

Python自动化脚本——自动生成数据库字段备注脚本语句
前言:
由于平时工作疏忽,在创建建表语句的时候,没有及时给数据库字段增加备注,导致除了开发人员自己外,无法从数据库直接了解每一个字段的意义,维护人员需要一个数据字典从而方便他们的日常维护,但是然开发人员进行每一个字段的维护,工作量真的不可预估。(系统表有400+张,因此字段不可言喻....)于是,想到了用正则表达式,提取文件中的特定信息,生成数据库增加备注的语句。我们的建表语句结构如下:
declare
num number;
begin
select count(1) into num from USER_ALL_TABLES where TABLE_NAME = upper('base_fault_category');
if num=1 then
execute immediate 'drop table base_fault_category';
end if;
end;
/
create table base_fault_category (
Id int not null, --- ID
FactoryId int not null, --- FactoryID
Type varchar2(128) null, --- 故障类型
Category varchar2(255) null, --- 故障类别
Description varchar2(1024) null, --- 故障类别描述
DelFlag int default 0, ---软删除标记
Maintainer varchar2(64), ---维护人
MaintainTime varchar2(32) ---维护时间
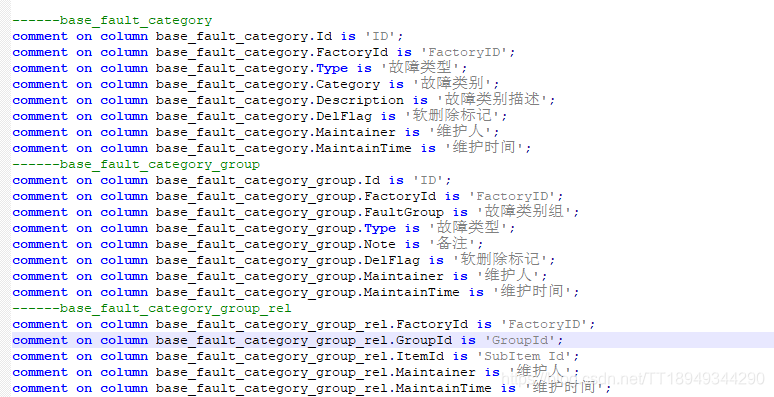
);需要将每个字段后面 --- 后面的内容与前面的字段匹配起来,生成如下的数据格式:
comment on table base_fault_category is '故障类别描述';
comment on column base_fault_category.Id is 'ID';
comment on column base_fault_category.FactoryId is 'FactoryID';
comment on column base_fault_category.Type is '故障类型';
comment on column base_fault_category.Category is '故障类别';
comment on column base_fault_category.Description is '故障类别描述';
comment on column base_fault_category.DelFlag is '软删除标记';
comment on column base_fault_category.Maintainer is '维护人';
comment on column base_fault_category.MaintainTime is '维护时间';于是,利用正则表达式,加上Python的脚本简单特性,就写了一个脚本,读取特定路径下所有的sql文件,进行逐行解析,生成脚本。具体脚本如下:
import os ,sys
import re
# 脚本文件所在的文件夹
file_dir = 'D:\\SVN\\database\\sql'
# 解析后的执行语句保存到的文件
out_file_dir = 'D:\\SVN\\database\\test.sql'
# res = '\s{1,}(\w{1,20})(\s{1,1000})(.*-{1,6})(.*)' # 匹配行正则
# tableRes = 'create\s{1,}table\s{1,}(\w{1,})' # 匹配表名正则
dirs = os.listdir(file_dir)
i = 0
table = ''
for file in dirs:
with open(file_dir+'\\'+file, 'r') as pop:
lines = pop.readlines()
for line in lines:
# 匹配表名
matchTable = re.match(r'create\s{1,}table\s{1,}(\w{1,})',line,re.M | re.I)
with open(out_file_dir, 'a') as op:
if matchTable:
i = i + 1
table = matchTable.group(1)
op.writelines('------'+table+'\n')
# 匹配复合的行,即字段行
matchObj = re.match(r'\s{1,}(\w{1,20})(\s{1,1000})(.*-{1,6})(.*)', line, re.M | re.I)
if matchObj:
# print '1:'+matchObj.group(1)
# print '2:'+matchObj.group(2)
# print '3:'+matchObj.group(4)
# 输出行: comment on column 表名.字段名 is '字段意义';
op.writelines('comment on column ' + table+'.' + matchObj.group(1) + ' is \''+matchObj.group(4).strip())
op.write('\';\n')
print line
op.close()
print (i)
pop.close()
print i # 打印应该读取了多少张有用的表通过执行以后,将D盘Svn/database 文件夹下的sql脚本进行遍历,逐行读取,匹配到则将特定的输出格式输出到test.sql文件中。脚本执行后的结果:
难点:正则表达式的匹配规则

 浙公网安备 33010602011771号
浙公网安备 33010602011771号