Python学习摘要201802
- 【基础】变量设计机制
【个人理解】python的变量与C++语言中的指针类似,是指向内存数据的一个引用。变量分为不可变变量string/int/float/tuple和可变变量list/dict。
对于不可变量如果需要创建的对象的内容(value值)相同,则引用都指向同一个对象,不创建新的内存空间。
理论上因为定义了值是不可变的。所以如果大家都一样的值,那就指向同一份内存空间好了。显然这么节省内存,避免冗余。
对于可变量只要创建对象那就是本质是new一个新的内存空间,但是好处是能够修改。即修改对象值不会新开辟对象而是就是在原来内存空间改。
变量无类型,对象有类型 使用一个变量之前不需要提前声明,只需要在使用的时候赋值。
![]()
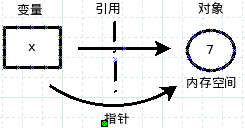
严格地说明,只有放在内存空间中对象才有类型,而变量是没有类型的。一个变量只能对应只一个对象,一个对象可以对应多个变量。
【基础】深度拷贝实现机制
【个人理解】深度拷贝是针对可变变量进行内存复制的。机制不清楚。
浅度拷贝:copy.copy,会创建的一个新的对象,如果是list对象,对于list对象的元素浅拷贝就只会使用原始元素的引用(内存地址)。
深度拷贝:copy.deepcopy,会创建一个新的对象。如果是list对象,对于list对象的元素,深拷贝都会重新生成一份,而不是简单的使用原始元素的引用。
对于不可以变的变量对象,不能拷贝,浅度拷贝和深度拷贝都是一样的。new() 与 init()的区别
【个人理解】init()可以认为是__new__()的包装的外壳,在定义类中必须要定义这个方法,可以传入类对象的属性值。__new__()类对象申请内存空间的方法?
__new__是类方法,参数中带有cls,代表实例化的类。继承自object的新式类才有__new__。
__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类__new__出来的实例,或者直接是object的__new__出来的实例。
__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值
实例化一个类时,__new__是首先被调用的,然后才是__init__调用。
__new__是创建类实例的方法,可以创建单例模式的实例对象生成。__init__是实例创建后的方法。
- 列表推导和生成器的区别及优劣
【个人理解】列表推导通过较短的代码(一行)快速生成一个相应的列表变量。生成器是指生成可迭代对象,可迭代对象动态通过next方法生成列表元素。列表推导在内存中生成大量的数据,生成器是动态根据算法纪念性推导算出。
列表推导的方法是直接在内存中生成对象的数据,这样需要占用内存空间。
在python中,既可以循环又可以计算的对象成为生成器,生成器实现了迭代器协议,可迭代对象。
g = (i for i in range(10**100))#生成器表达式
l = [i for i in range(10**100)]#列表生成式
print g.__next__()#更省内存,需要一个取一个
print l.__next__()#需要在内存中创建1行10**100列的序列另外,使用了yield替代return的函数称之为生成器函数。生成器函数和其他函数的执行流程不一样,其他函数是顺序执行,遇到return语句或者最后一行函数语句就结束。在调用生成器运行过程中,每次遇到yield时函数会暂停并保存当前所有的运行信息,返回yield值。并在下一次执行next方法时,从当前位置继续运行。
编码和解码
【个人理解】编码和解码的问题我认为是一个翻译的问题。unicode是计算机的标准语言,其他的utf-8或者gbk都是不同体系的语言,编码的过程是把unicode翻译到对应体系的语言,解码的过程是把不同的体系语言翻译成unicode的过程。
参见以前写的博文基于Python的数据分析(2):字符串编码装饰器、wraps的使用、单例模式
【个人理解】装饰器是函数或者类的对象的外壳,可以在指定被装饰的函数调用前后加入特定的功能。Python装饰器的作用是提高代码的简洁,降低代码的耦合性,将代码要执行的业务逻辑和公共功能进行分离,业务逻辑通过具体的函数来实现,公共功能(例如日志记录,权限认证,输入检查等等)由装饰器负责,代码耦合性降低的同时复用成都也大大提高。
在 Python 中,使用关键字 def 和一个函数名以及一个可选的参数列表来定义函数。函数使用 return 关键字来返回值。Python 允许创建内嵌函数。即可以在函数内部声明函数,并且所有的作用域和生命周期规则仍然适用。装饰器其实就是一个以函数作为参数并返回一个替换函数的可执行函数。
注意:1.@符号是装饰器的语法糖,在定义函数的时候使用,避免再一次赋值操作。2.args 可以表示在调用函数时从迭代器中取出位置参数, 也可以表示在定义函数时接收额外的位置参数。3. kwargs 来表示所有未捕获的关键字参数将会被存储在字典 kwargs。
除了函数装饰器,还有一个类型叫做类装饰器。类装饰器*具有灵活度打、高内聚、封装性等优点。使用类装饰器以来内部的__call__方法,当使用语法糖@附加到函数上时,就可以调用此方法。注意带参数和不带参数的两种类装饰器的区别。
#不带参数的类装饰器
class Check(object):
def __init__(self, func):
self.func = func
def __call__(self, *args,**kwargs):
print("111111")
self.func(*args,**kwargs)
print("222222")
@Check
def param_check(request):
print(request)
param_check('hello')
param_check('world')
#带参数的类装饰器
class Check(object):
def __init__(self, name):
self.name = name
def __call__(self, func):
print ("1111111111")
def decorator(*args, **kwargs):
print ("2222222222")
return func(*args, **kwargs)
return decorator
@Check('parm')
def param_check():
print('Hello')
param_check()
param_check()Python装饰器(decorator)在实现的时候,被装饰后的函数其实已经是另外一个函数了(函数名等函数属性会发生改变),为了不影响,Python的functools包中提供了一个叫wraps的decorator来消除这样的副作用。写一个decorator的时候,最好在实现之前加上functools的wrap,它能保留原有函数的名称和docstring。
装饰器的单例模式:
def singleton(cls, *args, **kw):
instance={}
def _singleton():
if cls not in instance:
instance[cls]=cls(*args, **kw)
return instance[cls]
return _singleton
@singleton
class test_singleton(object):
def __init__(self):
self.num_sum=0
def add(self):
self.num_sum=100正则表达式
【个人理解】从文本信息中匹配或者抽取制定规则的信息。垃圾回收
【个人理解】内存回收。
python的内存回收机制是引用计数策略。对Python语言来讲,对象的类型和内存都是在运行时确定的。这也是为什么我们称Python语言为动态类型的原因(这里我们把动态类型可以简单的归结为对变量内存地址的分配是在运行时自动判断变量类型并对变量进行赋值)。
解释器负责跟踪对象的引用计数,垃圾收集器负责释放内存。
通过销毁对象的引用,使引用计数减少至 0。
假设 x = 3,以下情况会使 3 这个整型对象的引用计数减少:
- 函数运行结束,所有局部变量都被销毁,对象的引用计数也就随之减少。例如 foo(x) 运行结束,x 被销毁;
- 当变量被赋值给另一个对象时,原对象的引用计数也会减少。例如 x = 4,这时候 3 这个对象的引用计数就减 1 了;
- 使用 del 删除一个变量也会导致对象引用减少。例如 del x;
对象从集合对象中移除。例如 lst.remove(x);包含对象的集合对象被销毁。例如 del lst。
![]()
Python的内存机制以金字塔行,-1,-2层主要有操作系统进行操作;第0层是C中的malloc,free等内存分配和释放函数进行操作;第1层和第2层是内存池,有Python的接口函数,PyMem_Malloc函数实现,当对象小于256K时有该层直接分配内存;第3层是最上层,也就是我们对Python对象的直接操作。
垃圾回收时,Python不能进行其它的任务。频繁的垃圾回收将大大降低Python的工作效率。如果内存中的对象不多,就没有必要总启动垃圾回收。所以,Python只会在特定条件下,自动启动垃圾回收。当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动。可以手动启动gc.collect.
当内存中有不再使用的部分时,垃圾收集器就会把他们清理掉。它会去检查那些引用计数为0的对象,然后清除其在内存的空间。当然除了引用计数为0的会被清除,还有一种情况也会被垃圾收集器清掉:当两个对象相互引用时,他们本身其他的引用已经为0了。垃圾回收机制还有一个循环垃圾回收器, 通过消除引用换的方式释放循环引用对象(a引用b, b引用a, 导致其引用计数永远不为0)。

多进程和多线程
协程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号