
ViT
核心结论
当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。
但是当训练数据集不够大的时候,ViT的表现通常比同等大小的ResNets要差一些,因为Transformer和CNN相比缺少归纳偏置(inductive bias),即一种先验知识,提前做好的假设。
CNN具有两种归纳偏置
-
一种是局部性(locality/two-dimensional neighborhood structure),即图片上相邻的区域具有相似的特征;
-
一种是平移不变形(translation equivariance),f(g(x))=g(f(x)) 其中g代表卷积操作,f代表平移操作。
当CNN具有以上两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习一个比较好的模型
Abstract
虽然Transformer架构已经成为nlp的标准,但其在cv中的应用仍然有限。在视觉中,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持它们的整体结构。
我们证明了这种对CNN的依赖是不必要的,把那个且直接应用于图像块序列的纯transformer可以在图像分类任务上表现得更好。
当在大量数据上预训练并迁移到多个中小规模图像识别benchmarks时,与最先进的CNN相比,ViT获得了优异的结果,同时需要更少的计算资源来训练。
ViT的结构
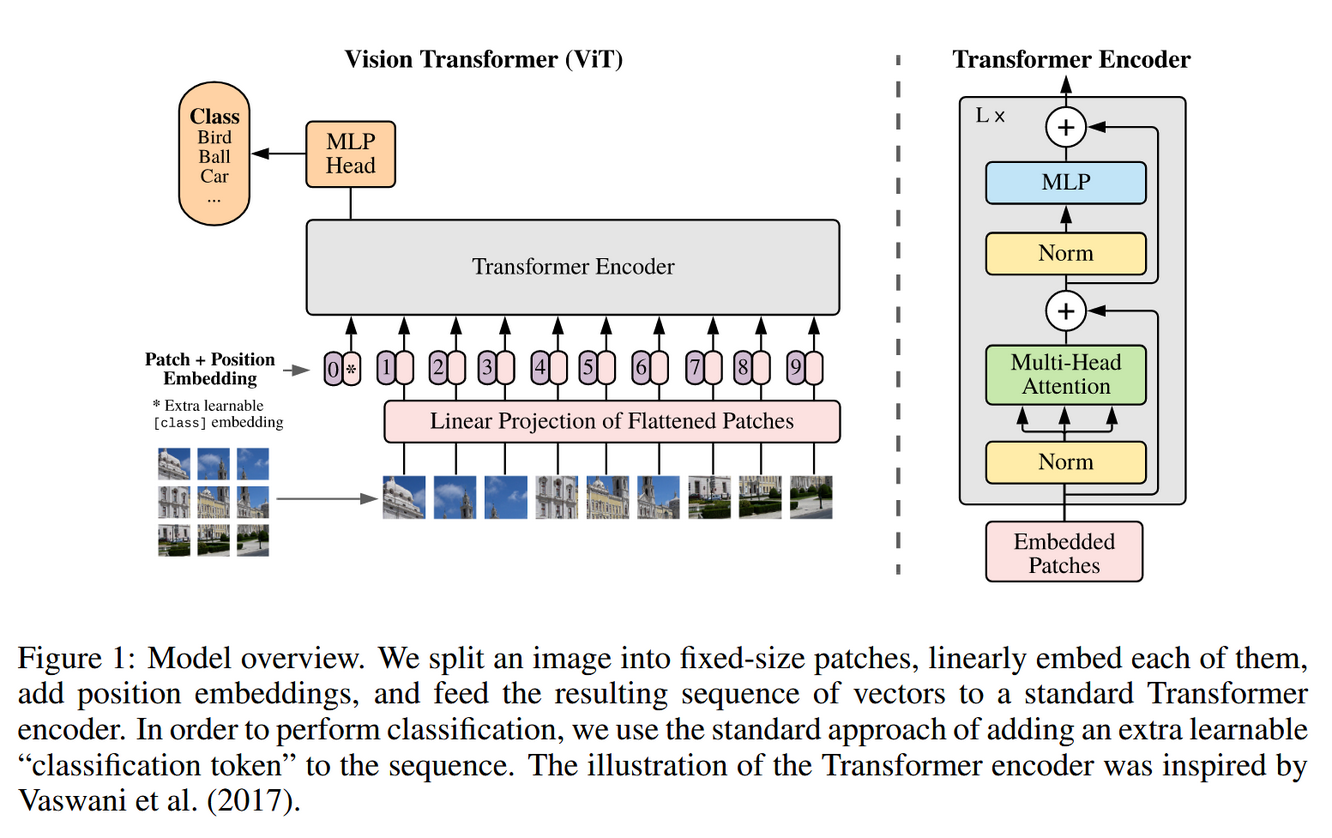
-
Patch Embedding,将图片分为固定大小的patch,从而将视觉问题转换为seq2seq问题
-
Position Embedding,加在patch embedding上
-
Transformer Encoder,经过多头自注意力层 MLP层(激活函数为GELU),最后提取[cls]对应的向量作为encoder的最终输出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号