


懂得取舍才是缓存设计的真谛
Previously
前两篇文章(缓存稳定性 和 缓存正确性)跟大家讨论了缓存的『稳定性』和『正确性』,缓存常见问题还剩下『可观测性』和『规范落地&工具建设』
- 稳定性
- 正确性
- 可观测性
- 规范落地和工具建设
上周文章发完之后,很多同学对我留的问题进行了深入的讨论,我相信经过深度的思考,会让你对缓存一致性的理解更加深刻!

首先,各个 Go 群和 go-zero 群里有很多的讨论,但是大家也都没有找到非常满意的答案。
让我们来一起分析一下这个问题的几种可能解法:
-
利用分布式锁让每次的更新变成一个原子操作。这种方法最不可取,就相当于自废武功,放弃了高并发能力,去追求强一致性,别忘了我之前文章强调过『这个系列文章只针对非追求强一致性要求的高并发场景,金融支付等同学自行判断』,所以这种解法我们首先放弃。
-
把 A删除缓存 加上延迟,比如过1秒再执行此操作。这样的坏处是为了解决这种概率极低的情况,而让所有的更新在1秒内都只能获取旧数据。这种方法也不是很理想,我们也不希望使用。
-
把 A删除缓存 这里改成设置一个特殊占位符,并让 B设置缓存 用 redis 的
setnx指令,然后后续请求遇到这个特殊占位符时重新请求缓存。这个方法相当于在删除缓存时加了一种新的状态,我们来看下图的情况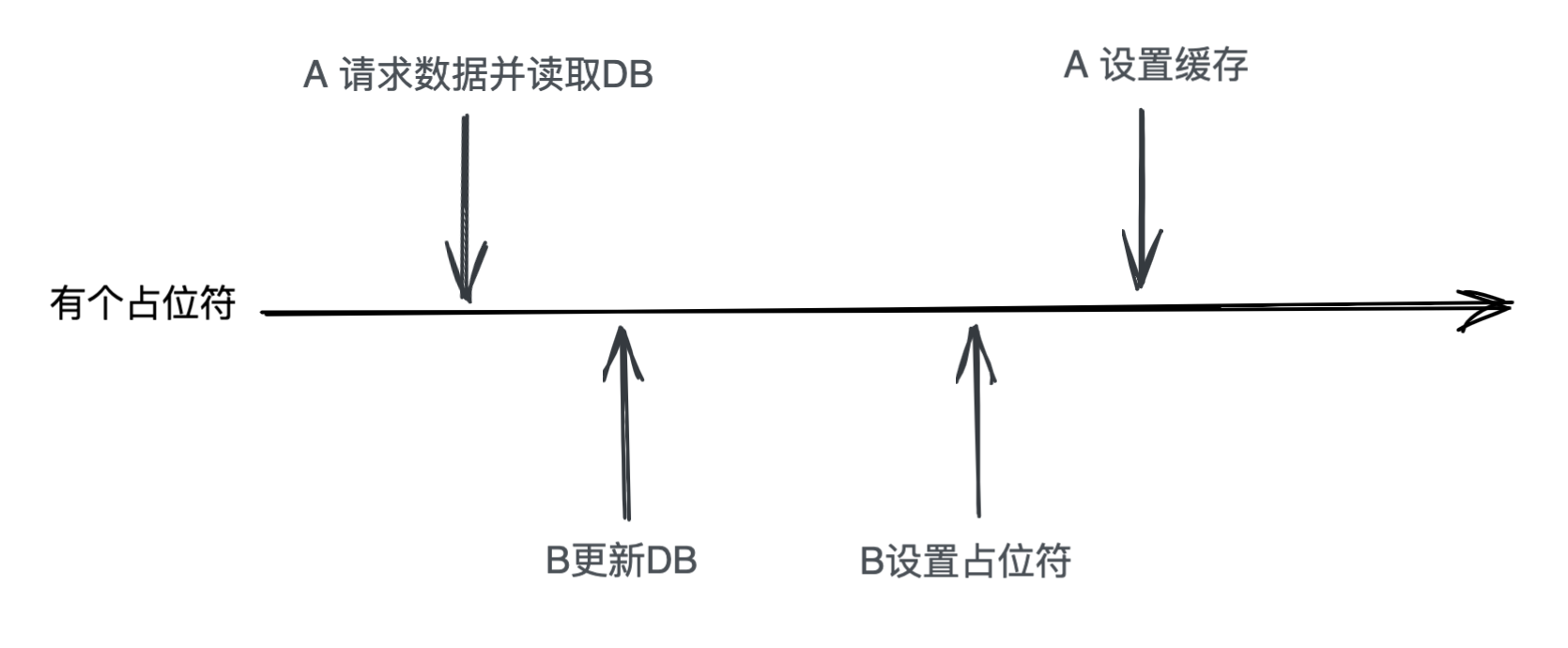
是不是又绕回来了,因为A请求在遇到占位符时必须强行设置缓存或者判断是不是内容为占位符。所以这也解决不了问题。
那我们看看 go-zero 是怎么应对这种情况的,我们选择对这种情况不做处理,是不是很吃惊?那么我们回到原点来分析这种情况是怎么发生的:
- 对读请求的数据没有缓存(压根没加载到缓存或者缓存已失效),触发了DB读取
- 此时来了一个对该数据的更新操作
- 需要满足这样的顺序:B请求读DB -> A请求写DB -> A请求删除缓存 -> B请求设置缓存
我们都知道DB的写操作需要锁行记录,是个慢操作,而读操作不需要,所以此类情况相对发生的概率比较低。而且我们有设置过期时间,现实场景遇到此类情况概率极低,要真正解决这类问题,我们就需要通过 2PC 或是 Paxos 协议保证一致性,我想这都不是大家想用的方法,太复杂了!
做架构最难的我认为是懂得取舍(trade-off),寻找最佳收益的平衡点是非常考验综合能力的。当然,如果大家有什么好的想法,可以通过群或者公众号联系我,感谢!
本文作为系列文章第三篇,主要跟大家探讨『缓存监控和代码自动化』
缓存可观测性
前面两篇文章我们解决了缓存的稳定性和数据一致性问题,此时我们的系统已经充分享受到了缓存带来的价值,解决了从零到一的问题,那么我们接下来要考虑的是如何进一步降低使用成本,判断哪些缓存带来了实际的业务价值,哪些可以去掉,从而降低服务器成本,哪些缓存我需要增加服务器资源,各个缓存的 qps 是多少,命中率多少,有没有需要进一步调优等。

上图是一个服务的缓存监控日志,可以看出这个缓存服务的每分钟有5057个请求,其中99.7%的请求都命中了缓存,只有13个落到DB了,DB都成功返回了。从这个监控可以看到这个缓存服务把DB压力降低了三个数量级(90%命中是一个数量级,99%命中是两个数量级,99.7%差不多三个数量级了),可以看出这个缓存的收益是相当可以的。
但如果反过来,缓存命中率只有0.3%的话就没什么收益了,那么我们就应该把这个缓存去掉,一是可以降低系统复杂度(如非必要,勿增实体嘛),二是可以降低服务器成本。
如果这个服务的 qps 特别高(足以对DB造成较大压力),那么如果缓存命中率只有50%,就是说我们降低了一半的压力,我们应该根据业务情况考虑增加过期时间来增加缓存命中率。
如果这个服务的 qps 特别高(足以对缓存造成较大压力),缓存命中率也很高,那么我们可以考虑增加缓存能够承载的 qps 或者加上进程内缓存来降低缓存的压力。
所有这些都是基于缓存监控的,只有可观测了,我们才能做进一步有针对性的调优和简化,我也一直强调『没有度量,就没有优化』。
如何让缓存被规范使用?
了解 go-zero 设计思路或者看过我的分享视频的同学可能对我经常讲的『工具大于约定和文档』有印象。
对于缓存来说,知识点是非常繁多的,每个人写出的缓存代码一定会风格迥异,而且所有知识点都写对是非常难的,就像我这种写了那么多年程序的老鸟来说,一次让我把所有知识点都写对,依然是非常困难的。那么 go-zero 是怎么解决这个问题的呢?
- 尽可能把抽象出来的通用解决方法封装到框架里。这样整个缓存的控制流程就不需要大家来操心了,只要你调用正确的方法,就没有出错的可能性。
- 把从建表 sql 到 CRUD + Cache 的代码都通过工具一键生成。避免了大家去根据表结构写一堆结构和控制逻辑。
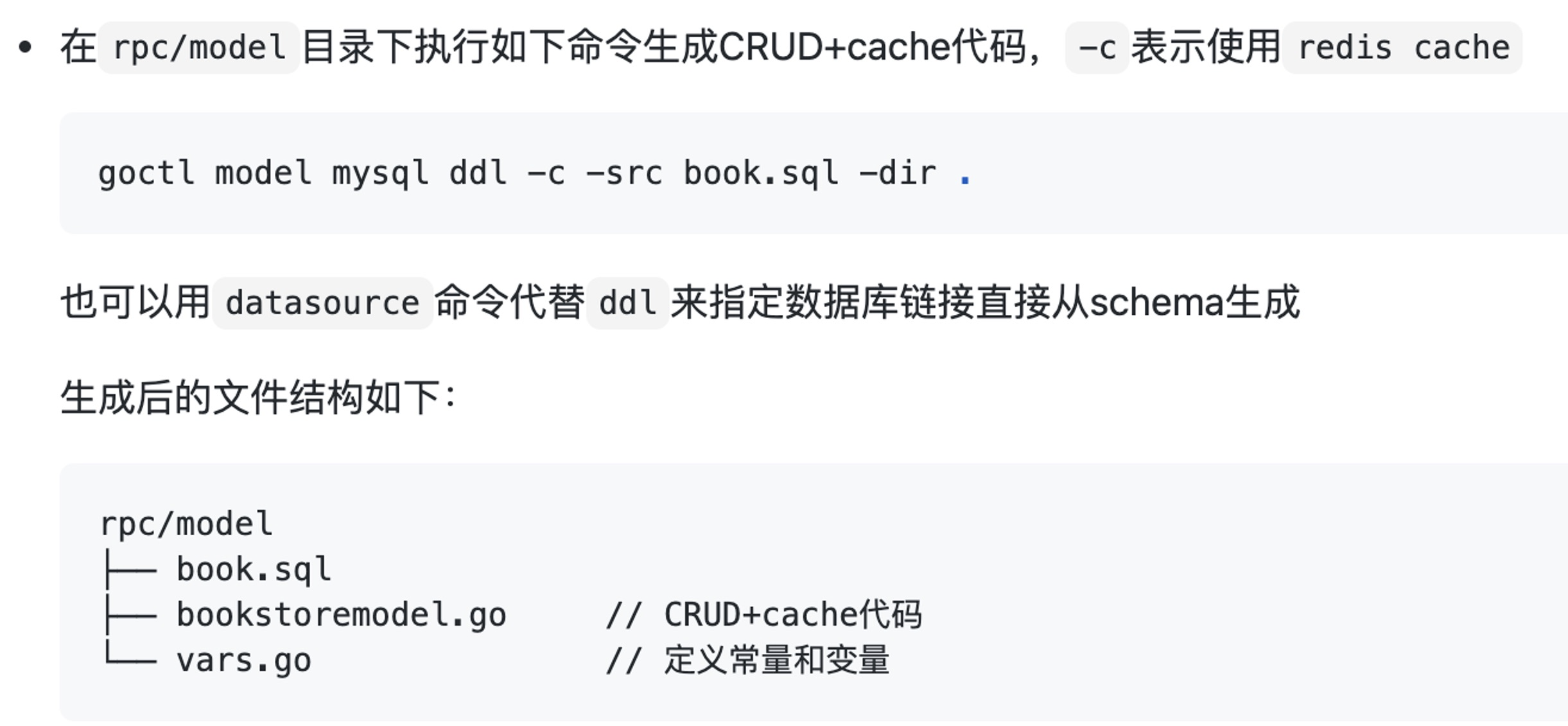
这是从 go-zero 的官方示例 bookstore 里截的一个 CRUD + Cache 的生成说明。我们可以通过指定的建表 sql 文件或者 datasource 来提供给 goctl 所需的 schema,然后 goctl 的 model 子命令可以一键生成所需的 CRUD + Cache 代码。
这样就确保了所有人写的缓存代码都是一样的,工具生成能不一样吗?😛
未完待续
本文跟大家一起讨论了缓存的可观测性和代码自动化,下一篇我来跟大家分享一下我们是怎么提炼和抽象缓存的通用解决方法的,大家可以预先了解一下聚族索引的设计,自己先思考一下缓存该如何做,毕竟经过深度思考,你的理解会更加深刻嘛!
所有这些问题的解决方法都已包含在 go-zero 微服务框架里,如果你想要更好的了解 go-zero 项目,欢迎前往官方网站上学习具体的示例。
视频回放地址
项目地址
https://github.com/tal-tech/go-zero
欢迎使用 go-zero 并 star 支持我们!
微信交流群
关注『微服务实践』公众号并点击 交流群 获取社区群二维码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号