的复制时,不应将--replicate-do-db用于此目的,因为基于语句的复制会导致此选项的影响因当前所选的数据库而异。这也适用于混合格式复制,因为这可能使用基于语句的格式复制某些更新。
2.5.1 初始化数据
# 从库从库初始化,从库去掉以前的过滤规则
mysql>
stop slave sql_thread;
change replication filter replicate_do_db=(),replicate_ignore_db=(),replicate_do_table = (), replicate_ignore_table = (),replicate_wild_do_table=(),Replicate_Wild_Ignore_Table=();
start slave sql_thread;
# 主库
mysql>
drop database db1;
drop database db2;
drop database db3;
2.5.2 从库规则
#从库1
stop slave sql_thread;
change replication filter replicate_wild_do_table=('db1.%');
start slave sql_thread;
#从库2
stop slave sql_thread;
change replication filter replicate_wild_do_table=('db2.%');
start slave sql_thread;
2.5.3 数据测试
此配置中的每个从库从主库接收整个二进制日志,但仅执行二进制日志中--replicate-wild-do-table选项所包含的数据库和表的那些事件。
-- 主
create database db1;
create database db2;
create table db1.t1(a int);
create table db2.t2(a int);
insert into db1.t1 select 1;
insert into db2.t2 select 2;
-- 从1
mysql> select * from db1.t1;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
mysql> select * from db2.t2;
ERROR 1049 (42000): Unknown database 'db2'
mysql>
-- 从2
mysql> select * from db1.t1;
ERROR 1049 (42000): Unknown database 'db1'
mysql> select * from db2.t2;
+------+
| a |
+------+
| 2 |
+------+
1 row in set (0.00 sec)
mysql>
2.5.4 routine的复制
数据如预期复制,db1 和 db2 的数据分别复制到从库 1 和从库 2。下面看一下 routine 的复制情况。
-- 主
delimiter //
create procedure db1.p1 ()
begin
select 1;
end;
//
delimiter ;
-- 从1
mysql> call db1.p1();
+---+
| 1 |
+---+
| 1 |
+---+
1 row in set (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
-- 从2
mysql> call db1.p1();
ERROR 1305 (42000): PROCEDURE db1.p1 does not exist
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.1.125
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000011
Read_Master_Log_Pos: 73101
Relay_Log_File: hdp4-relay-bin.000047
Relay_Log_Pos: 1591
Relay_Master_Log_File: binlog.000011
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table: db2.%
Replicate_Wild_Ignore_Table:
Last_Errno: 1049
Last_Error: Error 'Unknown database 'db1'' on query. Default database: ''. Query: 'CREATE DEFINER=`wxy`@`%` PROCEDURE `db1`.`p1`()
begin
select 1;
end'
Skip_Counter: 0
Exec_Master_Log_Pos: 72869
Relay_Log_Space: 2194
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1049
Last_SQL_Error: Error 'Unknown database 'db1'' on query. Default database: ''. Query: 'CREATE DEFINER=`wxy`@`%` PROCEDURE `db1`.`p1`()
begin
select 1;
end'
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1125
Master_UUID: 8eed0f5b-6f9b-11e9-94a9-005056a57a4e
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp: 190524 15:20:03
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set (0.00 sec)
mysql>
在主库上的 db1 建立存储过程,从库1正常复制,但从库 2 却报错了,它还是执行了复制,只是因为缺少db1数据库而复制报错。可见,replicate_wild_do_table只对表起作用,而对于routine无效,主库上所有库的 routine 都会在所有从库执行复制。如果在复制开始之前有必须同步到从库的数据,则可以将所有数据同步到每个从库,然后在从库删除不想保留的数据库或表。或者使用 mysqldump 为每个数据库创建单独的转储文件,并在每个从库上加载相应的转储文件,例如:
# 从库1
mysqldump --single-transaction --databases db1 --master-data=1 --host=192.168.2.80 --user=slave --password=slave --apply-slave-statements | mysql -uroot -proot
# 从库2
mysqldump --single-transaction --databases db2 --master-data=1 --host=192.168.2.80 --user=slave --password=slave --apply-slave-statements | mysql -uroot -proot
参考 https://blog.csdn.net/wzy0623/article/details/90642712。
扫码关注公众号,获取最新发布。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号