
Hive 常用函数
参考地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
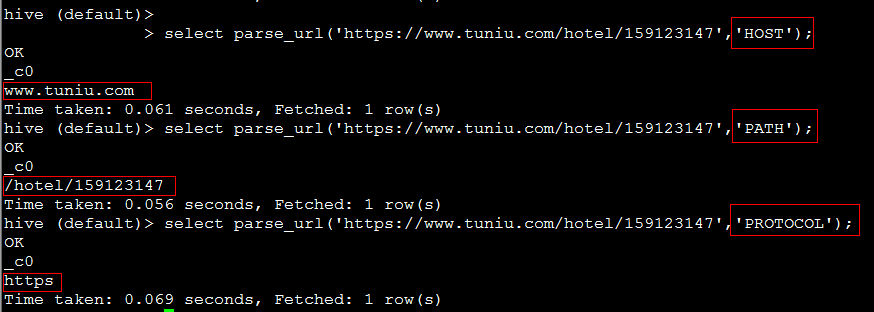
1. parse_url(url, partToExtract[, key])
2. concat(str1,SEP,str2,SEP,str3,……) 和 concat_ws(SEP,str1,str2,str3, ……)
字符串连接函数,需要是 string型字段。
如果4个字段,想得到如下结果,看下两个函数的区别:
eg: 
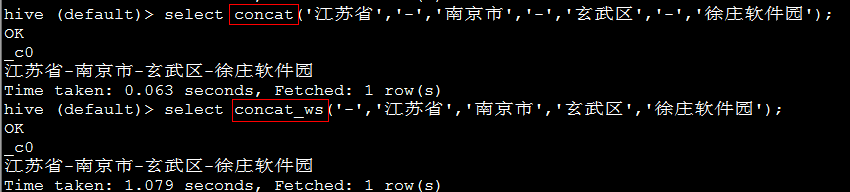
代码1: select concat('江苏省','-','南京市','-','玄武区','-','徐庄软件园');
代码2: select concat_ws('-','江苏省','南京市','玄武区','徐庄软件园');
结论:当连接的内容(字段)多于2个的时候,concat_ws的优势就显现了,写法简单、方便。
3. unix_timestamp() 当前系统时间
unix_timestamp() 是将当前系统时间转换成数字型秒数,from_unixtime 将数字型按照 格式进行时间转换。
eg:
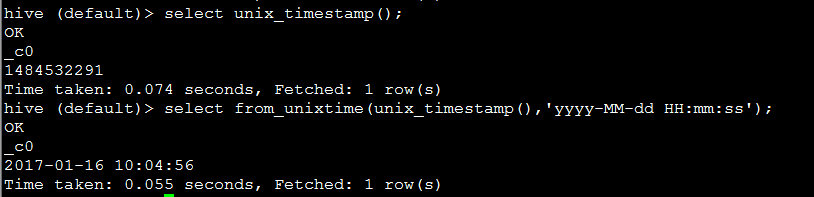
代码:select from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss');
4. regexp_replace(string A, string B, string C) 字符串替换函数,将字符串A 中的B 用 C 替换。
eg: 
代码:select regexp_replace('www.tuniu.com','tuniu','jd');
5. repeat(string str, int n) 重复N次字符串
eg: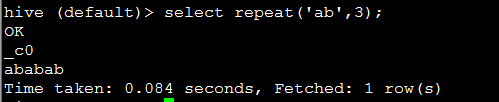
代码:select repeat('ab',3);
6. lpad(string str, int len, string pad) 将字符串str 用pad进行左补足 到len位(如果位数不足的话)
eg: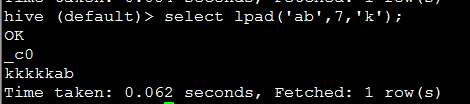
代码:select lpad('ab',7,'k');
7. rpad(string str, int len, string pad) 将字符串str 用pad进行右补足 到len位(如果位数不足的话)
eg:
代码:select rpad('ab',7,'k');
8. trim(string A) 删除字符串两边的空格,中间的会保留。
相应的 ltrim(string A) ,rtrim(string A)
eg: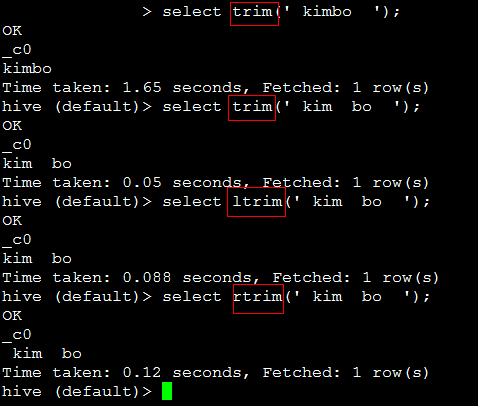
9. to_date(string timestamp) 将时间戳转换成日期型字符串
eg:
代码:select to_date('2017-01-16 09:55:54');
10. datediff(string enddate, string startdate) 返回int 的两个日期差
eg:
代码:select datediff('2017-01-16', '2017-01-10');
11. date_add(string startdate, int days) 日期加减
eg: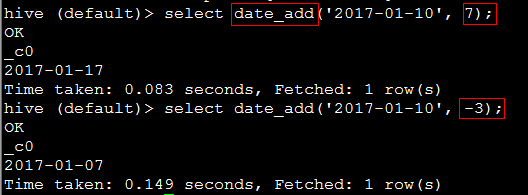
代码:select date_add('2017-01-10', 7);
12. current_timestamp 和 current_date 返回当前时间戳,当前日期
eg: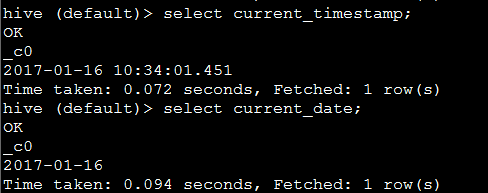
13. date_format(date/timestamp/string ts, string fmt) 按照格式返回字符串
eg: 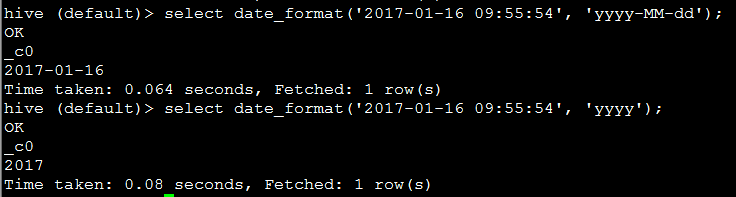
代码:select date_format('2017-01-16 09:55:54', 'yyyy-MM-dd');
14. last_day(string date) 返回 当前时间的月末日期
eg:
代码:select last_day('2017-01-16 09:55:54');
15. if(boolean testCondition, T valueTrue, T valueFalseOrNull) ,根据条件返回不同的值
eg: 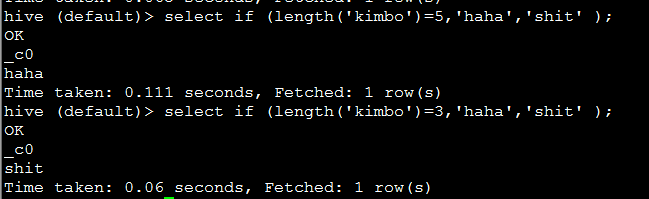
16. nvl(T value, T default_value) 如果T is null ,返回默认值
17. length(string A) 返回字符串A的长度
eg: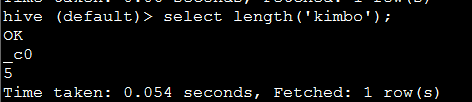
代码:select length('kimbo');
18. greatest(T v1, T v2, ...) 返回最大值,会过滤null
eg: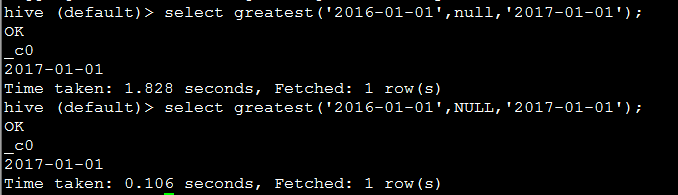
代码:select greatest('2016-01-01',NULL,'2017-01-01');
19. least(T v1, T v2, ...) 返回最小值,会过滤null
eg: 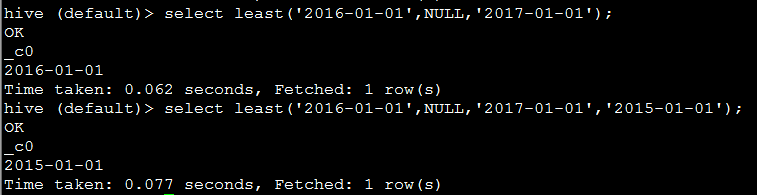
代码:select least('2016-01-01',NULL,'2017-01-01','2015-01-01');
20. rand(), 返回0-1的随机值。rand(INT seed) 返回固定的随机值。
eg: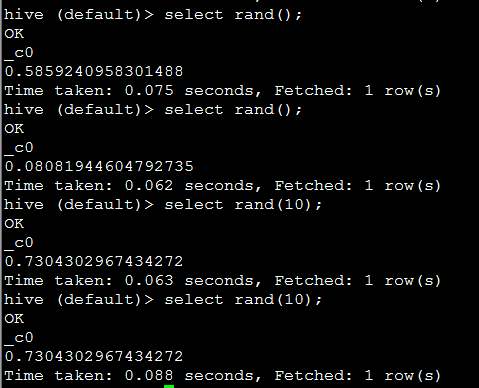
21. md5(string/binary) hive 1.3以上版本,返回md5码
22. split(str, regex) ,安装规则截取字符串,返回数组
eg: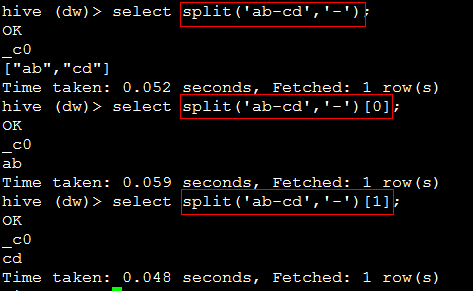
代码:select split('ab-cd','-')[0];
如果是特殊字段,需要转义,如:select split('大阪酒店|$新丽饭店','\\|\\$')[0];
23. rlike ,正则表达式
eg: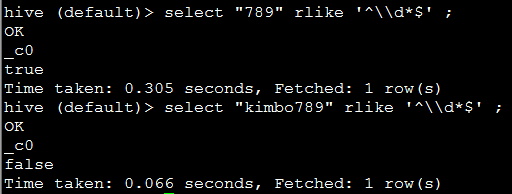
代码:select "kimbo789" rlike '^\\d*$' ;
说明:匹配全数字的字符串
------------------------传送门------------------------


 浙公网安备 33010602011771号
浙公网安备 33010602011771号