Claude 3.7 到 Claude 4:我更关心的是 Claude Code 这条线
Claude 3.7 到 Claude 4:我更关心的是 Claude Code 这条线
最近翻 Anthropic 的几篇更新,把 Claude 3.7 Sonnet、Claude 4 以及 Claude Code 的最佳实践串起来看了一遍。
如果只看发布标题,感觉就是“又发了新模型”。但把几篇内容连起来看,会发现 Anthropic 真正想推的东西不只是模型本身,而是让 Claude 更深入地参与软件开发流程:看代码、改代码、跑命令、做验证,甚至在一个任务里持续推进很多步。
这篇主要聊一下我觉得对开发者有用的部分。

Claude 3.7 Sonnet:一个模型里同时做快答和慢想
Claude 3.7 Sonnet 是 2025 年 2 月 24 日发布的。当时 Anthropic 给它的关键词是“hybrid reasoning model”,也就是混合推理模型。
这个说法听起来有点抽象,换成开发者能理解的话就是:同一个模型既可以像普通聊天模型一样快速回答,也可以在复杂问题上花更长时间推理。

这件事其实挺实用。平时问一个简单 API 用法,不需要模型长篇推理;但如果是排查一个复杂 bug、设计一个迁移方案,或者让模型理解一段陌生代码,确实需要它多想一会。
我比较喜欢它的设计点在于,Anthropic 没有把“普通模型”和“推理模型”拆成两个入口,而是让同一个模型根据任务切换工作方式。对用户来说少了一层选择负担,对 API 用户来说也能在延迟、成本和效果之间调节。
Claude 3.7 之后,Claude Code 开始冒头
Claude 3.7 发布时一起出现的,还有 Claude Code。那时候它还是 research preview,但方向已经很明确:让 Claude 直接进到开发者的终端里干活。
这个定位和普通代码助手不太一样。
很多代码工具更像是“你问一句,它补一段”。Claude Code 的目标更接近“你给一个任务,它自己去项目里找文件、读上下文、修改代码、跑测试,然后根据结果继续修”。
举个简单例子,过去我们可能会这样用 AI:
这个登录 bug 怎么修?
然后把错误日志、代码片段贴进去,等它给建议,再自己复制、改、跑测试。
Claude Code 更适合这样用:
用户 session 过期后重新登录会失败。
请检查 src/auth 相关逻辑,先说明原因,再写一个复现测试,最后修复并运行测试。
这两种用法的差别很大。前者是问答,后者已经接近把一段工程任务交给它处理。
Claude 4:重点还是编码、推理和 Agent
到了 2025 年 5 月 22 日,Anthropic 发布 Claude 4。主要有两个模型:
- Claude Opus 4:更强,适合复杂任务、长时间执行、高难度编码。
- Claude Sonnet 4:更偏日常使用,成本和速度更适合高频调用。
官方对 Claude 4 的介绍里,反复出现几个词:coding、advanced reasoning、AI agents。也就是说,它不是单纯为了聊天体验升级,而是明显在往“能做事的模型”上走。
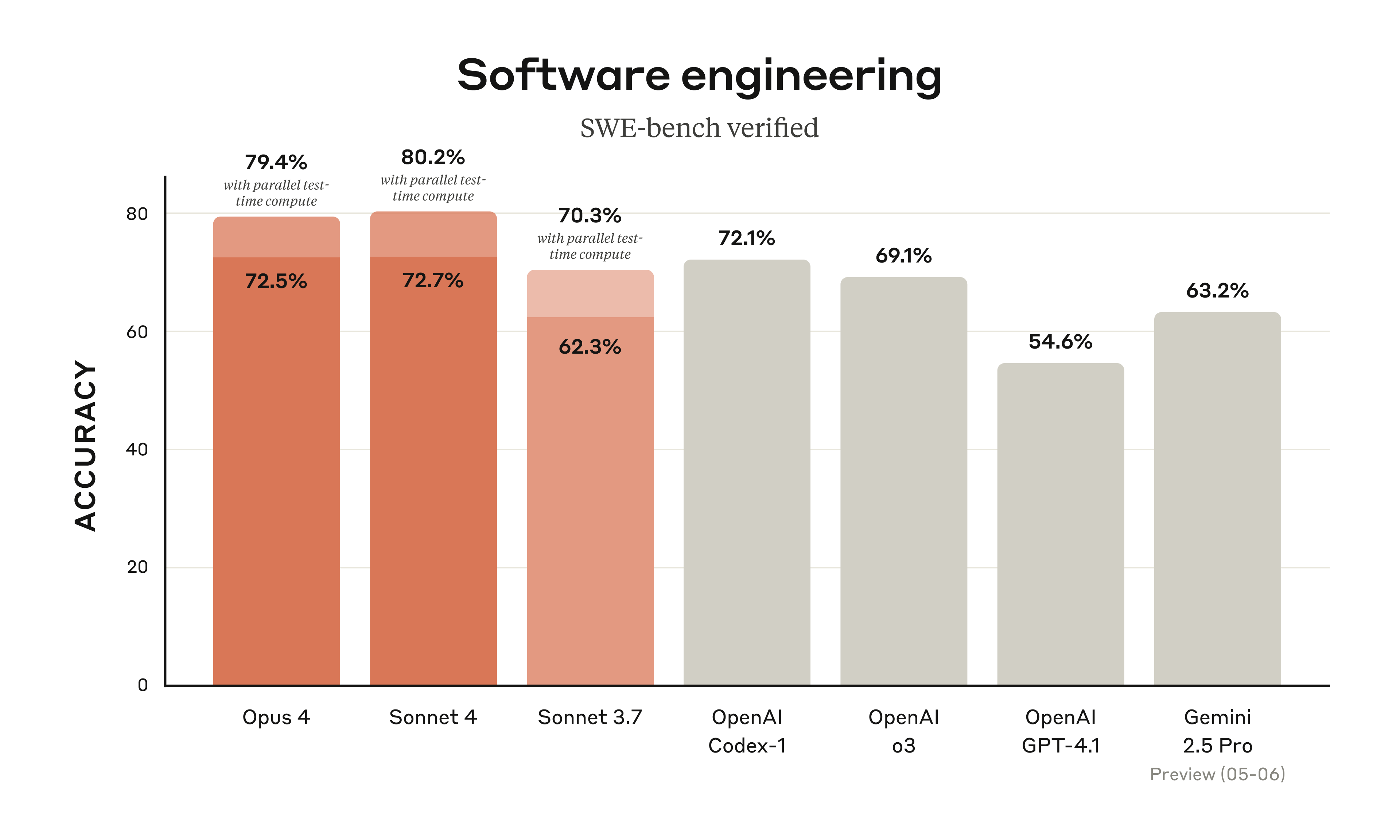
Claude Opus 4 官方给的定位很高,尤其强调它在 SWE-bench、Terminal-bench 这类编码相关 benchmark 上表现不错,也更适合需要连续执行很多步骤的任务。
Claude Sonnet 4 则更像日常主力。不是每个任务都需要最强模型,很多时候我们只是想快速理解代码、补测试、改一个小功能,这类场景 Sonnet 反而更合适。
Claude 4 里几个值得注意的点
1. 思考过程中可以调用工具
Claude 4 支持在扩展思考过程中使用工具,比如 Web Search。这个能力对 Agent 很重要。
原因很简单:真实任务很少只靠模型脑子里的知识完成。开发时要查文档,排障时要看日志,做数据分析要跑查询,写代码还要跑测试。如果模型能一边推理一边拿工具补信息,它就更像一个真正的执行者。
2. 工具调用更适合并行任务
官方也提到 Claude 4 在并行工具调用方面有改进。
这点听起来不如“模型更聪明”那么吸引人,但对 Agent 很关键。比如一次代码审查里,它可能需要同时看路由、数据库模型、权限逻辑和测试文件。如果只能串行处理,效率会很低。
3. 本地文件里的“记忆”更有用
Claude 4 还强调了在访问本地文件时,可以更好地提取和保存关键事实。
我理解这件事更像是项目连续性的增强。大型项目里,很多知识并不在 README 里,而是散落在代码、脚本、约定和历史实现里。模型如果能慢慢积累这些信息,下一次处理同类任务时就不必完全从零开始。
当然,这也意味着要更注意权限和边界。能读本地文件是能力,也是风险。
4. Claude Code 正式可用
Claude 4 发布时,Claude Code 也从预览走向正式可用,并开始支持 GitHub Actions、VS Code、JetBrains 等集成。
这一步挺关键。Claude Code 如果只停留在终端里,更多是高级玩家工具;接入 IDE、CI、PR 流程之后,它就能进入团队日常开发链路。
Claude Code 不是“更会聊天的代码助手”
Claude Code 官方文档里有一句话很重要:它是 agentic coding environment。
这句话可以不用翻得太玄乎。我的理解是:它不是让你和模型一问一答,而是让模型在一个真实代码环境里完成任务。
普通聊天式用法大概是:
- 我把问题描述给 AI。
- AI 给我一段解释或代码。
- 我自己复制、运行、修错。
- 出错后再回来继续问。
Claude Code 的理想用法更像:
- 我说明目标和验收标准。
- 它自己读项目文件。
- 它提出方案。
- 它修改代码。
- 它运行测试或构建。
- 它根据失败结果继续改。
- 最后告诉我改了什么、怎么验证的。
这个区别决定了提示方式也要变。不要只问“怎么写”,而是要给它目标、范围和验证方式。
用 Claude Code 时,我觉得最重要的几条经验
下面这些主要来自官方最佳实践,我按自己的理解重新整理了一下。
1. 一定要给它可验证的标准
如果只说:
实现一个邮箱校验函数。
它可能会写出一段看起来还行的代码,但到底对不对,还得你自己判断。
更好的写法是:
实现 validateEmail 函数,并补充测试:
user@example.com 返回 true;
invalid 返回 false;
user@.com 返回 false。
实现后运行测试,失败就继续修。
这里的重点不是 prompt 写得多漂亮,而是给了它一个能自己检查的闭环。
可验证标准可以是很多东西:
- 单元测试
- 构建命令
- lint 或 typecheck
- 一个脚本的输出
- 浏览器截图
- API 请求结果
没有验证时,Claude 只能说“我认为完成了”。有验证时,它可以把失败信息读回来继续修。这个差别非常大。
2. 大任务别急着让它直接改
小改动可以直接让它上手,比如改个文案、补个日志、修一个明显的类型错误。
但如果是跨模块改动,我更建议先让它探索,再让它计划,最后再写代码。
可以这样开始:
先阅读 src/auth 目录,理解登录态和 session 的处理方式。
不要修改代码,先总结现有流程和可能的问题点。
然后再问:
我想加入 Google OAuth 登录。
请列出需要修改的文件、数据流、测试方案和风险点。
确认方案没跑偏之后,再让它实现:
按上面的方案实现。
补充 callback handler 的测试,运行相关测试并修复失败项。
这一步看似慢,其实能省很多返工。模型最麻烦的不是写错一行代码,而是方向理解错了还一口气改了很多文件。
3. 控制上下文,别把一个会话聊成一锅粥
Claude Code 会把对话、读过的文件、命令输出、错误日志都放进上下文里。上下文越满,模型越容易丢重点。
我的理解是:一个会话最好只服务一个相对完整的任务。
几个实用习惯:
- 不相关任务之间用
/clear。 - 长任务中用
/compact压缩上下文。 - 不要让它无边界地“扫描整个项目看看有什么问题”。
- 大范围调查时,用 subagent 或单独会话。
- 项目长期规则写进
CLAUDE.md,不要每次靠口头提醒。
CLAUDE.md 可以写项目里真正需要长期记住的东西,比如:
# Code style
- 使用 ES modules,不使用 CommonJS
- 优先解构导入
# Workflow
- 一组代码修改完成后运行 typecheck
- 优先运行相关单测,不默认跑完整测试套件
这个文件不要写成项目百科。越长越容易失效。只放那些“忘了就会出错”的规则就够了。
4. 权限和工具要提前想清楚
Claude Code 能读文件、改文件、跑命令,这些能力很方便,但也不能完全放飞。
比较稳的做法是:
- 常用安全命令可以加入权限白名单,比如测试、格式化、lint。
- 高风险环境用沙箱限制文件和网络访问。
- 需要连接外部系统时,通过 MCP 接入,比如 issue、数据库、Figma、监控。
- 必须每次执行的动作,用 hooks 固化,比如每次编辑后自动格式化。
这里有个简单区分:
CLAUDE.md适合写偏好和约定。- hooks 适合写必须执行的动作。
- MCP 负责连接外部工具。
- skills 适合封装重复工作流。
- subagents 适合做独立调查或审查。
5. 大改完之后,让另一个上下文审一遍
Claude Code 完成一个比较大的 diff 后,我会倾向于让一个新的上下文再看一遍。
比如:
使用子代理审查当前 diff。
只关注正确性、边界情况、安全风险和是否满足需求。
不要提出纯风格偏好。
这里的重点是“新上下文”。刚写完代码的那个会话,多少会沿着自己的思路往下走;新的 reviewer 更容易站在结果角度看问题。
当然也不用把每个建议都照单全收。审查 prompt 最好限制清楚,只看影响正确性和需求完成度的问题,不然很容易变成无止境优化。
Sonnet 和 Opus 怎么选
如果只是日常开发,我觉得 Sonnet 更像默认选择:解释代码、补测试、小功能、简单重构,都比较适合。
Opus 更适合那些“多想一会比较值”的任务,比如:
- 大型重构
- 跨模块设计
- 疑难 bug
- 长时间 Agent 任务
- 需要多轮验证的复杂实现
Claude Code 则不是某个模型的替代品,而是工作方式的变化。它让模型从“给建议”走到“进项目里执行”。
最后说两句
看完这几篇官方内容,我最大的感受是:AI 编程工具正在从代码生成,往工程执行靠近。
以前我们更关心“模型能不能写出一段代码”。现在更应该关心的是:
- 它能不能读懂现有项目?
- 它能不能按约束改动?
- 它能不能自己运行测试?
- 它能不能根据失败继续修?
- 它能不能给出清楚的验证证据?
对开发者来说,接下来要练的可能不是背更多 prompt 模板,而是学会给 Agent 搭一个好工作台:范围清楚、上下文干净、命令可跑、权限可控、验收标准明确。
模型会越来越强,但工程里真正有用的,还是能落到“改了什么、怎么验证、有没有风险”这些具体问题上。
参考链接
- Claude 3.7 Sonnet and Claude Code
https://www.anthropic.com/news/claude-3-7-sonnet - Introducing Claude 4
https://www.anthropic.com/news/claude-4 - Best practices for Claude Code
https://code.claude.com/docs/en/best-practices

 浙公网安备 33010602011771号
浙公网安备 33010602011771号