

本文章是生产计划体系完整解决议定的第2篇 - 复杂大规模问题之 - 分区规划。
在完整的规划体系中,针对不同的场景与需求,需要对应的规划方案。在上一篇(生产计划体系完整解决方案(1) - 复杂大规模问题的分阶段规划)里,简述了分阶段规划方案,就是针对供应链中,从订单到生产环节中,以订单为单位对生产计划进行初步排程。具体的任务是“将某个订单,安排到哪个生产单位(通常是车间级别),在哪个时间点之前完成”。通常我们将该层次的生产计划称为主生产计划 - MPS。而在生产单位内,根据订单需求和产品的工艺路线、参数等进行拆解,生成最小粒度的生产任务,把这些生产任务分配到产线、机台、工位或班组等具体的生产资源,并根据工序路线的前后制约关系,推导出具体的任务计划开始与结束时间。在过程称为高级生产计划与排程,即我们常见的APS。
在APS的阶段,我们会遇到一些问题规模较大,从而引入规划效果不佳,甚至规划程序无法处理的情况。面对因数据量过大而无法处理的情况,我们首先需要考虑的是通过优化计划结构来缩小数据量。但若通过各种途径优化后,问题规划仍超出一个规划程序的处理范围时,我们就需要考虑一种折冲的解决办法 - 分区规划。
分区规划的定义
是指将一个大规模的待规划数据集(下称大规模问题),基于一定的规则,划分成多个较小规模的数据集(下称为子问题),并使用多个规划程序实体,对这些划分后的、规模较小的子问题进行分别规划求解;或将这些较小的子问题依次求解。获得各自子结果后,再合并成一个完成的、总体的规划结果,作为原始数据集的近似解。
从上述定义可知,分区规划实际是对一个大规模的、常规求解器难以运算求解的较大规模问题,的拆分求解法。是一种对问题进行分而治之的方法;可以理解为一种用空间换时间的求解策略。因为规划问题属于NP-Hard问题,它的其中一个典型特性是,随着数据量的增大,问题规模(通常表现为时间复杂度)呈指数级上升。当数据量增大到一定程度后,求解器(不管是开源的OptaPlanner还是其它商用求解器)面对的将是一个极其庞大的搜索空间(搜索空间可以理解为一个规划问题的所有可能方案的数量),甚至在一个问题被展开到内存后,数据量会突破一些程序语言运行时的空间(例如Java的JVM)。我们当然可以通过修改运行时的空间,并增大计算机的内存来容纳这个巨大的问题展开数据。但当这个数据量足够大时,需要从近乎无穷个可能解中,找出相对最优解的效率也会差得多。因此,同样会面临规划效果不佳的问题。因此,分区规划存在一定的实用价值。
分区规划的例子
APS
在APS的生产计划排程场景中,整个公司(或整体集团)多个车间之间的设备在分配任务时,有可能需要实现互相配合。因此,我们会将整个企业中所有车间的生产任务都统一成一个待排数据集进行排程。但当企业需要排程的任务量足够大时(例如企业产能与订单数量非常庞大、表需要预排非常长的周期),形成的待排数据集,其量级有可能越超过了OptaPlanner处理的数据量。
此时,我们可以考虑将各个车间独立成一个子数据集,各自进行排程;或将几个相关性较强的车间组合起来,相关性较低的车间划分成不同的子问题,整成不同的子数据集后,再对这些子数据集进行规划运算,并将结果合并成最终结果,作为整个企业的生产计划。
VRP
在VRP(车辆路线规划)场景中,若存在多个地区的运输订单统一规划车辆进行分配,并为车辆优化行驶路线。若该区域的收货、派货节点数量太大,就是出现OptaPlanner无法处理的问题。此时,我们可以考虑对该地区的节点进行再次划分成更小的子区域,对子区域的节点进行VRP规划后,再把这些子区域的结果合并成一个大的VRP结果。
分区规划的好处
提高CPU利用率
针对分区规划的具体应用场景,我们很容易就能总结出分区规划的好处了,那就是可以灵活、高效地处理大规划的问题,令求解器可以更轻松地处理搜索空间巨大的情况。
虽然我们针对一个单一的大规模问题,也可通启用多线程来提高CPU利用率,从而提高求解效率。但在多线程运算过程中,它针对的仍然是同一个问题,多线程的调度器会合理分配各个CPU核心的运算内容,尽可能减少各线程之间的通讯,来减少各线程的CPU切换时间。但事实上,从业务逻辑的角度来看,各个线程之间的运算内容或多或少都会存在一定的交互需求,因此,使用多线程对同一问题进行求解时,可以起到提高CPU各核心利用率的效果,但各线程之间的通讯、CPU对线程的切换是不可避免的。
而当我们使用分区规划时,被划分的子问题之间,从业务上是不存在相关性的,可以从逻辑上避免了不必要的线程通讯和CPU切换,从而大大提高CPU的运算率。
下图是OptaPlanner用户手册中,关于分区规划时,多线程并行运算时,在多核CPU平台上运算的过程,在此就不翻译了,大家可以细心分析一下是否确实能提高规划运算的效率。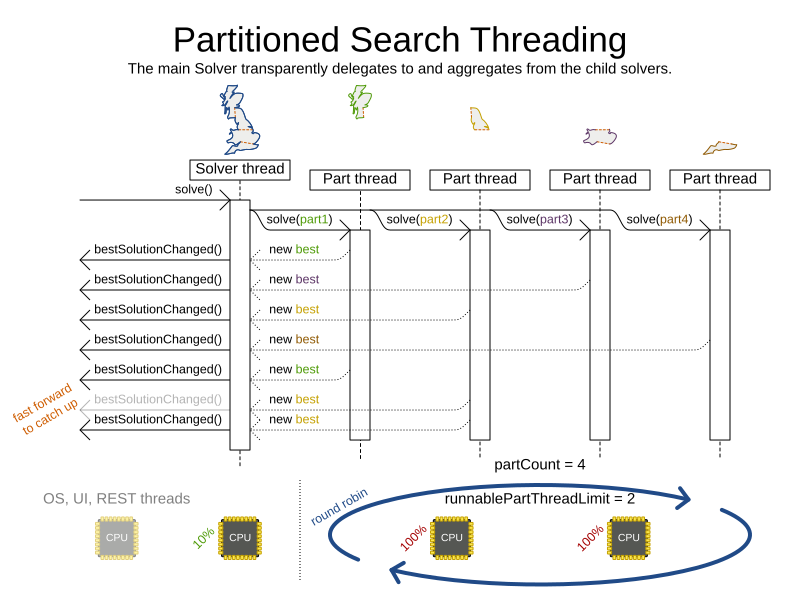
指数级降低问题规模
因为规划问题是NP-Hard问题,对于同一个问题,当我们将它视作一个问题来解决时,其搜索空间会与数据量形成指数函数问题,因此,同样的数据量,划分成多个子问题时,其问题空间会少得多。
举个例子:我们将问题简单一下,若数据集中共有8条数据,每个规划变量有2种取值可能,那么,整个问题的搜索空间是:
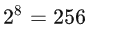
若将这个问题的8条数据,平均划分成2个子问题时,则每个问题有4条数据,它的搜索空间是:
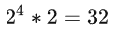
若将这个问题的8条数据,平均划分成4个子问题时,则每个问题有2条数据,它的搜索空间是:
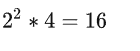
总结上面的数据,我们可以知道,通过划分成子问题的方式,可以极大地降低问题的搜索空间,从而让求解器在可接受时间内完成对问题的求解。
那么,我们是不是把问题划分得越细越好?(这里留个问题,大家可以思考一下)
分区规划的缺陷
在实际应用场景中,可以作为一个数据集呈现的整体问题,其中各个数据之间必然存在一定的相关性,否则没有必然作为一个整体问题提出。当我们将它拆分成多个子问题时,这些子问题的组成的问题分集合必然出现一定程度的失真,即可能存在部分关系的数据,其关联关系将会不复存在。对每个子问题进行规划运算时,引擎只能考虑当前子问题数据集的数据相关性,当前子问题数据与其它子问题数据之间,并会影响规划结果的关系则无法体现,从而导致从各个子问题合并成整体问题(即大问题)结果时,与原始整体问题对应的相对最优解寻在差异,即出现失真。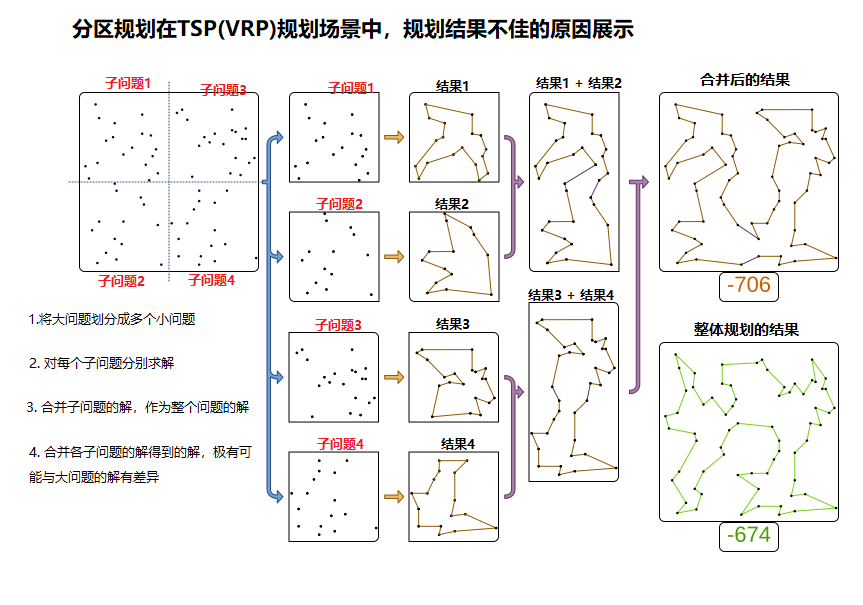
上图描述了TSP(或VRP)场景中,将一个大问题的数据集划分成4个小问题进行分别规划的过程。
由于整个TSP大问题中,需要访问的节点数量超出求解器可求解的上限,因此,将整个地图上所有待访问节点,按地区进行横纵划分成4个区分,分别形成子问题1、子问题2、子问题2和子问题4,然后对这4个子问题分别作为一个TSP数据集进行求解,分别得到结果1~4。再将这4个结果进行合并,得到的方案,其评分为-706分。可以理解为,这个合并结果其访问里程总量为706公里。而若将整体数据集一次过进行规划(假设其数据量可以被求解),得到的结果是-674(即里程更短,因此方案更优)。这个结果相比分区规划后再合并的结果更优,即分区规划的结果有可能相比整体规划更差,即进现失真情况。
OptaPlanner对分区规划的实现
针对分区规划的应用,OptaPlanner提供的开箱即用的特性来实现之。以下用户手册内容详细讲解了如何对一个问题的数据集进行分区规划求解.
https://docs.optaplanner.org/8.29.0.Final/optaplanner-docs/html_single/index.html#partitionedSearch
以下是一翻推广:
诚邀大家使用我们的【易排通用智能规划平台】,它基于OptaPlanner对APS的一些常用规划逻辑进行封装,大家只需要管理、维护好自己系统(使用MES、MOM、ERP中的计划模块)中的工单数据,即可快速地实现一个APS模块。后续我们还会添加【VRP - 车辆路径规划】和【在线调度】模块,敬请期待。可以通过以下链接查看更多该平台的使用方法。
与平台相关疑问,可以添加本人微信探讨,或关注我们的公众号【让APS成为可能】及时接收相关消息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号