SQL Server更新统计信息会导致Parameter Sniffing
2026-01-28 21:35 潇湘隐者 阅读(150) 评论(0) 收藏 举报本文是翻译Brent Ozar的这篇文章Updating Statistics Causes Parameter Sniffing, 译文地址https://www.cnblogs.com/kerrycode/p/19542136。
在我的免费课程如何像引擎一样思考中,我解释了SQL Server是如何基于统计信息来生成执行计划的。表中的数据内容会决定它使用哪些索引、采用索引查找还是全表扫描、分配多少CPU核心、授予多少内存,以及诸多其它执行策略。
当对象的统计信息发生变化时,SQL Server 会认为 “下次有查询引用这个对象时,我最好生成一个新执行计划,因为旧执行计划可能不再适合新的数据分布”。
这通常是好事,因为我们都希望有一个准确的执行计划。但这同时也让你面临/陷入风险。
每当你更新某张表或某个索引的统计信息时,其实也是在告诉 SQL Server,所有涉及该表的执行计划都需要根据接下来传入的参数生成一个全新的执行计划。正如我在Fundamentals of Parameter Sniffing课程中所讨论的,这意味着你更新统计信息次数越频繁,承担的风险就越大:你是在刻意释放执行计划缓存的一部分,通常是很大一部分,并且对接下来传入的参数抱有很大的不确定性。
更新统计信息可以生成更优的查询计划.
在理想情况下,你应该只有在查询计划能从新的统计信息中获益时,才应该更新统计信息.
为了让大家理解这一点,我们以Stack Overflow数据库中的 Users 表为例,并思考一下每一列的内容会以何种方式发生变化,才会对查询计划产生影响。
频繁更新统计数据至关重要的经典场景是使用日期列来记录当前活动.在数据仓库中,这意味着加载昨天的新销售数据。在Stack Overflow的Users表中,类似的是LastAccessDate 列:用户整天都在登录。假设我们在 LastAccessDate 上有一个索引,并且有一个存储过程通过该日期范围来查询用户信息:
CREATE INDEX LastAccessDate ON dbo.Users(LastAccessDate);
GO
CREATE OR ALTER PROC dbo.usp_SearchUsersByDate
@LastAccessDateStart DATETIME,
@LastAccessDateEnd DATETIME
AS
SELECT *
FROM dbo.Users
WHERE LastAccessDate >= @LastAccessDateStart
AND LastAccessDate <= @LastAccessDateEnd
ORDER BY DisplayName;
GO
当这个查询运行时,SQL Server 必须决定是否使用该索引,以及为DisplayName列的排序操作授予多少内存。如果我们在前一晚更新了统计信息后,今天有 1% 的用户在白天登录,
然后我们尝试运行这个搜索查询:
-- 假设今天有 1% 的用户登录
UPDATE dbo.Users
SET LastAccessDate = GETDATE()
WHERE Id % 100 = 1;
GO
EXEC usp_SearchUsersByDate '2020-05-26', '2020-05-27';
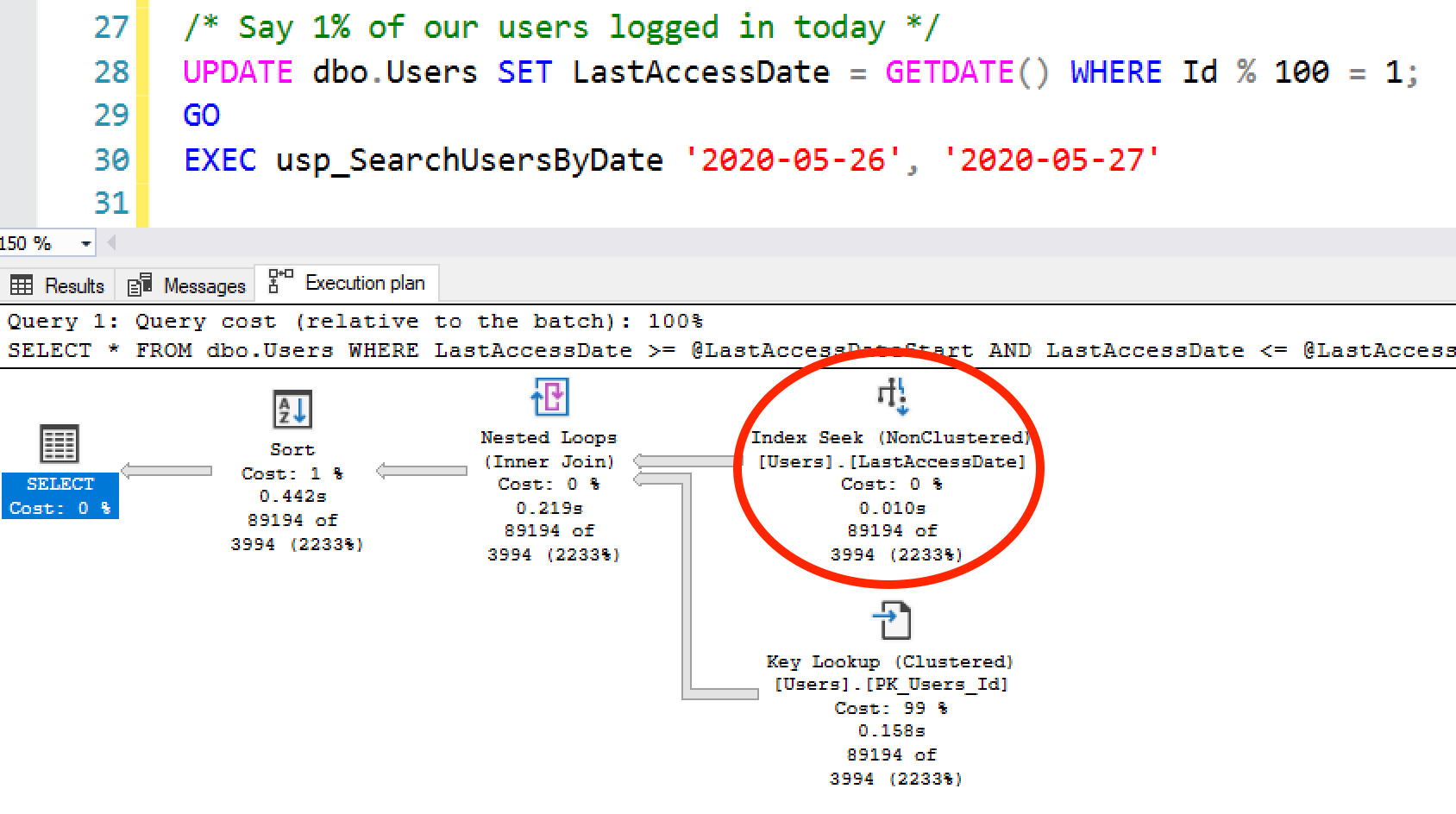
那么SQL Server很可能无法精准预估查询的返回行数,因为统计信息更新后,数据又发生了变化。这种预估偏差,可能会导致排序操作的中间结果溢出到磁盘,或者也可能让 SQL Server 错误选择索引查找,而实际全表扫描的效率会更高.
在上述计划中,SQL Server 做出了低效的选择了索引查找 + 键查找,结果的数据页数量比表本身的总数据页数实际还多。在这种情况下,你确实需要频繁更新统计信息——而在一个非常活跃的网站上,即便频繁更新统计信息,统计信息的更新速度也未必能跟上数据变化,无法让执行计划精准反映未来几小时内的表数据情况。这就是人们最终诉诸查询提示、强制执行计划,甚至为未来的待入库数据创建虚拟统计信息的原因。(我自己从没试过最后这种方法,但觉得这种思路很有意思。)
但对于其他列,频繁的统计信息更新会适得其反.如果我写一个查询,要求 “显示所有Location 为 San Diego, CA 的用户”,这个数据分布并不会频繁变化。当然,随着表中用户数量不断增加,查询的行数预估可能会出现几行甚至几百行的偏差,但在数周的时间里,单个取值对应的数据分布不会发生大幅变化。对于有多年历史的成熟数据库,Location(所在地)列的统计信息即便连续数月不更新,也完全无需担心。
表内的整体数据分布不会在短时间内发生太大变化。
但每个查询的数据分布却在不断变化。
假设我在 Location 上有一个索引,并且有一个存储过程如下:
DropIndexes;
GO
CREATE INDEX Location ON dbo.Users(Location);
GO
CREATE OR ALTER PROC dbo.usp_SearchUsers
@Location NVARCHAR(100)
AS
SELECT TOP 1000 *
FROM dbo.Users
WHERE Location = @Location
ORDER BY Reputation DESC;
GO
在统计信息更新后,第一次调用该存储过程时传入的 Location 参数,会决定当天所有用户执行该查询的性能表现:
- 如果首次传入是像印度这样的用户较多的的地区,那么所有地区都会获得并行表扫描,并获得大量的内存授权。
- 如果首次传入的是圣地亚哥这类用户数量较少的地区,那么后续所有执行都会采用单线程的索引查找 + 键查找,且仅会被授予少量内存。
因此,在遭遇参数嗅探问题时,最糟糕的做法就是每天更新这张表的统计信息。这样一来,你每天上班都会面临 50% 的概率出现全表扫描,还有 50% 的概率出现临时数据库(TempDB)数据溢出的问题。每天都会遇到新的性能紧急问题 —— 即便表的实际数据分布根本没有任何变化。
对执行计划缓存有深入研究的工程师,可以通过查询系统视图 sys.dm_exec_query_stats 中的 plan_generation_num(执行计划生成次数)列发现这一问题。每当因统计信息变化等原因导致执行计划重新编译时,该列的数值就会递增。数值越高,说明执行计划的编译频率越高;但同时需要注意,即便 plan_generation_num 的值为 1,也不代表你的数据库不存在参数嗅探问题。(关于这一点,我会在《精通参数嗅探》课程中深入讲解.)
这也是为什么我会选择每周更新一次统计信息,除非有明确的理由,否则不会提高更新频率。在实际工作中,我遇到的参数嗅探问题,远比日期范围递增导致的统计信息失效问题要多。
我更倾向于将每周更新统计信息作为默认策略,这能让执行计划缓存更稳定,也能让工作日的早上少些麻烦。即便发现某类统计信息在一两天内就严重过期,我也不会改为每日更新 —— 而是会先尝试优化索引和查询语句,让 SQL Server 能更轻松地生成高速、高效的执行计划。因为如果为了解决如下这类查询的性能问题,就选择每日更新统计信息:
CREATE OR ALTER PROC dbo.usp_SearchUsersByDate
@LastAccessDateStart DATETIME,
@LastAccessDateEnd DATETIME
AS
SELECT *
FROM dbo.Users
WHERE LastAccessDate >= @LastAccessDateStart
AND LastAccessDate <= @LastAccessDateEnd
ORDER BY DisplayName;
GO
那你很可能忽略了一个重要问题:这个查询本身也极易遭遇参数嗅探问题!
在每日的统计信息更新任务完成后,如果有人恰好传入一个跨一年(或仅一小时)的时间范围参数,那么生成的执行计划又会再次失效,让所有用户的查询性能陷入困境。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号