
入门--环境安装
-
解释器:py2 / py3 (环境变量)
-
环境变量的设置,目的是便于快速使用解释器,减少每次使用解释器需频繁调用解释器的文件路径的麻烦
-
-
开发工具:pycharm
2.2 编码
2.2.1 python编码基础
-
ASCII 英文,8个数字表示1个单位,一共有28个,可以表示所有的英文、数字及符号,8个数字为1个字节
-
unicode 万国语,32个数字表示1个单位,共计有2**32个,目前还有很多空缺,32个数字为4个字节
-
utf-8, unicode的缩减版,unicode相比于ASCII优点是每个国家的文字都可以直接转译成编码,缺点是由于32个数字(即4个字节)表示1个单位,比较占用空间,在这个基础上,utf-8可以将unicode中未使用的0进行省略,但是只会每8位省略,中文3个字节
-
GBK 中国人自己使用的编码, 2个字节可以表示一个汉字
-
GB2312
2.2.2 python编码相关
对于Python默认解释器编码:
-
py2: ascii
-
py3: utf-8
如果想要修改默认编码,则可以使用:
# -*- coding:utf-8 -*- # 使用这组编码可以让python2使用utf-8进行编码
print("你好 世界")
注意:对于操作文件时,要按照:以什么编写写入,就要用什么编码去打开。
2.3 变量
问:为什么要有变量?
为某个值创建一个“外号”,以后在使用时候通过此外号就可以直接调用。
2.3.1变量命名要求
-
变量可随时变化,即最后一次赋值为变量的有效值,=为赋值 ==为比较
-
变量由数字、字母、下划线组成
-
变量的首位不可以是数字
-
变量不可以是python编程中的特有语言,如print、input等
-
见名知意,尽可能使用能理解的变量含义,如 name = ("小明") age = 20
-
一个英文单词如果无法完全表达意思,可以使用下划线进行连接较为规范,如old_boy
2.4 py2和3的区别
-
输入和输出的不同,2的输入是raw_input 输出是print ''
-
默认解释器的编码不同,2是ASCII
-
数据类型 2有int和long
-
2中的除法只能计算整数
-
range和xrange的区别,range是直接输出结果,xrange是先储存起来,需要的时候再逐次输出
-
模块和包有区别,2的包必须有一个内置文件init的文件
-
字典的keys/values/items,2可以直接提取并索引,3只有循环或者list可以获取,无法直接索引
#py2:
a = {1:2,2:3}
print(a.keys()) #列表格式
#py3:
[for i in a.keys()]
list(a.keys()) -
对map/filter 也是一样,3需要循环或者加list强制转换才可以取值
-
py3 str(字符串) byte(字节) (***重要) 上下对应
py2 unicode类型(u'中国') str(字节)
-
新式类和经典类的区别
-
新式类
-
继承object
-
支持super
-
多继承 广度优先 C3算法
-
mr方法
-
-
经典类
-
不继承object
-
没有super算法
-
深度优先
-
没有mro方法
-
-
class Foo:
pass
class Foo(object):
pass #py3中两种方式式一样的,都是新式类
class Foo:
pass
class Foo(object):
pass # 2中 上面的为经典类,下面的是新式类
2.5 python的驻留机制
-
Python自动将-5~256的整数进行了缓存,当你将这些整数赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象。
-
python会将一定规则的字符串在字符串驻留池中,创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象, 而是使用在字符串驻留池中创建好的对象。
-
适用对象 int (float),str,bool
#int
#默认 -5 ~ 256 都符合驻留机制
a1 = 100
a2 = 100
print(a1 is a2) #True
#str
# 1.根据长度 长度为0或者1 都符合驻留机制
a1 = '@' a2= '@' print(a1 is a2) True
# 2.大于1的话字符串必须只由大小写字母,数字,下划线构成,符合驻留机制
# 3. 如果涉及到乘法,分为两种情况
# 第一是乘数为1的情况下,全部驻留
a1 = '###asqazwsxedcedc_qazfewf'
a2 = a1 * 1
print(a1 is a2) True
# 第二是乘数大于等于2的情况下,由由大小写字母,数字,下划线构成,且总长度小于等于20,才会驻留
a1 = 'tai_b'*4 a2 = 'tai_b'*4 True
a1 = 'tai_ba'*4 a2 = 'tai_ba'*4 False
2.6 python的垃圾回收、标记清楚和分代回收
python中将所有数据类型分成两种,分别是由多个元素组成和由单个元素组成。利用不同的结构体区分,分别是
1.PyVarObject的组成
PyObject ob_base(pyobject结构体,内部包含了双向链表,引用计数器和对象类型)
Py_ssize_t ob_size(此对象有多少个元素组成)
2.PyObject的组成
_PyObject_HEAD_EXTRA(双向链表)
Py_ssize_t ob_refcnt(引用计数器)
_typeobject *ob_type(对象的类型)
在python代码中,创建对象或者是对对象进行赋值,内存中会对对象做如下操作:
1.对象加入双向链表中
2.引用计数器加1
如果执行了对象的移除:
1.引用计数器减一
2.从双向链表中剔除(当引用计数为0的时候)
垃圾回收机制是以引用计数为主,分代回收和标记清除为辅
引用计数:元素中有个 refcnt 多一次引用 引用计数加一 少一次引用 引用计数减一
标记清除:在引用计数器可以满足基本的内存管理和垃圾回收,但是他无法解决循环引用的问题
v1 = [1,2]
v2 = [3,4]
v1.append(v2)
v2.append(v1)
del v1
del v2
多个元素组成的类型才会出现循环引用。
在python中,会为多个元素组成和单个元素组成的类型分别维护一个双向链表,python的gc会定期扫描 由多个元素组成的那个链表。如果发现了循环引用,各自的引用计数器减一。
分代回收:python中为那些由多个元素组成的类型(可能存在循环引用)维护了三个双向链表,分别称为0代,1代,2代。对此三个链表,python中为其设置了阈值,分别是700,10,10,即第0代中如果有700个对象,就进行一次扫描,第一个10代表0代扫描10次,1代扫描1次,第二个10代表1代扫描10次,2代扫描1次。
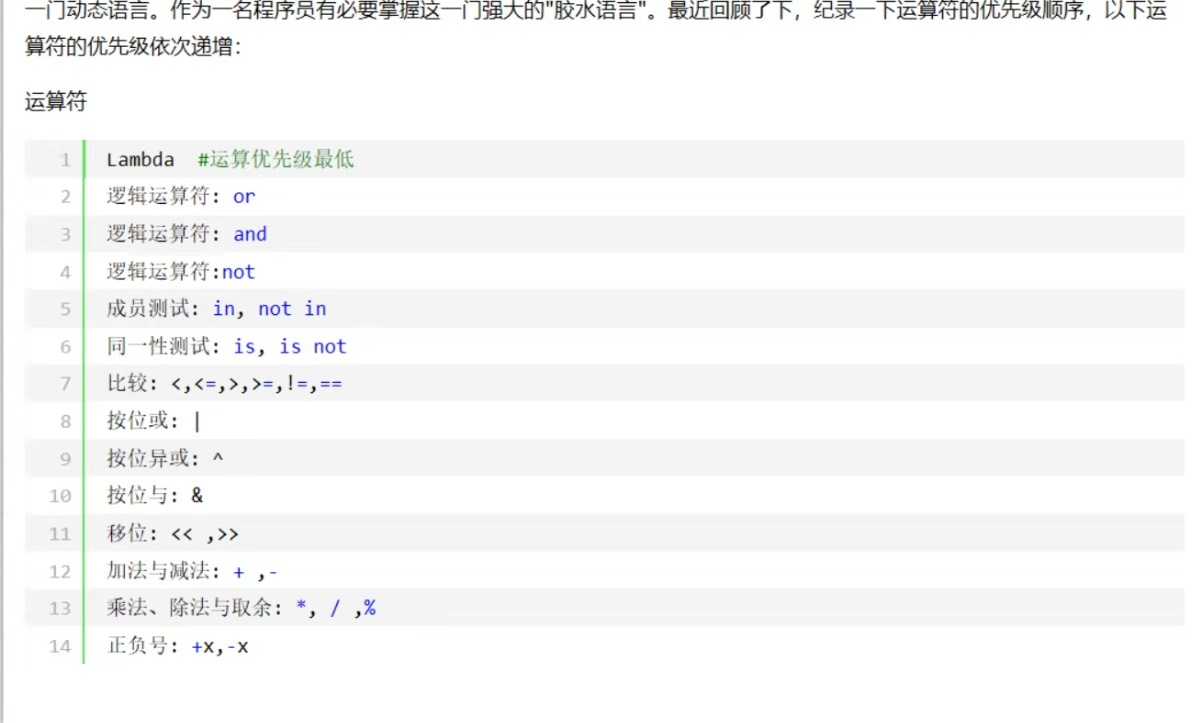
2.7 逻辑运算符
2.8 requirements 批量解决依赖
-
requirements的作用是用来在另一台PC上重新构建项目所需要的运行环境依赖。
#生成requirements.txt文件
pip freeze > requirements.txt
#安装requirements.txt依赖
pip install -r requirements.txt
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号