NLP FROM SCRATCH: GENERATING NAMES WITH A CHARACTER-LEVEL RNN(2)
Author: Sean Robertson
从头开始NLP的第二篇。第一篇用于对给定的名字进行分类,分类属于哪种语言。这次将学习如何从给定语言生成名字。

仍然手动实现一个小型RNN,不同的是之前输入一个名字的所有字母来输出一个类别,这次输入类别一次输出一个字母。递归预测来形成语言。也被称为“语言模型”。
推荐阅读:
I assume you have at least installed PyTorch, know Python, and understand Tensors:
- https://pytorch.org/ For installation instructions
- Deep Learning with PyTorch: A 60 Minute Blitz to get started with PyTorch in general
- Learning PyTorch with Examples for a wide and deep overview
- PyTorch for Former Torch Users if you are former Lua Torch user
It would also be useful to know about RNNs and how they work:
- The Unreasonable Effectiveness of Recurrent Neural Networks shows a bunch of real life examples
- Understanding LSTM Networks is about LSTMs specifically but also informative about RNNs in general
I also suggest the previous tutorial, NLP From Scratch: Classifying Names with a Character-Level RNN
数据准备
下载:Download the data from here and extract it to the current directory.(参考上一节)
1 from __future__ import unicode_literals, print_function, division 2 from io import open 3 import glob 4 import os 5 import unicodedata 6 import string 7 8 all_letters = string.ascii_letters + " .,;'-" 9 n_letters = len(all_letters) + 1 # Plus EOS marker 10 11 def findFiles(path): return glob.glob(path) 12 13 # Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427 14 def unicodeToAscii(s): 15 return ''.join( 16 c for c in unicodedata.normalize('NFD', s) 17 if unicodedata.category(c) != 'Mn' 18 and c in all_letters 19 ) 20 21 # Read a file and split into lines 22 def readLines(filename): 23 lines = open(filename, encoding='utf-8').read().strip().split('\n') 24 return [unicodeToAscii(line) for line in lines] 25 26 # Build the category_lines dictionary, a list of lines per category 27 category_lines = {} 28 all_categories = [] 29 for filename in findFiles('data/names/*.txt'): 30 category = os.path.splitext(os.path.basename(filename))[0] 31 all_categories.append(category) 32 lines = readLines(filename) 33 category_lines[category] = lines 34 35 n_categories = len(all_categories) 36 37 if n_categories == 0: 38 raise RuntimeError('Data not found. Make sure that you downloaded data ' 39 'from https://download.pytorch.org/tutorial/data.zip and extract it to ' 40 'the current directory.') 41 42 print('# categories:', n_categories, all_categories) 43 print(unicodeToAscii("O'Néàl"))

构建网络
在上一节的基础上进行扩展,额外的类别tensor和字母输入的格式是一样,都是独热编码。输出的是下个字母的概率。在采样的时候概率最高的字母作为下个输入字母。加入了一个线性层o2o来提高效率。也有一个dropout层,来避免过拟合。故意在网络最后使用dropout来增加采样多样性。
import torch import torch.nn as nn class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__() self.hidden_size = hidden_size self.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size) self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size) self.o2o = nn.Linear(hidden_size + output_size, output_size) self.dropout = nn.Dropout(0.1) self.softmax = nn.LogSoftmax(dim=1) def forward(self, category, input, hidden): input_combined = torch.cat((category, input, hidden), 1) hidden = self.i2h(input_combined) output = self.i2o(input_combined) output_combined = torch.cat((hidden, output), 1) output = self.o2o(output_combined) output = self.dropout(output) output = self.softmax(output) return output, hidden def initHidden(self): return torch.zeros(1, self.hidden_size)
训练
准备工作:定义一些帮助函数随机生成一些语言-名字组合。
import random # Random item from a list def randomChoice(l): return l[random.randint(0, len(l) - 1)] # Get a random category and random line from that category def randomTrainingPair(): category = randomChoice(all_categories) line = randomChoice(category_lines[category]) return category, line
每一步,对于每个生成的字母,网络的输入为(类别、当前字母、隐藏态),输出为(下个字母、下个隐藏态)。对于每次训练过程,需要类别和与一组输入字母,和一组输出/目标字母。
因为根据当前字母来预测下个字母,字母对是行中连续的一组字母。例如:对于ABCD,将会创建(‘A’,'B'),('B','C')...
类别tensor是独热类型,当训练的时候输入到网络。这个操作可以包含在隐藏态中或用其他策略。
1 # One-hot vector for category 2 def categoryTensor(category): 3 li = all_categories.index(category) 4 tensor = torch.zeros(1, n_categories) 5 tensor[0][li] = 1 6 return tensor 7 8 # One-hot matrix of first to last letters (not including EOS) for input 9 def inputTensor(line): 10 tensor = torch.zeros(len(line), 1, n_letters) 11 for li in range(len(line)): 12 letter = line[li] 13 tensor[li][0][all_letters.find(letter)] = 1 14 return tensor 15 16 # LongTensor of second letter to end (EOS) for target 17 def targetTensor(line): 18 letter_indexes = [all_letters.find(line[li]) for li in range(1, len(line))] 19 letter_indexes.append(n_letters - 1) # EOS 20 return torch.LongTensor(letter_indexes)
为了方便训练,利用randomTrainingExample 函数来随机获取(类别、name行)对,并转为tensor。
# Make category, input, and target tensors from a random category, line pair def randomTrainingExample(): category, line = randomTrainingPair() category_tensor = categoryTensor(category) input_line_tensor = inputTensor(line) target_line_tensor = targetTensor(line) return category_tensor, input_line_tensor, target_line_tensor
训练网络
相对于分类仅仅利用最后的输出,而这次在每一步都要进行预测,素以每一步都计算损失。
自动求导机制可以帮助实现计算损失并反向传播。
criterion = nn.NLLLoss() learning_rate = 0.0005 def train(category_tensor, input_line_tensor, target_line_tensor): target_line_tensor.unsqueeze_(-1) hidden = rnn.initHidden() rnn.zero_grad() loss = 0 for i in range(input_line_tensor.size(0)): output, hidden = rnn(category_tensor, input_line_tensor[i], hidden) l = criterion(output, target_line_tensor[i]) loss += l loss.backward() for p in rnn.parameters(): p.data.add_(-learning_rate, p.grad.data) return output, loss.item() / input_line_tensor.size(0)
为了跟踪训练过程,加入一个时间函数:
import time import math def timeSince(since): now = time.time() s = now - since m = math.floor(s / 60) s -= m * 60 return '%dm %ds' % (m, s)
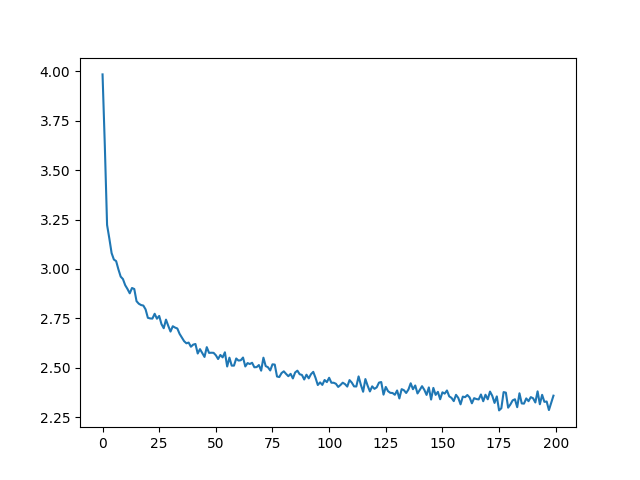
训练、打印并记录一些loss值用于后续可视化。
rnn = RNN(n_letters, 128, n_letters) n_iters = 100000 print_every = 5000 plot_every = 500 all_losses = [] total_loss = 0 # Reset every plot_every iters start = time.time() for iter in range(1, n_iters + 1): output, loss = train(*randomTrainingExample()) total_loss += loss if iter % print_every == 0: print('%s (%d %d%%) %.4f' % (timeSince(start), iter, iter / n_iters * 100, loss)) if iter % plot_every == 0: all_losses.append(total_loss / plot_every) total_loss = 0

损失可视化
import matplotlib.pyplot as plt import matplotlib.ticker as ticker plt.figure() plt.plot(all_losses)
采样
为了采样,给网络一个字母然后网络预测出下一个字母,然后继续这个过程直到结束。
- 创建一个类别tensor,开始字母和初始隐藏态
- 创建一个含开始字母的output_name串
- 直到输出长度足够
- 输入当前字母给网络
- 根据最高概率得到下个字母,和下一个隐藏态
- 如果到末尾EOS则终止
- 如果是常规字母,输出output_name并继续
- 返回最终的名字
另一种策略:不必给定起始字母,初始串也可以,网络来选择初始字母。
max_length = 20 # Sample from a category and starting letter def sample(category, start_letter='A'): with torch.no_grad(): # no need to track history in sampling category_tensor = categoryTensor(category) input = inputTensor(start_letter) hidden = rnn.initHidden() output_name = start_letter for i in range(max_length): output, hidden = rnn(category_tensor, input[0], hidden) topv, topi = output.topk(1) topi = topi[0][0] if topi == n_letters - 1: break else: letter = all_letters[topi] output_name += letter input = inputTensor(letter) return output_name # Get multiple samples from one category and multiple starting letters def samples(category, start_letters='ABC'): for start_letter in start_letters: print(sample(category, start_letter)) samples('Russian', 'RUS') samples('German', 'GER') samples('Spanish', 'SPA') samples('Chinese', 'CHI')

Exercises
- Try with a different dataset of category -> line, for example:Use a “start of sentence” token so that sampling can be done without choosing a start letter
- Fictional series -> Character name
- Part of speech -> Word
- Country -> City
- Get better results with a bigger and/or better shaped network
- Try the nn.LSTM and nn.GRU layers
- Combine multiple of these RNNs as a higher level network
Total running time of the script: ( 6 minutes 39.119 seconds

 浙公网安备 33010602011771号
浙公网安备 33010602011771号