Python机器学习——识别不同鸟类
(一)选题背景:
鸟类是野生动物的重要组成部分,是自然界的一项重要资源动物,也是生态系统中的重要组成部分。鸟类是可更新的自然资源,它在商业、旅游、美学、文化、科学和生态上都有重要价值。国内近年来鸟类系统发育与分类、分布的研究不断取得新的成果,这些对于研究我国的鸟类分类区系和系统发育、地理分布以及 生物多样性保护,都能提供很有价值的信息。机器人如何来识别不同的鸟类,由此设计了一套程序来识别不同的鸟类物种
(二)机器学习设计案例:
从网站中下载相关的数据集,对数据集进行整理,在python的环境中,给数据集中的文件打上标签,"train"和 "test"文件用于训练和测试,对数据进行预处理,利用keras和tensorflow,通过构建输入层,隐藏层,输出层建立训练模型,导入图片测试模型。
数据集来源:kaggle,网址:https://www.kaggle.com/
(三)机器学习的实现步骤
1.数据集下载

2.导入需要用到的库
1 import numpy as np 2 import pandas as pd 3 import os 4 #所需的数据处理、模型构建、图像展示等相关函数和库 5 import tensorflow as tf 6 from tensorflow.keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array 7 from tensorflow.keras.models import Sequential, Model 8 from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, GlobalAveragePooling2D, Dropout, Flatten 9 from tensorflow.keras.applications import VGG16#VGG16模型用于直接提取图像特征 10 #matplotlib和seaborn库进行可视化展示和数据分析 11 import matplotlib.pyplot as plt 12 import seaborn as sns
1 #设置训练集所在的路径 2 train_ds="./lty/bird-species/train" 3 #设置测试集所在的路径 4 test_ds="./lty/bird-species/test" 5 #设置验证集所在路径 6 validation_ds="./lty/bird-species/valid"
1 #用path变量存储训练集所在文件夹的路径 2 path="C:/Users/z/lty/bird-species/train" 3 dirs = os.listdir( path )#返回train训练集文件夹,以列表形式返回 4 for file in dirs: 5 print (file)

4.得到每个文件中图片的数量并进行图像预处理
1 #图像分类参数的设置 2 IMAGE_DIM = (224,224)#设置图片尺寸 3 BATCH_SIZE = 32 #设置batch数据为32 4 CLASSES = 525 5 6 #导入图像数据生成器 ImageDataGenerator 7 from keras.preprocessing.image import ImageDataGenerator 8 #数据增强生成器 9 #用ImageDataGenerator函数定义了一个数据增强器 10 train_datagen = ImageDataGenerator(rescale=1./255, # 将像素值缩放到0-1之间 11 width_shift_range=0.2, 12 height_shift_range=0.2, 13 zoom_range=0.2 14 ) 15 16 test_datagen = ImageDataGenerator(rescale=1./255) 17 18 val_datagen = ImageDataGenerator(rescale=1./255) 19 20 #调用 datagen 对象的 flow_from_directory() 方法创建了训练集的迭代器 train_generator 21 #directory:设置训练数据集的路径 22 #target_size:指定了图像的尺寸为224*224 23 #batch_size:指定了每个batch的大小, 24 #class_mode:指定了分类问题的类别数 25 #shuffle:则表明生成的图像数据是否需要随机打乱 26 train_generator = train_datagen.flow_from_directory(directory="./lty/bird-species/train", 27 target_size=IMAGE_DIM, 28 batch_size=BATCH_SIZE, 29 class_mode='categorical', 30 shuffle=True ) 31 32 test_generator = test_datagen.flow_from_directory(directory="./lty/bird-species/test", 33 target_size=IMAGE_DIM, 34 batch_size=BATCH_SIZE, 35 class_mode='categorical', 36 shuffle=False ) 37 38 validation_generator = val_datagen.flow_from_directory(directory="./lty/bird-species/valid", 39 target_size=IMAGE_DIM, 40 batch_size=BATCH_SIZE, 41 class_mode='categorical', 42 shuffle=False )

1 train_generator[0][0].shape

1 #train_generator生成器的方式,获取batch的数据 2 #返回图像数据和标签数据 3 img= train_generator[0] 4 print(img)

1 img = train_generator[0] 2 print(img[0].shape) 3 print(img[1].shape)

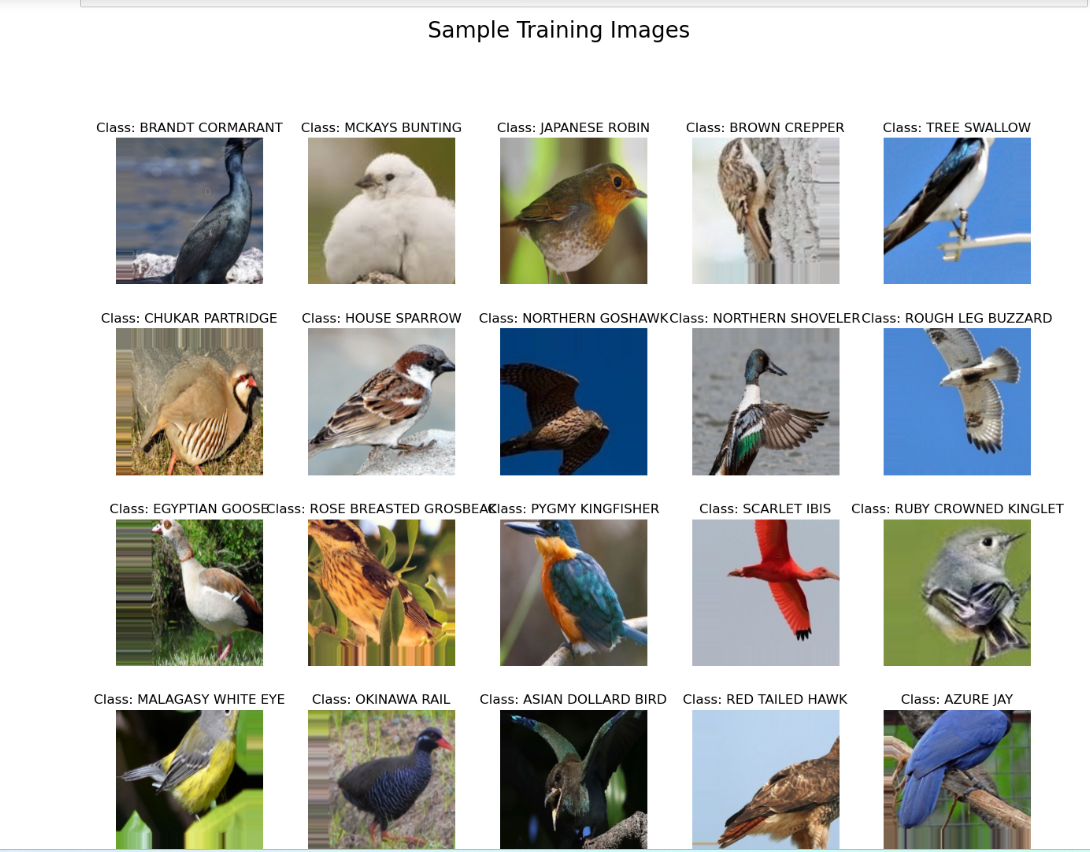
5.可视化训练数据的一批数据,并查看经过处理的图片以及它的标签
1 #通过列表推导式labels = [k for k in train_generator.class_indices]获取训练集生成器的类别标签 2 #将图像数据,存储在sample_generate[0]中;将标签数据,存储在sample_generate[1] 3 #使用Matplotlib库创建一个15*15英寸的图表对象,并循环处理该batch中每个图像 4 #调用plt.subplot()方法创建一个子图,分别设置该子图的行、列和索引编号 5 #使用np.argmax()函数得到类别标签,再使用 labels 列表获取对应标签名称 6 #plt.imshow()、plt.title()方法分别显示图像与该图像对应的类别标签 7 labels = [k for k in train_generator.class_indices] 8 sample_generate = train_generator.__next__() 9 10 images = sample_generate[0] 11 titles = sample_generate[1] 12 plt.figure(figsize = (15 , 15)) 13 14 for i in range(20): 15 plt.subplot(5 , 5 , i+1) 16 plt.subplots_adjust(hspace = 0.3 , wspace = 0.3)#调整子图之间的空白区域 17 plt.imshow(images[i]) 18 plt.title(f'Class: {labels[np.argmax(titles[i],axis=0)]}') 19 plt.axis("off")
1 #输出训练集、测试集和验证集中的样本数 2 print(len(train_generator)) 3 print(len(test_ds)) 4 print(len(validation_ds))

6.显示文件夹中指定一张图像
1 #使用Matplotlib和Scikit-image库来显示一张图像 2 import matplotlib.pyplot as plt 3 from skimage import io 4 5 img_url = "./lty/bird-species/train/AFRICAN PIED HORNBILL/007.jpg"#指定要读取和显示的图像文件路径 6 img = io.imread(img_url)#imread#使用imread函数以数组形式读取指定路径下的图像文件 7 8 plt.imshow(img)#使用imshow函数显示读取到的图像数组 9 plt.axis('off') 10 plt.show()

7.构建神经网络并对模型进行训练
1 import numpy as np 2 #Dense:用于全连接层, 3 #Flatten:将卷积层的输出展平成一维向量, 4 #Conv2D:卷积操作, 5 #Activation:激活函数, 6 #Dropout:在模型训练过程中随机丢弃一定比例的神经元,以防止过拟合 7 from keras.layers import Dense,Flatten,Conv2D,Activation,Dropout 8 9 from keras import backend as K 10 11 import keras 12 13 from keras.models import Sequential, Model 14 15 from keras.models import load_model 16 #导入SGD优化器、EarlyStopping早停法、ModelCheckpoint模型保存等,提高CNN模型性能和训练效果 17 from keras.optimizers import SGD 18 from keras.callbacks import EarlyStopping,ModelCheckpoint 19 #使用MaxPool2D层导入了最大池化层,在卷积操作之后对特征图进行下采样和压缩 20 from keras.layers import MaxPool2D
1 #创建一个空的顺序模型 2 model = Sequential() 3 #向该模型增加64个大小为3*3过滤器的形状为224x224x3的图像的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变 4 model.add(Conv2D(input_shape=(224,224,3),filters=64,kernel_size=(3,3),padding="same", activation="relu")) 5 #向该模型增加64个大小为*3的过滤器的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变。"再次添加了一个同样大小的卷积层进行特征提取" 6 model.add(Conv2D(filters=64,kernel_size=(3,3),padding="same", activation="relu")) 7 #使用2x2大小的窗口进行2倍下采样,减小特征图的空间大小 8 model.add(MaxPool2D(pool_size=(2,2),strides=(2,2))) 9 #向该模型增加128个大小为3*3的过滤器的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变 10 model.add(Conv2D(filters=128, kernel_size=(3,3), padding="same", activation="relu")) 11 model.add(Conv2D(filters=128, kernel_size=(3,3), padding="same", activation="relu")) 12 model.add(MaxPool2D(pool_size=(2,2),strides=(2,2))) 13 #向该模型增加256个大小为3*3的过滤器的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变 14 model.add(Conv2D(filters=256, kernel_size=(3,3), padding="same", activation="relu")) 15 model.add(Conv2D(filters=256, kernel_size=(3,3), padding="same", activation="relu")) 16 model.add(Conv2D(filters=256, kernel_size=(3,3), padding="same", activation="relu")) 17 model.add(MaxPool2D(pool_size=(2,2),strides=(2,2))) 18 #向该模型增加512个大小为3*3的过滤器的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变 19 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 20 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 21 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 22 model.add(MaxPool2D(pool_size=(2,2),strides=(2,2))) 23 #向该模型增加512个大小为3*3的过滤器的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变 24 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 25 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 26 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 27 model.add(MaxPool2D(pool_size=(2,2),strides=(2,2))) 28 29 #使用 Flatten() 函数将之前的卷积层的输出压平成一维向量 30 model.add(Flatten()) 31 #添加一个具有4096个神经元和ReLU激活函数的全连接层 32 model.add(Dense(units=4096,activation="relu")) 33 #再次添加一个具有4096个神经元和ReLU激活函数的全连接层 34 model.add(Dense(units=4096,activation="relu")) 35 #添加一个具有525个神经元(代表ImageNet的分类数) 和softmax激活函数的输出层,用于对输入图像进行分类 36 model.add(Dense(units=525, activation="softmax"))
8模型编译
1 model.compile(optimizer=opt, 2 loss=keras.losses.categorical_crossentropy, 3 metrics=['accuracy']) 4 #optimizer=opt:使用模型参数优化的优化器‘opt’ 5 #设置损失函数为 categorical_crossentropy,评估指标为准确率accuracy
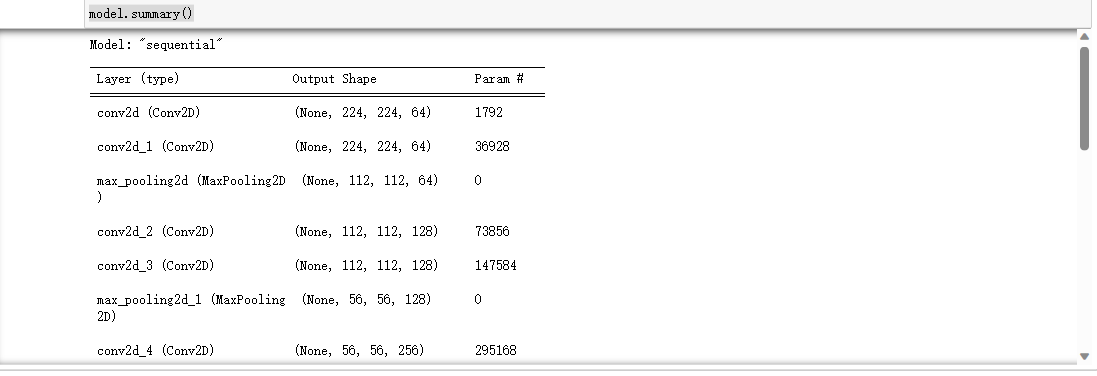
9.总结模型
1 #输出模型各层的参数状况 2 3 model.summary()
10.训练模型
1 history =model.fit(train_generator, 2 validation_data=test_generator, 3 epochs=15) 4 #train_generator和test_generator分别表示训练集和测试集的数据生成器对象 5 #epochs指定训练数据的迭代次数为15次,并包含了每次迭代的损失值和精度值

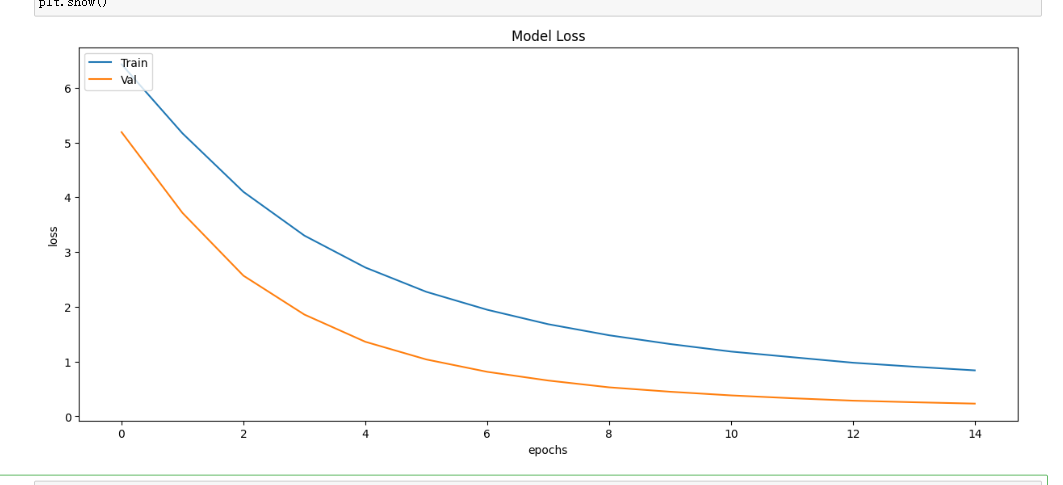
11.绘制损失曲线和精度曲线图
1 #绘制损失曲线 2 plt.figure(figsize=(12,5)) 3 plt.plot(history.history['loss'])#使用plot函数绘制训练集上的损失曲线 4 plt.plot(history.history['val_loss'])#使用plot函数绘制验证集上的损失曲线 5 plt.title('Model Loss') 6 plt.ylabel('loss') 7 plt.xlabel('Epochs') 8 plt.legend(['Train','Val'], loc= 'upper left') 9 plt.show()
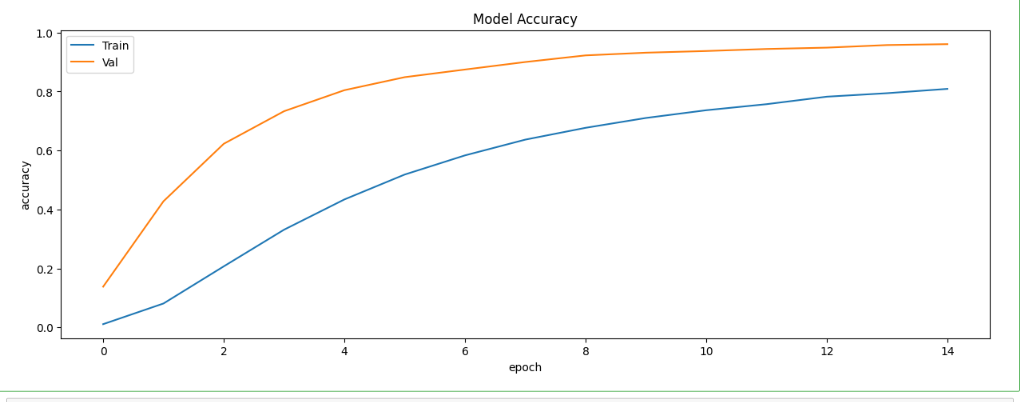
1 #绘制精度曲线图 2 plt.figure(figsize=(12,5)) 3 plt.plot(history.history['accuracy'])#使用plot函数绘制训练集上的精度曲线 4 plt.plot(history.history['val_accuracy'])#使用plot函数绘制验证集上的精度曲线 5 plt.title('Model Accuracy') 6 plt.ylabel('Accuracy') 7 plt.xlabel('Epochs') 8 plt.legend(['Train','Val'], loc = 'upper left') 9 plt.show()
12.测试模型
1 #对测试集的预测和真实标签的提取,并将预测结果从概率形式转换为类别标签形式 2 y_test_1 = test_generator.classes#获取测试集上的真实标签 3 y_pred_1 =model.predict(test_generator) 4 y_pred_1 = np.argmax(y_pred_1,axis=1) 5 #axis=1:在每行中寻找最大值所在的列索引

1 #evaluate函数对测试集进行评估,并将评估结果保存在results变量中 2 results =model.evaluate(test_generator)

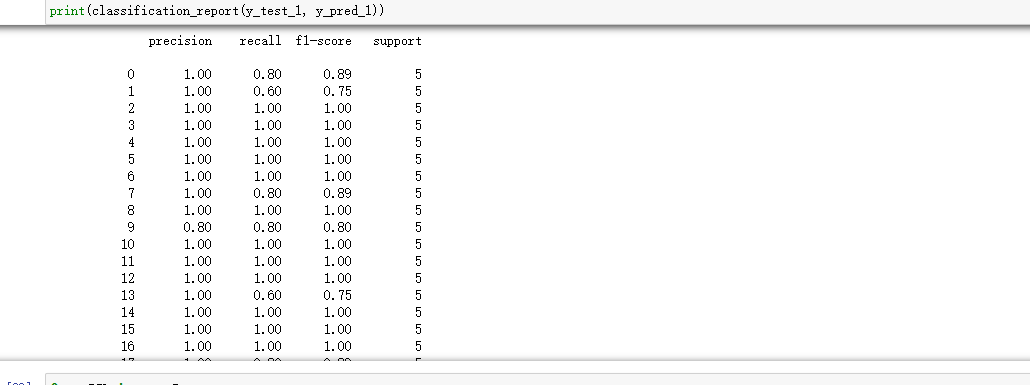
1 #鸟类分类报告 2 from sklearn.metrics import classification_report 3 4 print(classification_report(y_test_1, y_pred_1)) 5 #调用classification_report函数,将真实标签y_test_1和预测标签y_pred_1作为参数传入,生成分类报告并输出
13.鸟类分类预测类别
#循环遍历预测结果,
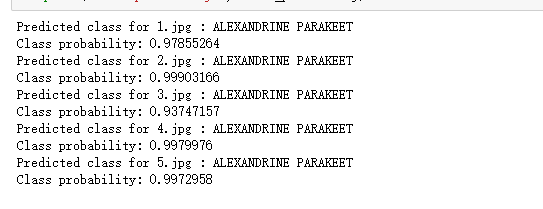
1 #使用for循环遍历所有图片 2 for i in range(len(images)): 3 predicted_class = np.argmax(predictions[i]) 4 #使用argmax函数获取每张图片预测结果中概率最大的类别对应的索引 5 class_probability = predictions[i, predicted_class] 6 #获取预测标签对应的概率值 7 print(f'Predicted class for {i+1}.jpg : {labels[predicted_class]}') 8 print('Class probability:', class_probability) 9 #f分别输出当前图片的预测标签和当前图片的预测标签对应的概率值
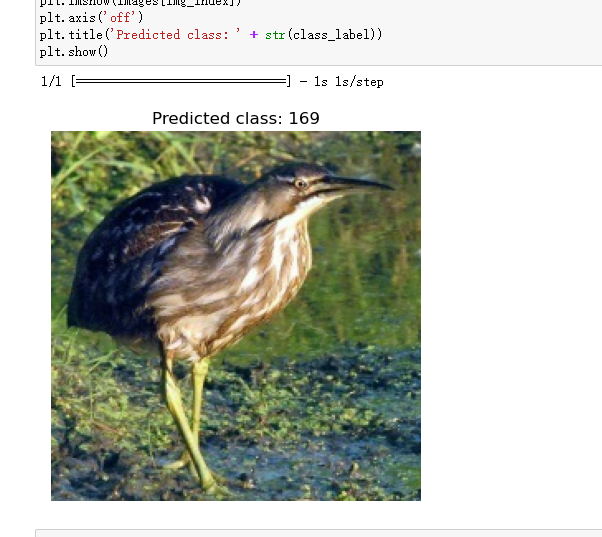
1 #指定文件夹中的图片进行预测 2 from PIL import Image 3 import os 4 import numpy as np 5 import matplotlib.pyplot as plt 6 7 image_directory = './lty/bird-species/valid/AMERICAN BITTERN' 8 img_size = 224#设置输入模型的图像大小 9 10 images = [] 11 for filename in os.listdir(image_directory): 12 path = os.path.join(image_directory, filename) 13 img = Image.open(path)#打开图片文件,并返回一个Image对象 14 img = img.resize((img_size, img_size)) 15 images.append(img)#将处理后的图片对象添加到列表中 16 17 18 images = np.array([np.array(img) for img in images]) 19 images = images / 255.0 #对图像数据进行归一化 20 21 predictions = model.predict(images) 22 #使用已经训练好的模型对输入的图像进行预测,并返回预测结果 23 24 img_index = 0 25 26 27 class_label = np.argmax(predictions[img_index]) 28 #获取指定图片的预测标签 29 30 plt.imshow(images[img_index]) 31 plt.axis('off') 32 plt.title('Predicted class: ' + str(class_label))#设置标题,用于显示预测结果中的类别标签 33 plt.show()
(四)收获:
本次的程序设计主要内容是机器学习,通过本次课程设计,让我对机器学习的理解更加深刻,同时,使我掌握了如何进行机器学习,导入数据并查看数据,构建数据集。学会了如何利用卷积层神经网络进行鸟类识别,使用Keras框架和Tensorflow库构建模型 (Adam优化器加快模型训练,)利用EarlyStopping和ModelCheckpoint回调函数来提高模型的性能,以及使用图像分类的机器学习程序。
(五)全代码
1 import numpy as np 2 import pandas as pd 3 import os 4 #所需的数据处理、模型构建、图像展示等相关函数和库 5 import tensorflow as tf 6 from tensorflow.keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array 7 from tensorflow.keras.models import Sequential, Model 8 from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, GlobalAveragePooling2D, Dropout, Flatten 9 from tensorflow.keras.applications import VGG16#VGG16模型用于直接提取图像特征 10 #matplotlib和seaborn库进行可视化展示和数据分析 11 import matplotlib.pyplot as plt 12 import seaborn as sns 13 14 #设置训练集所在的路径 15 train_ds="./lty/bird-species/train" 16 #设置测试集所在的路径 17 test_ds="./lty/bird-species/test" 18 #设置验证集所在路径 19 validation_ds="./lty/bird-species/valid" 20 21 #用path变量存储训练集所在文件夹的路径 22 path="C:/Users/z/lty/bird-species/train" 23 dirs = os.listdir( path )#返回train训练集文件夹,以列表形式返回 24 for file in dirs: 25 print (file) 26 27 #图像分类参数的设置 28 IMAGE_DIM = (224,224)#设置图片尺寸 29 BATCH_SIZE = 32 #设置batch数据为32 30 CLASSES = 525 31 32 #导入图像数据生成器 ImageDataGenerator 33 from keras.preprocessing.image import ImageDataGenerator 34 #数据增强生成器 35 #用ImageDataGenerator函数定义了一个数据增强器 36 train_datagen = ImageDataGenerator(rescale=1./255, # 将像素值缩放到0-1之间 37 width_shift_range=0.2, 38 height_shift_range=0.2, 39 zoom_range=0.2 40 ) 41 42 test_datagen = ImageDataGenerator(rescale=1./255) 43 44 val_datagen = ImageDataGenerator(rescale=1./255) 45 46 #调用 datagen 对象的 flow_from_directory() 方法创建了训练集的迭代器 train_generator 47 #directory:设置训练数据集的路径 48 #target_size:指定了图像的尺寸为224*224 49 #batch_size:指定了每个batch的大小, 50 #class_mode:指定了分类问题的类别数 51 #shuffle:则表明生成的图像数据是否需要随机打乱 52 train_generator = train_datagen.flow_from_directory(directory="./lty/bird-species/train", 53 target_size=IMAGE_DIM, 54 batch_size=BATCH_SIZE, 55 class_mode='categorical', 56 shuffle=True ) 57 58 test_generator = test_datagen.flow_from_directory(directory="./lty/bird-species/test", 59 target_size=IMAGE_DIM, 60 batch_size=BATCH_SIZE, 61 class_mode='categorical', 62 shuffle=False ) 63 64 validation_generator = val_datagen.flow_from_directory(directory="./lty/bird-species/valid", 65 target_size=IMAGE_DIM, 66 batch_size=BATCH_SIZE, 67 class_mode='categorical', 68 shuffle=False ) 69 70 #train_generator生成器的方式,获取batch的数据 71 #返回图像数据和标签数据 72 img= train_generator[0] 73 print(img) 74 75 #通过列表推导式labels = [k for k in train_generator.class_indices]获取训练集生成器的类别标签 76 #将图像数据,存储在sample_generate[0]中;将标签数据,存储在sample_generate[1] 77 #使用Matplotlib库创建一个15*15英寸的图表对象,并循环处理该batch中每个图像 78 #调用plt.subplot()方法创建一个子图,分别设置该子图的行、列和索引编号 79 #使用np.argmax()函数得到类别标签,再使用 labels 列表获取对应标签名称 80 #plt.imshow()、plt.title()方法分别显示图像与该图像对应的类别标签 81 labels = [k for k in train_generator.class_indices] 82 sample_generate = train_generator.__next__() 83 84 images = sample_generate[0] 85 titles = sample_generate[1] 86 plt.figure(figsize = (15 , 15)) 87 88 for i in range(20): 89 plt.subplot(5 , 5 , i+1) 90 plt.subplots_adjust(hspace = 0.3 , wspace = 0.3)#调整子图之间的空白区域 91 plt.imshow(images[i]) 92 plt.title(f'Class: {labels[np.argmax(titles[i],axis=0)]}') 93 plt.axis("off") 94 95 96 #输出训练集、测试集和验证集中的样本数 97 print(len(train_generator)) 98 print(len(test_ds)) 99 print(len(validation_ds)) 100 101 #使用Matplotlib和Scikit-image库来显示一张图像 102 import matplotlib.pyplot as plt 103 from skimage import io 104 105 img_url = "./lty/bird-species/train/AFRICAN PIED HORNBILL/007.jpg"#指定要读取和显示的图像文件路径 106 img = io.imread(img_url)#imread函数以数组形式读取指定路径下的图像文件 107 108 plt.imshow(img) 109 plt.axis('off') 110 plt.show() 111 112 import numpy as np 113 #Dense:用于全连接层, 114 #Flatten:将卷积层的输出展平成一维向量, 115 #Conv2D:卷积操作, 116 #Activation:激活函数, 117 #Dropout:在模型训练过程中随机丢弃一定比例的神经元,以防止过拟合 118 from keras.layers import Dense,Flatten,Conv2D,Activation,Dropout 119 120 from keras import backend as K 121 122 import keras 123 124 from keras.models import Sequential, Model 125 126 from keras.models import load_model 127 #导入SGD优化器、EarlyStopping早停法、ModelCheckpoint模型保存等,提高CNN模型性能和训练效果 128 from keras.optimizers import SGD 129 from keras.callbacks import EarlyStopping,ModelCheckpoint 130 #使用MaxPool2D层导入了最大池化层,在卷积操作之后对特征图进行下采样和压缩 131 from keras.layers import MaxPool2D 132 133 #创建一个空的顺序模型 134 model = Sequential() 135 #向该模型增加64个大小为3*3过滤器的形状为224x224x3的图像的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变 136 model.add(Conv2D(input_shape=(224,224,3),filters=64,kernel_size=(3,3),padding="same", activation="relu")) 137 #向该模型增加64个大小为*3的过滤器的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变。"再次添加了一个同样大小的卷积层进行特征提取" 138 model.add(Conv2D(filters=64,kernel_size=(3,3),padding="same", activation="relu")) 139 #使用2x2大小的窗口进行2倍下采样,减小特征图的空间大小 140 model.add(MaxPool2D(pool_size=(2,2),strides=(2,2))) 141 #向该模型增加128个大小为3*3的过滤器的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变 142 model.add(Conv2D(filters=128, kernel_size=(3,3), padding="same", activation="relu")) 143 model.add(Conv2D(filters=128, kernel_size=(3,3), padding="same", activation="relu")) 144 model.add(MaxPool2D(pool_size=(2,2),strides=(2,2))) 145 #向该模型增加256个大小为3*3的过滤器的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变 146 model.add(Conv2D(filters=256, kernel_size=(3,3), padding="same", activation="relu")) 147 model.add(Conv2D(filters=256, kernel_size=(3,3), padding="same", activation="relu")) 148 model.add(Conv2D(filters=256, kernel_size=(3,3), padding="same", activation="relu")) 149 model.add(MaxPool2D(pool_size=(2,2),strides=(2,2))) 150 #向该模型增加512个大小为3*3的过滤器的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变 151 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 152 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 153 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 154 model.add(MaxPool2D(pool_size=(2,2),strides=(2,2))) 155 #向该模型增加512个大小为3*3的过滤器的卷积层,设置激活函数为ReLU,并使用same填充方式保持输出特征图大小不变 156 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 157 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 158 model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu")) 159 model.add(MaxPool2D(pool_size=(2,2),strides=(2,2))) 160 161 #使用 Flatten() 函数将之前的卷积层的输出压平成一维向量 162 model.add(Flatten()) 163 #添加一个具有4096个神经元和ReLU激活函数的全连接层 164 model.add(Dense(units=4096,activation="relu")) 165 #再次添加一个具有4096个神经元和ReLU激活函数的全连接层 166 model.add(Dense(units=4096,activation="relu")) 167 #添加一个具有525个神经元(代表ImageNet的分类数) 和softmax激活函数的输出层,用于对输入图像进行分类 168 model.add(Dense(units=525, activation="softmax")) 169 170 model.compile(optimizer=opt, 171 loss=keras.losses.categorical_crossentropy, 172 metrics=['accuracy']) 173 #optimizer=opt:使用模型参数优化的优化器‘opt’ 174 #设置损失函数为 categorical_crossentropy,评估指标为准确率accuracy 175 176 #输出模型各层的参数状况 177 178 model.summary() 179 180 history =model.fit(train_generator, 181 validation_data=test_generator, 182 epochs=15) 183 #train_generator和test_generator分别表示训练集和测试集的数据生成器对象 184 #epochs指定训练数据的迭代次数为15次,并包含了每次迭代的损失值和精度值 185 186 #绘制损失曲线 187 plt.figure(figsize=(12,5)) 188 plt.plot(history.history['loss'])#使用plot函数绘制训练集上的损失曲线 189 plt.plot(history.history['val_loss'])#使用plot函数绘制验证集上的损失曲线 190 plt.title('Model Loss') 191 plt.ylabel('loss') 192 plt.xlabel('Epochs') 193 plt.legend(['Train','Val'], loc= 'upper left') 194 plt.show() 195 196 #绘制精度曲线图 197 plt.figure(figsize=(12,5)) 198 plt.plot(history.history['accuracy'])#使用plot函数绘制训练集上的精度曲线 199 plt.plot(history.history['val_accuracy'])#使用plot函数绘制验证集上的精度曲线 200 plt.title('Model Accuracy') 201 plt.ylabel('Accuracy') 202 plt.xlabel('Epochs') 203 plt.legend(['Train','Val'], loc = 'upper left') 204 plt.show() 205 206 #对测试集的预测和真实标签的提取,并将预测结果从概率形式转换为类别标签形式 207 y_test_1 = test_generator.classes#获取测试集上的真实标签 208 y_pred_1 =model.predict(test_generator) 209 y_pred_1 = np.argmax(y_pred_1,axis=1) 210 #axis=1:在每行中寻找最大值所在的列索引 211 212 #evaluate函数对测试集进行评估,并将评估结果保存在results变量中 213 results =model.evaluate(test_generator) 214 215 #鸟类分类报告 216 from sklearn.metrics import classification_report 217 218 print(classification_report(y_test_1, y_pred_1)) 219 #调用classification_report函数,将真实标签y_test_1和预测标签y_pred_1作为参数传入,生成分类报告并输出 220 221 #使用for循环遍历所有图片 222 for i in range(len(images)): 223 predicted_class = np.argmax(predictions[i]) 224 #使用argmax函数获取每张图片预测结果中概率最大的类别对应的索引 225 class_probability = predictions[i, predicted_class] 226 #获取预测标签对应的概率值 227 print(f'Predicted class for {i+1}.jpg : {labels[predicted_class]}') 228 print('Class probability:', class_probability) 229 #f分别输出当前图片的预测标签和当前图片的预测标签对应的概率值 230 231 #指定文件夹中的图片进行预测 232 from PIL import Image 233 import os 234 import numpy as np 235 import matplotlib.pyplot as plt 236 237 image_directory = './lty/bird-species/valid/AMERICAN BITTERN' 238 img_size = 224#设置输入模型的图像大小 239 240 images = [] 241 for filename in os.listdir(image_directory): 242 path = os.path.join(image_directory, filename) 243 img = Image.open(path)#打开图片文件,并返回一个Image对象 244 img = img.resize((img_size, img_size)) 245 images.append(img) 246 #将处理后的图片对象添加到列表中 247 248 249 images = np.array([np.array(img) for img in images]) 250 images = images / 255.0 251 #对图像数据进行归一化 252 253 predictions = model.predict(images) 254 #使用已经训练好的模型对输入的图像进行预测,并返回预测结果 255 256 img_index = 0 257 258 259 class_label = np.argmax(predictions[img_index]) 260 #获取指定图片的预测标签 261 262 plt.imshow(images[img_index]) 263 plt.axis('off') 264 plt.title('Predicted class: ' + str(class_label)) 265 #设置标题,用于显示预测结果中的类别标签 266 plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号