
Pythonの崎岖的进阶之路,Week_Two - Python基础
学习目录
1. 数据类型
2. 列表操作
3. 元祖操作
4. 字符串操作
5. 字典操作
6. 集合操作
7. 文件操作
一、数据类型
Python中变量不需要声明,但是变量在创建时必须赋值
在Python中变量没有数据类型,我们所说的"类型"是变量所指的内存中对象的类
Python中有六种标准数据类型
1. 不可变数据类型
- Number(数字)
- String(字符串)
- Tuple(元组)
2. 可变数据类型
- Set(集合)
- Dictionary(字典)
- List(列表)
Number
Python3支持 int、float、bool、complex(复数)
使用type函数类获取参数的数据类型:
>>>a, b, c, d = (7, 5.2, True, 2e3) >>>print(type(a), type(b), type(c), type(d)) <class 'int'> <class 'float'> <class 'bool'> <class 'float'>
String
Python中的字符串用单引号 ' 或双引号 " 括起来,同时使用反斜杠 \ 转义特殊字符。
>>>str = "abcdefg" >>>print(str) abcdefg
二、列表操作
列表数据类型是最常用的,可以通过操作列表实现对数据的存储、修改等操作
定义列表
names_list = ['gupeng', 'zhanglei', 'DeLi', 'Lucy', 'lili']
列表切片
通过列表下标访问列表中参数,下表从0开始
>>> names_list[0] 'gupeng' >>> names_list[-1] 'lili' >>> names_list[-2] 'Lucy'
取多个参数
>>> names_list[1:3] # 左闭右开,左侧包含开始位, 右侧不包含结束位 ['zhanglei', 'DeLi'] >>> names_list[1:-1] # 左闭右开,右侧不包括-1 ['zhanglei', 'DeLi', 'Lucy'] >>> names_list[-4:-1] ['zhanglei', 'DeLi', 'Lucy'] >>> names_list[:3] # 如果从头开始取到某一位,0可以省略 ['gupeng', 'zhanglei', 'DeLi'] >>> names_list[0:] # 如果一直取到最后一位,最后一位可以省略 ['gupeng', 'zhanglei', 'DeLi', 'Lucy', 'lili'] >>> names_list[:] # 取全部参数 效果等同names_list ['gupeng', 'zhanglei', 'DeLi', 'Lucy', 'lili'] >>> names_list[::2] # 所有参数,2代表步长,即每隔一位取一个数 ['gupeng', 'DeLi', 'lili'] >>> names_list[0:3:2] # 从0到3,每隔一位取一个 效果等于names_list[:3:2] ['gupeng', 'DeLi']
追加
>>> names_list
['gupeng', 'zhanglei', 'DeLi', 'Lucy', 'lili']
>>> names_list.append("mumu")
>>> names_list
['gupeng', 'zhanglei', 'DeLi', 'Lucy', 'lili', 'mumu']
插入
>>> names_list ['gupeng', 'zhanglei', 'DeLi', 'Lucy', 'lili', 'mumu'] >>> names_list.insert(2, "Judy") # 2标识插入位置,“Judy”是要插入的参数 >>> names_list ['gupeng', 'zhanglei', 'Judy', 'DeLi', 'Lucy', 'lili', 'mumu']
修改
>>> names_list ['gupeng', 'zhanglei', 'Judy', 'DeLi', 'Lucy', 'lili', 'mumu'] >>> names_list[2]="Nick" # 使用下标直接修改 >>> names_list ['gupeng', 'zhanglei', 'Nick', 'DeLi', 'Lucy', 'lili', 'mumu']
删除
>>> names_list
['gupeng', 'zhanglei', 'Nick', 'DeLi', 'Lucy', 'lili', 'mumu']
>>> names_list.remove("mumu") # 使用remove方法删除指定参数
>>> names_list
['gupeng', 'zhanglei', 'Nick', 'DeLi', 'Lucy', 'lili']
>>> del names_list[1] # 使用del方法通过下标删除
>>> names_list
['gupeng', 'Nick', 'DeLi', 'Lucy', 'lili']
>>> names_list.pop() # pop() 抛出最后一个参数
'lili'
>>> names_list
['gupeng', 'Nick', 'DeLi', 'Lucy']
>>> names_list.pop(1) # pop()通过下标删除指定参数
'Nick'
>>> names_list
['gupeng', 'DeLi', 'Lucy']
获取下标
>>> names_list = ['gupeng', 'zhanglei', 'DeLi', 'Lucy', 'lili']
>>> names_list.index("Lucy")
3
计数
>>> names_list = ['gupeng', 'zhanglei', 'DeLi', 'Lucy', 'lili', 'DeLi']
>>> names_list.count("DeLi")
2
翻转
>>> names_list.reverse() >>> names_list ['DeLi', 'lili', 'Lucy', 'DeLi', 'zhanglei', 'gupeng']
排序
>>> names_list = ['gupeng', 'zhanglei', 'DeLi', 'Lucy', 'lili', 'DeLi'] >>> names_list.sort() # 按字母顺序排序 >>> names_list ['DeLi', 'DeLi', 'Lucy', 'gupeng', 'lili', 'zhanglei'] >>> names_list = ['gupeng', 'zhanglei', '2DeLi', '1Lucy', '$$lili', 'DeLi','Zhangge'] >>> names_list.sort() # 特殊字符> 数字 > 大写> 小写 >>> names_list ['$$lili', '1Lucy', '2DeLi', 'DeLi', 'Zhangge', 'gupeng', 'zhanglei']
扩展
>>> names_list = ['gupeng', 'zhanglei', 'DeLi', 'Lucy', 'lili'] >>> names2=[1,2,3,4] >>> names_list.extend(names2) >>> names_list ['gupeng', 'zhanglei', 'DeLi', 'Lucy', 'lili', 1, 2, 3, 4]
拷贝(浅copy)
>>> names1 = ['gupeng', 'zhanglei', ['DeLi', 'Lucy', 'lili']]
>>> names2 = names1.copy() # 浅copy
>>> names2
['gupeng', 'zhanglei', ['DeLi', 'Lucy', 'lili']]
>>> names1[2].append('mumu')
>>> names1
['gupeng', 'zhanglei', ['DeLi', 'Lucy', 'lili', 'mumu']]
>>> names2
['gupeng', 'zhanglei', ['DeLi', 'Lucy', 'lili', 'mumu']]
深度copy
>>> import copy
>>> names1 = ['gupeng', 'zhanglei', ['DeLi', 'Lucy', 'lili']]
>>> names2 = copy.deepcopy(names1)
>>> names1, names2
(['gupeng', 'zhanglei', ['DeLi', 'Lucy', 'lili']],
['gupeng', 'zhanglei', ['DeLi', 'Lucy', 'lili']])
>>> names1[2].append("mumu")
>>> names1, names2
(['gupeng', 'zhanglei', ['DeLi', 'Lucy', 'lili', 'mumu']],
['gupeng', 'zhanglei', ['DeLi', 'Lucy', 'lili']])
解析赋值引用、浅copy、深copy
1. b = a: 赋值引用,a 和 b 都指向同一个对象。
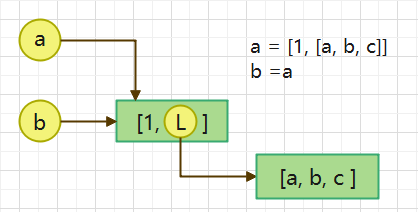
2. b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象
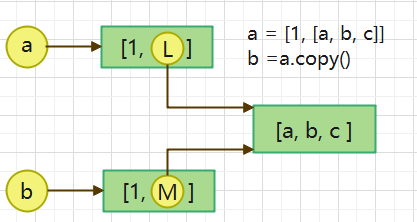
3. b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
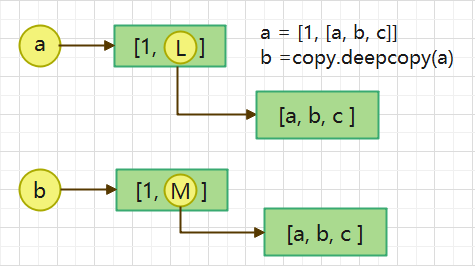
三、元组操作
元组与列表类似,但是元组一旦创建就不允许修改,所以又叫只读列表
names = ('DeLi', 'lili', 'Lucy', 'DeLi', 'zhanglei', 'gupeng')
元组只有两种方法,分别为count和index
>>> names = ('DeLi', 'lili', 'Lucy', 'DeLi', 'zhanglei', 'gupeng')
>>> names.count("DeLi")
2
>>> names.index("Lucy")
2
四、字符串操作
# -*- coding: utf-8 -*-
name = "my name is boxiaomu"
print(name.capitalize()) # 首字母大写
print(name.count("o")) # 统计
print(name.center(50, "_"))
print(name.endswith("mu")) # 判断字符串以什么结尾
name = "my \t name is boxiaomu"
print(name.expandtabs(tabsize=30)) # tab键转成tabsize个空格
print(name.find("name")) # 找到开头字符索引(字符串也可以切片)
print(name[name.find("name"):9]) # 字符串切片
name = "my name is {name} and i am {year} old "
print(name.format(name="boxiaomu", year=18))
print(name.format_map( {'name':'boxiaomu', 'year':'18'} ))
print(name.isalnum()) # 是否是阿拉伯数字和字符
print('a1A'.isidentifier()) # 判断是否是合法标识符
print(name.lower()) # 是否小写
print('33.33'.isnumeric()) # 判断是否是数字
print('1A'.isdigit()) # 是否是整数 常用
# join
print('+'.join(['1','2','3'] ) )
print(name.ljust(50,'*')) # 末尾补齐
print(name.rjust(50, '$'))
print('BOXIAOMU'.lower())
print('boxiaom'.upper())
print('\nBoxiaomu'.lstrip()) # 去掉左回车
print('\nBoxiaomu'.lstrip()) # 去掉右回车
print(' Boxioam\n'.strip()) # 去掉回车、空格
p = str.maketrans('abcdwef', '1234567') # 把字符串改成后边的数字(类似加密)
print('boxiaomu'. translate(p))
print('boxioamu'.replace('o', 'O', 1))
print('boxiao mu'.split()) # 字符串按空格分成列表
print('1+2+3+4'.split('+'))
print('1+2\n+3+4'.splitlines())
print('Yanru bo'.swapcase()) # 大小写翻转
print('xiaomu bo'.title())
print('xiaomu bo'.zfill(50))
运行结果
My name is boxiaomu
2
_______________my name is boxiaomu________________
True
my name is boxiaomu
6
nam
my name is boxiaomu and i am 18 old
my name is boxiaomu and i am 18 old
False
True
my name is {name} and i am {year} old
False
False
1+2+3
my name is {name} and i am {year} old ************
$$$$$$$$$$$$my name is {name} and i am {year} old
boxiaomu
BOXIAOM
Boxiaomu
Boxiaomu
Boxioam
2oxi1omu
bOxioamu
['boxiao', 'mu']
['1', '2', '3', '4']
['1+2', '+3+4']
yANRU BO
Xiaomu Bo
00000000000000000000000000000000000000000xiaomu bo
五、字典操作
查询操作
# key-value key尽量不写中文
>>> info = {
... 'stu1101':'xiaomu bao',
... 'stu1102': 'Shirley Yang',
... 'stu1103': 'shagua ce',
... }
>>> info['stu1101'] # 不存在则报错
'xiaomu bao'
使用get查询
>>> info.get('stu1101')
'xiaomu bao'
>>> info.get('stu1100') # 不存在不报错
setdefault()方法
>>> info.setdefault('stu1101', 'name')
'TengLan wu'
>>> info
{'stu1101': 'TengLan wu', 'stu1102': 'LongZe luala', 'stu1103': 'XiaoZe Mliya'}
>>> info.setdefault('stu1104','zhuli ye')
'zhuli ye'
>>> info
{'stu1101': 'TengLan wu', 'stu1102': 'LongZe luala', 'stu1103': 'XiaoZe Mliya', 'stu1104': 'zhuli ye'}
key in dict方法查询
>>> 'stu1004' in info 不存在返回False
False
>>> 'stu1101' in info 存在返回True
True
修改操作
>>> info
{'stu1101': 'xiaomu bao', 'stu1102': 'Shirley Yang', 'stu1103': 'shagua ce'}
>>> info['stu1101'] = 'muzi li'
>>> info
{'stu1101': 'muzi li', 'stu1102': 'Shirley Yang', 'stu1103': 'shagua ce'} # 字典中存在该键 则对该键值进行修改
>>> info['stu1104'] = 'doctor chen' # 字典中不存在该键, 则增加
>>> info
{'stu1101': 'muzi li', 'stu1102': 'Shirley Yang', 'stu1103': 'shagua ce', 'stu1104': 'doctor chen'}
删除操作
>>> info
{'stu1101': 'muzi li', 'stu1102': 'Shirley Yang', 'stu1103': 'shagua ce', 'stu1104': 'doctor chen'}
>>> del info['stu1104'] # 通用del删除方法
>>> info
{'stu1101': 'muzi li', 'stu1102': 'Shirley Yang', 'stu1103': 'shagua ce'}
>>> info.pop('stu1103') # 删除指定键值对
'shagua ce'
>>> info
{'stu1101': 'muzi li', 'stu1102': 'Shirley Yang'}
>>> info.popitem() # 删除最后一个键值对
('stu1102', 'Shirley Yang')
>>> info
{'stu1101': 'muzi li'}
多字典操作
## update 方法 合并两个字典,交叉覆盖,没有则创建
>>> b = {
... 'stu1101': 'alex',
... 1: 3,
... 2: 5
... }
>>> info.update(b)
>>> info
{'stu1101': 'alex', 'stu1102': 'LongZe luala', 'stu1103': 'XiaoZe Mliya', 'stu1104': 'zhuli ye', 1: 3, 2: 5}
初始化字典
>>> dic = dict.fromkeys([6,7,8], 'test')
>>> dic
{6: 'test', 7: 'test', 8: 'test'}
>>> dic1 = dict.fromkeys([4,5,6],['a',{'name':'Judy'},333])
>>> dic1
{4: ['a', {'name': 'Judy'}, 333], 5: ['a', {'name': 'Judy'}, 333], 6: ['a', {'name': 'Judy'}, 333]}
循环字典
info = {
'stu1101': 'xiaomu bao',
'stu1102': 'Shirley Yang',
'stu1103': 'shagua ce',
}
for i in info:
print(i, info[i])
for k, v in info.items(): # 效率低于上面
print(k, v)
字典转列表
>>> info.items()
dict_items([('stu1101', 'xiaomu bao'), ('stu1102', 'Shirley Yang'), ('stu1103', 'shagua ce')])
六、集合操作
集合是一个无序的,参数不重复的数据组合
list_1 = [1,4,5,7,3,6,7,9] list_1 = set(list_1) # 集合是无序的 去重
list_2 = set([2, 6, 0, 66, 22, 8, 4])
关系测试
# 取交集
>>> list_1.intersection(list_2)
{4, 6}
>>> list_1 & list_2
{4, 6}
# 取并集
>>> list_1.union(list_2)
{0, 1, 2, 3, 4, 5, 6, 7, 66, 9, 8, 22}
>>> list_1 | list_2
{0, 1, 2, 3, 4, 5, 6, 7, 66, 9, 8, 22}
# 取差集 in list_1 but not in list_2
>>> list_1.difference(list_2)
{1, 3, 5, 7, 9}
>>> list_1 - list_2
{1, 3, 5, 7, 9}
# 对称差集
>>> list_1.symmetric_difference(list_2) # 两个中互相都没有的
{0, 1, 2, 66, 3, 5, 8, 7, 9, 22}
>>> list_1 ^ list_2
{0, 1, 2, 66, 3, 5, 8, 7, 9, 22}
# 判断是否是子集
>>> list_3 = set([1,3,7])
>>> list_3.issubset(list_1)
True
# 判断是否是父集
>>> list_1.issuperset(list_3)
True
# 没有交集返回True
>>> list_2.isdisjoint(list_3)
True
基本操作
# 添加add
>>> list_1.add(999)
>>> list_1
{1, 3, 4, 5, 6, 7, 999, 9}
# 添加update
>>> list_1.update([888,777,555])
>>> list_1
{1, 3, 4, 5, 6, 7, 999, 9, 777, 555, 888}
# 删除
>>> list_1.remove(1) # 不存在报错
>>> list_1
{3, 4, 5, 6, 7, 999, 9, 777, 555, 888}
>>> list_1.discard(1) # 不存在不报错
>>> list_1
{3, 4, 5, 6, 7, 999, 9, 777, 555, 888}
>>> list_1.pop()
3
>>> list_1
{4, 5, 6, 7, 999, 9, 777, 555, 888}
七、文件操作
文件操作流程
1. 打开文件,得到文件句柄,并赋值给一个变量
2. 通过变量对文件进行读写等操作
3. 关闭文件
打开文件方式
- r: 只读方式打开,默认方式,只能读取文件
- w:只写方式打开,不可读文件,【文件不存在则创建,存在则删除内容重新写入】
- a:只追加写方式打开,可读文件,【不存在则创建,存在则在文件末尾开始追加写内容】
# 读取文件 返回整个文件内容
open('yesterday') # open file
date = open('yesterday', encoding='utf-8').read() # windows 默认格式gbk,
#python默认utf-8, 不指定编码方式则用gbk打开
# 通过句柄变量read
f = open('yesterday', encoding='utf-8') # 赋给f 文件句柄/内存对象(文件名,字符集,
# 大小,起始位置)
data = f.read()
print(data)
# 以 “r” 只读方式打开
f = open('yesterday', 'r', encoding='utf-8')
# 以“w”只写方式打开
f = open('yesterday', 'w', encoding='utf-8') # 'w'创建新的 把原来的覆盖掉
f.write('天安门前太阳升')
# 以“a”追加方式打开
f = open('yesterday', 'a', encoding='utf-8') # 'a' 追加
f.write("\n拉拉拉拉啊啦啦,\n")
f.close() # 关闭文件
“+”表示同时可读写文件
- “r+”:可读写文件,【可读,可写,可追加】
- “w+”:可写读文件
- “a+”:可读写文件,【可读,可写,可追加】
# 读写(追加)
f = open('yesterday2', 'r+', encoding='utf-8')
# 写读(先创建再写 write都是在最后追加)
f = open('yesterday2', 'w+', encoding='utf-8')
# 追加读
f = open('yesterday2', 'a+', encoding='utf-8')
# 二进制模式读文件
f = open('yesterday2', 'rb')
with语句
为避免文件操作后忘记关闭,可以通过with语句来实现执行完成后,内部自动关闭并释放文件资源
with open("yesterday2", "r", encoding="utf-8") as f:
pass
with open("yesterday2", "r", encoding="utf-8") as f, \
open("yesterday2", "r", encoding="utf-8") as f2: # python3支持
pass
循环读取文件,写入内容
# 读到第十行时不打印
for index, line in enumerate(f.readlines()):
if index == 9:
print('---')
continue
print(line.strip())
# f 迭代器
count = 0
for line in f:
if count == 9:
print('------------分割线---------------')
count +=1
continue
print(line.strip())
count +=1
使用flush实时刷新到内存
import sys
import time
# 进度条
for i in range(20):
sys.stdout.write("#")
sys.stdout.flush()
time.sleep(0.2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号