GAIA:A benchmark for General AI Assistants
摘要
GAIA提出的真实世界问题需要一系列基本能力,如推理、多模态处理、网页浏览和一般工具使用熟练程度。
作者认为,人工智能( Artificial General Intelligence,AGI )的问世取决于系统在此类问题上表现出与人类平均水平相似的鲁棒性。
Introduction

GAIA benchmark的设计理念:
-
真实且有挑战性的问题
题目设计模拟现实世界的复杂性。模型通常需要:
-
浏览实时变化的互联网。
-
处理多模态信息(如图表、文档等)。
-
进行多步推理才能得出答案。
-
-
易于解释
任务在逻辑上对人类来说是简单的(非专家级别的普通人能获得近乎完美的准确率),但对模型却很难。它要求提供推理路径(reasoning trace),且题目数量少而精(highly curated),这使得评估结果非常直观、可靠。
-
非博弈性
由于任务涉及多个步骤且极具多样性,模型很难通过简单的匹配或记忆来完成。
-
答案不在互联网上以纯文本形式存在,防止了数据污染。
-
通过检查推理过程和要求的极高准确性,排除了靠运气答对的可能性。
-
-
使用便捷
-
答案形式简单: 答案是事实性的、简明且唯一的(factoid, concise and unambiguous),这使得评估过程非常快速且客观。
-
Zero-shot(零样本): 题目设计初衷就是让模型直接回答,不需要复杂的提示设置,从而消除了实验环境对评估结果的干扰。
-
GAIA
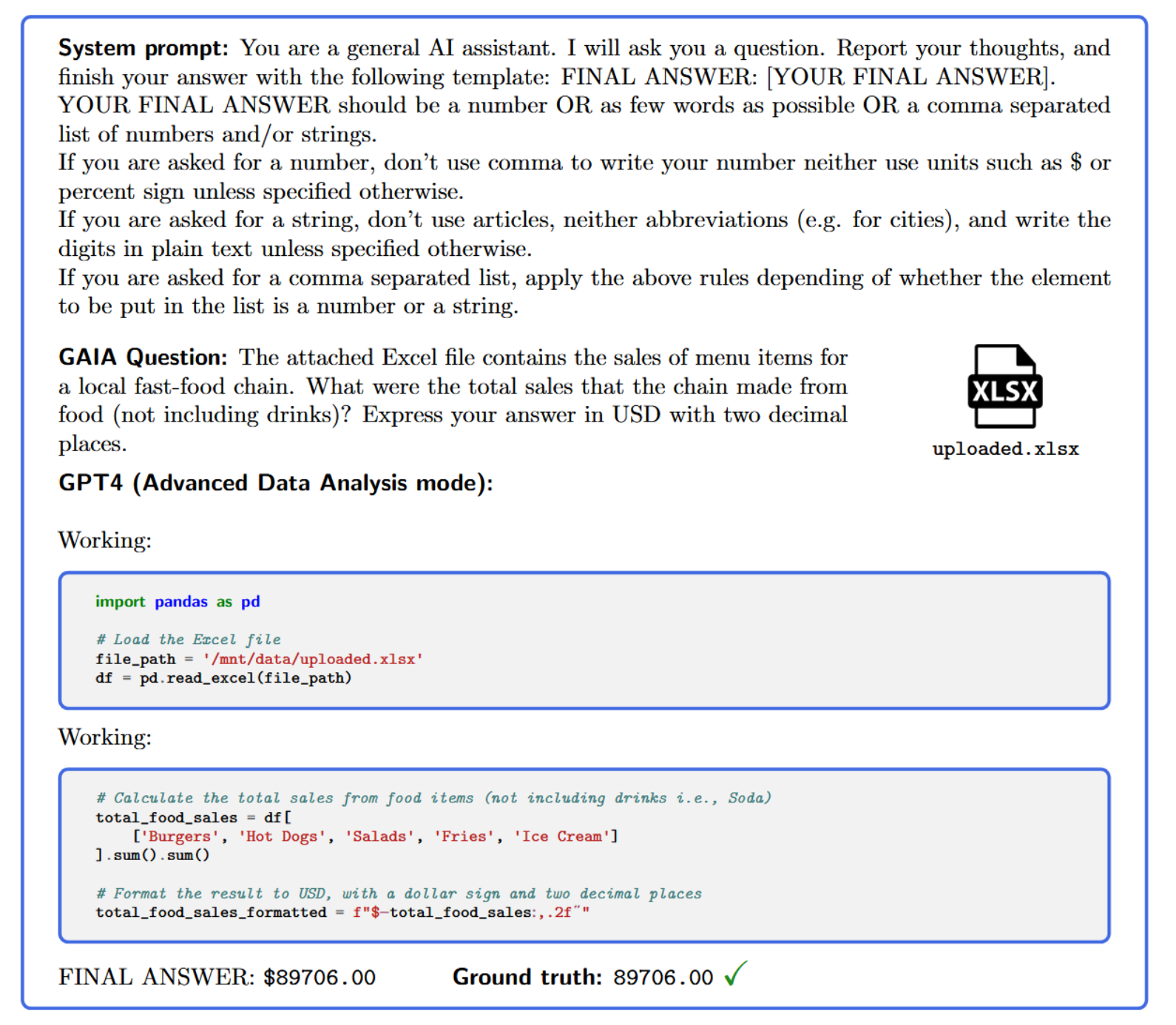
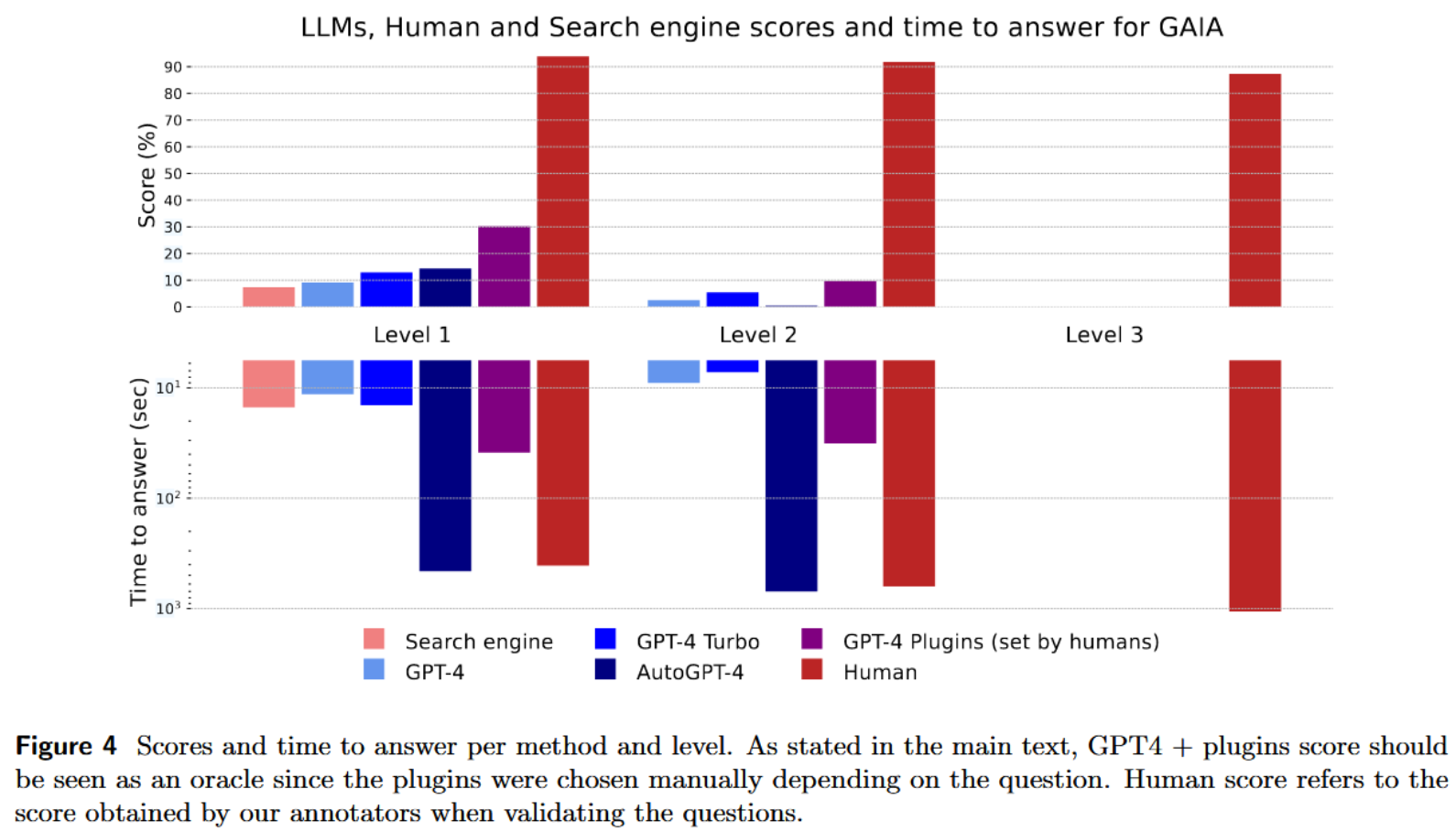
LLMs results on GAIA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号