

python编码问题
最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码;
由于不同国家有不同语言,各自发展出一套编码,不避免的发生编码冲突,于是Unicode应运而生。Unicode把所有语言都统一到一套编码里;
UTF-8是在Unicode基础上发展而来的可变长的编码方式。
|
ASCII |
Unicode |
UTF-8 |
|
1个字节 |
2个字节 |
可变长 |
编码表示示例
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
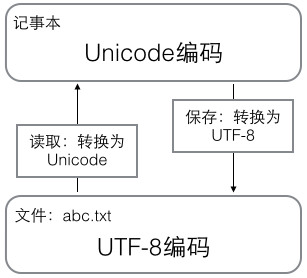
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件
Python中的编码
win+ python2 的环境下,Python 自带的IDE中输入的中文默认编码方式为GBK,所以先按照utf-8方式解码,然后编码成当前环境默认编码方式然后输出。
Python 3版本中,字符串是以Unicode编码
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号