

oracle进阶之分析函数
本博客是自己在学习和工作途中的积累与总结,纯属经验之谈,仅供自己参考,也欢迎大家转载,转载时请注明出处。
http://www.cnblogs.com/king-xg/p/6797119.html
分析函数提供了跨行,多层级聚合引用值的能力,并且可以在数据子集中空值排序粒度。与分组函数不同的是,分析函数并不将结果集聚合为较少的行。
而且分析函数的查询速度比传统sql查询会快很多。
使用分析函数可以在不适用任何自连接的情况下得到一行中聚合和未聚合的值。
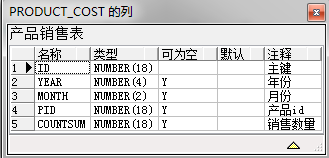
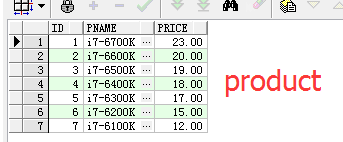
示例数据:
-- 创建销售表 create table product_cost( id number(18) primary key, year number(4), month number(2), pid number(18), countSum number(18) ); -- 创建产品表 create table product( id number(18) primary key, pname varchar(100), price number(8,2) ); -- 初始化产品表记录 insert into product (pname,price) values('i7-6700K','23'); insert into product (pname,price) values('i7-6600K','20'); insert into product (pname,price) values('i7-6500K','19'); insert into product (pname,price) values('i7-6400K','18'); insert into product (pname,price) values('i7-6300K','17'); insert into product (pname,price) values('i7-6200K','15'); insert into product (pname,price) values('i7-6100K','12'); -- 初始化销售表记录 insert into product_cost(year,month,pid,countSum) values(2000,1,1,500); insert into product_cost(year,month,pid,countSum) values(2000,1,2,630); insert into product_cost(year,month,pid,countSum) values(2000,1,3,1200); insert into product_cost(year,month,pid,countSum) values(2000,1,4,320); insert into product_cost(year,month,pid,countSum) values(2000,1,5,250); insert into product_cost(year,month,pid,countSum) values(2000,1,6,250); insert into product_cost(year,month,pid,countSum) values(2000,1,7,350); insert into product_cost(year,month,pid,countSum) values(2000,2,1,1500); insert into product_cost(year,month,pid,countSum) values(2000,2,2,1630); insert into product_cost(year,month,pid,countSum) values(2000,2,3,200); insert into product_cost(year,month,pid,countSum) values(2000,2,4,1320); insert into product_cost(year,month,pid,countSum) values(2000,2,5,250); insert into product_cost(year,month,pid,countSum) values(2000,2,6,350); insert into product_cost(year,month,pid,countSum) values(2000,2,7,520); insert into product_cost(year,month,pid,countSum) values(2000,3,1,520); insert into product_cost(year,month,pid,countSum) values(2000,3,2,660); insert into product_cost(year,month,pid,countSum) values(2000,3,3,1900); insert into product_cost(year,month,pid,countSum) values(2000,3,4,300); insert into product_cost(year,month,pid,countSum) values(2000,3,5,210); insert into product_cost(year,month,pid,countSum) values(2000,3,6,210); insert into product_cost(year,month,pid,countSum) values(2000,3,7,320); insert into product_cost(year,month,pid,countSum) values(2000,4,1,1520); insert into product_cost(year,month,pid,countSum) values(2000,4,2,1660); insert into product_cost(year,month,pid,countSum) values(2000,4,3,2900); insert into product_cost(year,month,pid,countSum) values(2000,4,4,1200); insert into product_cost(year,month,pid,countSum) values(2000,4,5,980); insert into product_cost(year,month,pid,countSum) values(2000,4,6,910); insert into product_cost(year,month,pid,countSum) values(2000,4,7,620); insert into product_cost(year,month,pid,countSum) values(2001,1,1,500); insert into product_cost(year,month,pid,countSum) values(2001,1,2,630); insert into product_cost(year,month,pid,countSum) values(2001,1,3,1200); insert into product_cost(year,month,pid,countSum) values(2001,1,4,320); insert into product_cost(year,month,pid,countSum) values(2001,1,5,150); insert into product_cost(year,month,pid,countSum) values(2001,1,6,250); insert into product_cost(year,month,pid,countSum) values(2001,1,7,350); insert into product_cost(year,month,pid,countSum) values(2001,2,1,1500); insert into product_cost(year,month,pid,countSum) values(2001,2,2,1630); insert into product_cost(year,month,pid,countSum) values(2001,2,3,200); insert into product_cost(year,month,pid,countSum) values(2001,2,4,1320); insert into product_cost(year,month,pid,countSum) values(2001,2,5,250); insert into product_cost(year,month,pid,countSum) values(2001,2,6,350); insert into product_cost(year,month,pid,countSum) values(2001,2,7,450); insert into product_cost(year,month,pid,countSum) values(2001,3,1,520); insert into product_cost(year,month,pid,countSum) values(2001,3,2,660); insert into product_cost(year,month,pid,countSum) values(2001,3,3,1900); insert into product_cost(year,month,pid,countSum) values(2001,3,4,300); insert into product_cost(year,month,pid,countSum) values(2001,3,5,180); insert into product_cost(year,month,pid,countSum) values(2001,3,6,210); insert into product_cost(year,month,pid,countSum) values(2001,3,7,320); insert into product_cost(year,month,pid,countSum) values(2001,4,1,1520); insert into product_cost(year,month,pid,countSum) values(2001,4,2,1660); insert into product_cost(year,month,pid,countSum) values(2001,4,3,2900); insert into product_cost(year,month,pid,countSum) values(2001,4,4,1200); insert into product_cost(year,month,pid,countSum) values(2001,4,5,980); insert into product_cost(year,month,pid,countSum) values(2001,4,6,910); insert into product_cost(year,month,pid,countSum) values(2001,4,7,620);
数据展示:


-- 常用分析函数列表 1. leg -- 访问一个分区或结果集中的前一行 2. lead -- 访问一个分区或结果集中的后一行 3. first_value -- 访问一个分区或结果集中的第一行 4. last_value -- 访问一个分区或结果集中的最后一行 5. nth_value -- 访问一个分区或结果集的指定行 6. rank -- 将数据行值按照排序后的顺序进行排名,在有并列的情况下排名值将被跳过 7. dense_rank -- 将数据行值按照排序后的顺序进行排名,在有并列的情况下也不会跳过排名 8. row_number -- 对行进行排序,并为每一行赋予一个随机且唯一的编号 9. ratio_to_report -- 计算报告中值的比例 10. percent_rank -- 将计算得到的排名标准化为0到1之间的值 11. ntile -- 对每一个分区进行再分组,并为每一个分组提供一个唯一标识(仅在本分区中唯一),每组的数据行数为指定值,但每组之间最多相差一个数据行 12. listagg -- 将来自不同行的列值转化为列表格式
分析函数的组成:
(1) 指定列或范围 解释: 分析函数一般带两个括号,第一个就是指定该函数所作用的列
(2) 分组 解释: 1. 将数据分区,关键字 partition by,有点像group by,但却有很大不同,group by分组后的列只存在唯一值,不存在等同的值(就像是将数据分类,只显示类型名称一样),而partition by 是将数据原封不动根据后面给的字段进行划分边界形成分区(即每个分区都存在边界)
2. group by 针对整个表或数据集,partition by 针对于每一行的记录
(3) 排序 解释: order by就是排序
(4) 窗口控制 解释: 1.控制边界的范围,默认是 rows between unbounded preceding and current row(起始边界到当前行),rows between unbounded preceding and unbounded following(整个分区),以及自定义的边界范围 rows between [number] preceding and [number] following(起始边界是该行的前xx行结束边界是该行的后xx行)
2.在没有分区的情况的,窗口控制会在一定程度上起到分区作用
举例:
1. (leg函数) 查询每一个产品的月销售总额与前一个月的对比
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,(pc.countsum*p.price) as currentAmt,lag(pc.countsum*p.price,1,pc.countsum*p.price) over(partition by year,pc.pid order by year,month,pid) as beforeAmt from product_cost pc left join product p on p.id=pc.pid
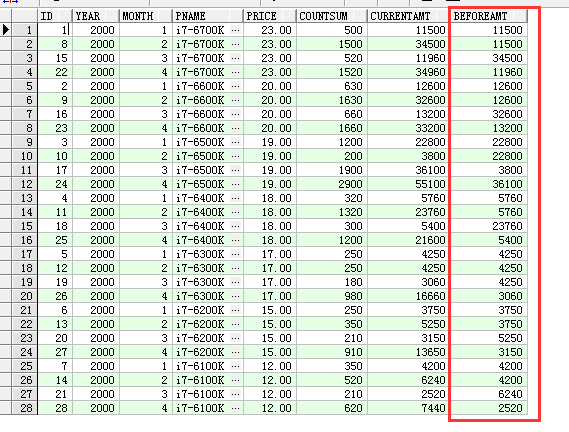
注意: leg分析函数中的字段区域,不能用别名(不能写"currentAmt"只能写"pc.countsum*p.price"),会报标识符无效的异常,除非用子查询,就能用别名,原因:select 同一层级,解析在同一时间,oracle是认识别名标注的字段,除非在解析分析函数之前,即子查询
2. (lead函数),同上就是查询的方向由向上查询改成向下查询而已。
3. (first_value函数) 统计每个月月销量第一的产品
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,(p.price*pc.countsum) as currentAmt,first_value(p.price*pc.countsum) over(partition by year,month order by year,month,p.price*pc.countsum DESC) as sum from product_cost pc left join product p on pc.pid=p.id
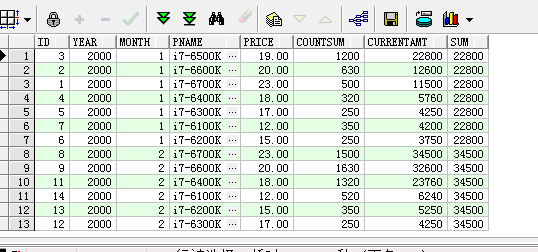
聚合函数也可以应用到里面,上面的sql可以换成下面的
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,(p.price*pc.countsum) as currentAmt,max(p.price*pc.countsum) over(partition by year,month order by year,month,p.price*pc.countsum DESC) as sum from product_cost pc left join product p on pc.pid=p.id
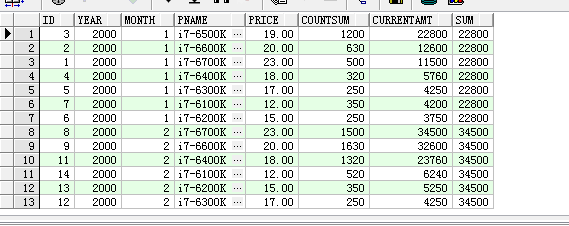
4. last_value函数,同上,查询分区中排序或不排序的最后一条记录
5. nth_value函数,查询指定行的记录,比如: 计算当月销量第二名的产品销量总额
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,(p.price*pc.countsum) as currentAmt,nth_value(p.price*pc.countsum,2) over(partition by year,month order by year,month,p.price*pc.countsum DESC rows between unbounded preceding and unbounded following) as sum from product_cost pc left join product p on pc.pid=p.id

6. rank函数,排名函数之一,特点:同名(排名)跳排,排名依据为order by 后的字段值,例子:对每个月的产品进行排名,依据月销量进行排名
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,rank() over(partition by year,month order by pc.countsum DESC) as orderName from product_cost pc left join product p on pc.pid=p.id
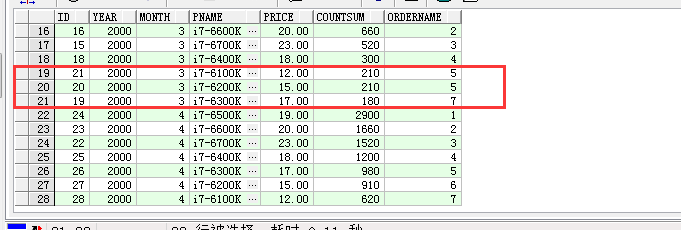
7. dense_rank函数,排名函数之一,特点:同名不跳排,排名依据order by后的字段值,例子:对每个月的产品进行排名,依据月销量进行排名
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,dense_rank() over(partition by year,month order by pc.countsum DESC) as orderName from product_cost pc left join product p on pc.pid=p.id
小结: rank函数和dense_rank函数的相同点,排序的字段值相同,则排名相同,唯一不同点就是rank会跳排,根据相同值的数量而定,跳排数为相等值的数量-1,dense_rank函数不跳排,无论存在多少相等的值
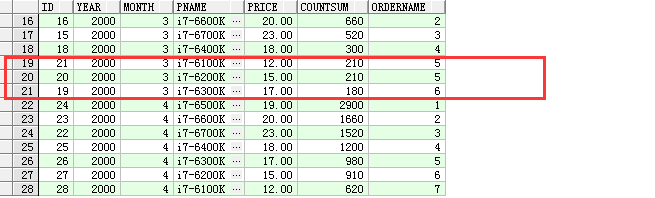
8. row_number函数,为数据行分配一个唯一标识,举例:
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,row_number() over(partition by year,month order by pc.countsum DESC) as orderName from product_cost pc left join product p on pc.pid=p.id
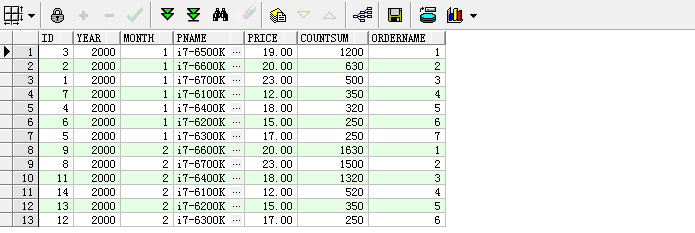
9. ratio_to_report函数,计算值在该分区或整个表或数据集中所占比例
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,trunc(100*ratio_to_report(p.price*pc.countsum) over(partition by year,month),2)||'%' as proportion from product_cost pc left join product p on pc.pid=p.id order by year,month,p.price*pc.countsum DESC

注意: 在ratio_to_report函数中,不能使用排序,只能在外层使用order by
10. percent_rank函数,计算得到的排名,且排名值为0-1之间的数(排名值越低,排名越高)
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,percent_rank() over(partition by year,month order by countsum DESC) as proportion from product_cost pc left join product p on pc.pid=p.id
11. ntile函数,特点:方便将有问题的数据放到一个统一的容器中,举例:领导发话说客户不想看到这些销量低于300的数据记录
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,ntile(3) over(partition by year,month order by countsum DESC) as proportion from product_cost pc left join product p on pc.pid=p.id

12. listagg函数拥有将列值转化成列表格的能力
select listagg(p.pname,',') within group (order by p.id) as str from product p

// 结果: i7-6700K,i7-6600K,i7-6500K,i7-6400K,i7-6300K,i7-6200K,i7-6100K
顺便小结一下,字符串的拼接方法:
(1). 自定义函数拼接字符串
(2). "||" 符合进行拼接
(3). wmsys.wm_concat函数拼接字符串
(4). listagg函数拼接字符串

 浙公网安备 33010602011771号
浙公网安备 33010602011771号