数据采集_第一次大作业
作业一
-
要求:使用用
urllib和re库方法定向爬取给定网址中国最好学科排名(计算机科学与技术)的数据。 -
输出形式:
| 2020排名 | 全部层次 | 学校类型 | 总分 |
|---|---|---|---|
| 1 | 前2% | 中国人民大学 | 1069.0 |
| 2 | .... | ........... | ...... |
具体实现如下:
1.1获取HTML文件
def GetHTML(url): try: http = urllib.request.urlopen(url) data = http.read()#得到返回的网页内容 data = data.decode() data = data.replace("\n", "") return data except Exception as err: print(err)
1.2正则匹配获取需要信息
准备工作:在爬取的相关页面使用浏览器F12功能找到需要爬取的信息,根据需要信息的格式不同使用相应的正则匹配,如果目录信息足够详细的话也可以直接使用(.*?)直接匹配
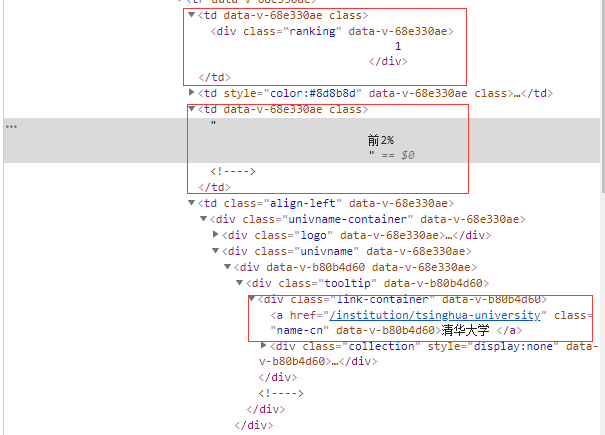
def fillunilist(ulist,html):
ranks = re.findall(r'class="ranking" data-v-68e330ae>(.*?)</div>',html,re.M|re.S)
levels = re.findall(r'<td data-v-68e330ae>.*?([\u4e00-\u9fa5].*?%).*?</td>',html,re.M|re.S)
names = re.findall(r'class="name-cn" data-v-b80b4d60>(.*?)</a>', html, re.M | re.S)
scores = re.findall(r'<!----> <!----> <!----> <!----></div></div></td><td data-v-68e330ae>(.*?)</td>',html)
for i in range(len(ranks)):
rank = ranks[i].strip()#去除空格或其他字符
level = levels[i].strip()
name = names[i].strip()
score = scores[i].strip()
ulist.append([rank,level,name,score])
1.3打印函数
中英混排时,使用chr(12288)字符进行填充
def printUList(ul): tplt = "{0:^10}{1:{4}^15}{2:{4}^25}{3:^10}"#{4}用第五个参数chr(12288)进行填充 print(tplt.format("2020排名", "全部层次", "学校类型", "总分", chr(12288))) for i in range(0,30): u = ul[i] print(tplt.format(u[0], u[1], u[2], u[3], chr(12288)))
1.4成果截图

心得体会
正则表达式使用起来多样灵活,具有很多的可变性,但是也非常容易出错,使用起来要小心谨慎
代码地址
https://gitee.com/kilig-seven/crawl_project/blob/master/%E7%AC%AC%E4%B8%80%E6%AC%A1%E5%A4%A7%E4%BD%9C%E4%B8%9A/%E4%BD%9C%E4%B8%9A%E4%B8%80.py
作业二
-
要求 用requests和Beautiful Soup库方法设计爬取(https://datacenter.mee.gov.cn/aqiweb2/ )AQI实时报。
-
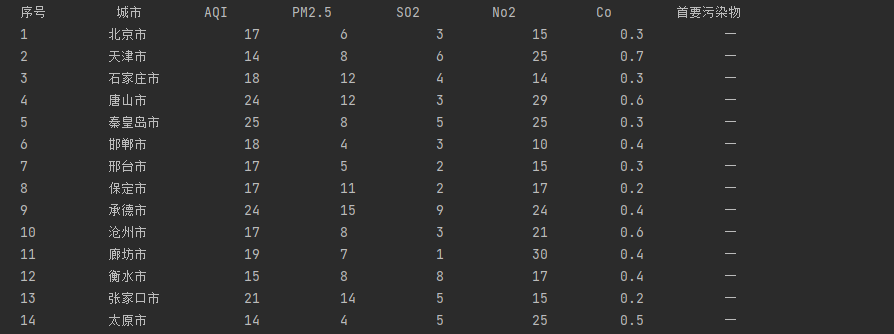
输出信息
序号 城市 AQI PM2.5 SO2 No2 Co 首要污染物 1 北京 55 6 5 1.0 225 — 2......
具体实现如下:
准备工作,找到需要爬取信息所在的目录

1.1获取HTML
def getHTML(url): try: headers = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} r = requests.get(url, timeout=30, headers = headers) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "产生异常"
1.2获取信息
def getData(html): try: soup = BeautifulSoup(html,'lxml') data = soup.select('td[style="text-align: center; "]')#通过F12功能找到需要信息所处的目录下 return data except Exception as err: print(err)
1.3打印函数
def printData(data): tplt = "{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}" print(tplt.format("序号", "城市", "AQI", "PM2.5", "SO2", "No2", "Co", "首要污染物")) k=1 for i in range(0, len(data), 9): print(tplt.format(k, data[i].text, data[i+1].text, data[i+2].text, data[i+4].text, data[i+5].text, data[i+6].text, data[i+8].text.strip())) k+=1
1.4结果展示
心得体会:
BeautifulSoup拥有强大的查找功能,在许多条件下比re正则来的更加方便快捷
在使用requests获取HTML网页时,通常需要加上headers作为头,防止网页将爬虫屏蔽
代码地址
https://gitee.com/kilig-seven/crawl_project/blob/master/%E7%AC%AC%E4%B8%80%E6%AC%A1%E5%A4%A7%E4%BD%9C%E4%B8%9A/request%20col.py
作业三
- 要求:使用urllib和requests爬取(http://news.fzu.edu.cn/),并爬取该网站下的所有图片
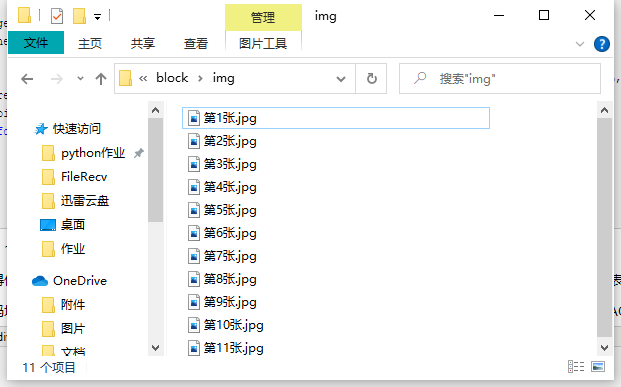
- 输出信息:将网页内的所有图片文件保存在一个文件夹中
具体实现如下:
1.1获取HTML
def getHTML(url): try: headers = { "Referer": "Referer: http://news.fzu.edu.cn/", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36", } req = requests.get(url, headers=headers) req.raise_for_status() req.encoding = req.apparent_encoding return req.text except Exception as err: print(err)
1.2正则匹配+保存图片文件
def getimage(html): headers = { "Referer": "Referer: http://news.fzu.edu.cn/", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36", } reg = 'src="(.*?).jpg"'#找到所有后缀是jpg的文件 pic_path = re.compile(reg).findall(html)#找到所有jpg图片所在路径 for i in range(len(pic_path)): picURL = "http://news.fzu.edu.cn/"+str(pic_path[i]) img = requests.get(picURL, headers=headers) with open('img/' + f"第{i+1}张.jpg", 'wb') as file: file.write(img.content)
1.3结果展示
心得体会:在爬取一个网站所有的图片文件时,正则表达式便拥有了BeautifulSoup所没有的优点,正则表达式可以无视图片的名称只关注后缀从而爬取网页上的所有有关内容
代码地址:https://gitee.com/kilig-seven/crawl_project/blob/master/%E7%AC%AC%E4%B8%80%E6%AC%A1%E5%A4%A7%E4%BD%9C%E4%B8%9A/re%20picture.py
