你应该知道的ConcurrentSkipListMap的细节
Redis中也用到了“跳表”这种数据结构,但是Redis是用C/C++语言编写的,对Java程序员来说不是特别友善。所以我们借助阅读
java.util.concurrent.ConcurrentSkipListMap来了解一下“跳表”吧。
1.认识数据结构
索引与数据分开:ConcurrentSkipListMap 将 代表索引的结点 和 代表数据的结点 分开。一个是代表索引的类Index<K,V>,另一个是代表数据的类Node<K,V>
1.1. 数据结点
数据结点采用经典的“单链表”结构来存储。
- next域:它包含一个
next来指向后继结点。 - data域:因为这是一个Map,所以它用 key 和 value 共同组成 data 域。
- 头结点:当没有数据时,单链表中会包含一个空的头结点。该头结点的
value等于BASE_HEADER(private static final Object BASE_HEADER = new Object();),头结点的key和next都等于null。

1.2 索引结点
索引结点采用的是 类似树的 二维的 链接的 “跳表”。

-
HeadIndex<K,V>是Index<K,V>的子类,多一个属性level。- 头索引结点
level表示由right链接的这一行的索引所在的层级。 - 最低的索引层级是1,越往上,层级越高。
- 头索引结点
-
所有的
Index<K,V>都有一个node属性,可以获取数据结点的信息。HeadIndex<K,V>也是Index<K,V>, 所有HeadIndex<k,V>的node属性都指向唯一的数据结点单链表的头结点。
1.3 初始化状态
假如我们用new ConcurrentSkipListMap()创建一个由“跳表”实现的Map, 那么初始化的结构如图所示:

当对象刚创建时:
- 成员变量
head指向左上角的HeadIndex对象; - 初始化状态只有一层索引,此时,成员变量
head指向最左上角的HeadIndex对象,这个对象的level值为 1; HeadIndex对象的成员变量node指向数据头结点;- 数据头结点对象的
value为静态常量成员变量BASE_HEADER,其他的属性key和next目前均为null
2 放入键值对
put 操作既不允许 key 为 null,也不允许 value 为 null。否则会抛出 NullPoniterException。
put 操作主要包含三大块:寻找插入新数据结点的位置(findPredecessor),创建数据结点并插入数据结点链表,为数据结点创建索引。
我先来谈一下,ConcurrentSkipListMap 最特别的部分————为数据结点创建索引;
创建数据结点并插入数据结点链表,这个没有太多新意,就不赘述了;
最后,我们再来看一下“寻找插入新数据节点的位置”的逻辑。
2.1 为数据结点创建索引
2.1.1 所有数据都有索引?
第一个问题:是不是所有的数据结点都有索引结点?
答案:否。是否给新建的数据结点创建索引结点是随机事件。
来看doPut方法中的一段源码:
int rnd = ThreadLocalRandom.nextSecondarySeed();
// 条件成立: rnd的最高位和最低位都为0
if ((rnd & 0x80000001) == 0) {
...
}
rnd保存的是随机数;- 当
rnd由十进制转换为二进制表示时,它的最高位和最低位都为0,则条件成立,创建索引; - 当
rnd表示为二进制时,它的最高位或者最低位包含0,则不创建索引;
2.1.2 为数据创建几级索引?
第二个问题:我们知道“跳表”的索引是有层级的,我们需要在哪几层创建索引呢?
解析:
⑴ 首先,我们再来看doPut方法中的一段源码:
// 因为 rnd 的二进制形式的最低位和最高位均为0时,才会创建索引:
// 如果 rnd 的二进制形式的最后两位是 00, 且最高位是0, level最终等于1
// 如果 rnd 的二进制形式的最后三位是 010, 且最高位是0,level最终等于2
// 如果 rnd 的二进制形式的最后三位是 0110, 且最高位是0,level最终等于3
// 如果 rnd 的二进制形式的最后四位是 01110, 且最高位是0,level最终等于4
// 依此类推...
while (((rnd >>>= 1) & 1) != 0)
++level;
⑵ level 并不直接等于创建几个索引,还需要分情况讨论,继续看源码:
HeadIndex<K,V> h = head;
// level 表示期望的索引层数
// max 表示目前的最大索引层数
if (level <= (max = h.level)) {
// case1: 假设 h.level 等于3, 计算出的 level <=3。
} else {
// case2: 假设 h.level 等于3, 计算出的 level > 3。
}
⑵① 首先看一下 case1 的情况,创建索引的代码如下:
for (int i = 1; i <= level; ++i)
idx = new Index<K,V>(z, idx, null);

- 所有的索引的
node属性都指向同一个数据结点z; - 局部变量
idx,在循环执行结束后,指向最上层的索引对象; - 局部变量
level等于几,就创建几级索引; - 在执行完上面的循环之后,索引还未正式加入到索引表中,此时,新创建的结点还是索引不到的,即get不到的;
- 第一层级(
level-1)的索引的down为null
⑵② 再来看一下 case2 的情况,创建索引的代码如下:
// 设置level比当前最高层级 还多一
level = max + 1; // hold in array and later pick the one to use
Index<K,V>[] idxs = (Index<K,V>[])new Index<?,?>[level+1];
// 用数组保存每一层的索引对象的引用, idxs[0]不存Index对象。
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index<K,V>(z, idx, null);
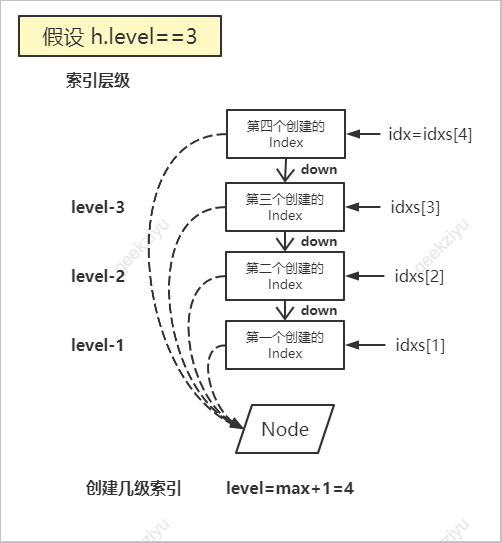
- 创建了比当前索引层级N多一级的索引,即创建了N+1个索引;
- 局部变量
idx在循环结束后,指向最上层的索引对象; idxs[0]为 null,idxs[N]指向第N层的索引对象;- 第一层级(
level-1)的索引的down为null; - 目前所有的索引对象还未加入到索引表中,没有其他索引表中的索引的
right指向idxs数组中任意一个索引,且idxs数组中的索引的right均为null
2.1.3 索引如何生效?
第三个问题:现在数据结点的N级索引已经创建出来了,那么要怎么把新建的索引链接到跳跃表中呢?
解析:当新建的索引层级 大于 当前跳跃表的索引层级 时,需要执行以下代码:
// case2: 假设 h.level 等于3, 计算出的 level > 3,然后 level 被重置为 4。
// 重置 level 值, 设置成更合理的值, 即等于 当前跳跃表索引层级 + 1。
level = max + 1; // hold in array and later pick the one to use
@SuppressWarnings("unchecked")Index<K,V>[] idxs =
(Index<K,V>[])new Index<?,?>[level+1];
// 用数组保存每一层的索引对象的引用
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index<K,V>(z, idx, null);
// index-4 ← idx ← idxs[4]
// ↓
// index-3 ← idxs[3]
// ↓
// index-2 ← idxs[2]
// ↓
// index-1 ← idxs[1]
// ↓
// z-node
for (;;) {
// 跳跃表 最左上角的HeadIndex索引
h = head;
// 获取当前 跳跃表 的最大高度
int oldLevel = h.level;
// 条件成立: 其他线程先一步完成了索引的创建, 当前线程重新自旋
if (level <= oldLevel) // lost race to add level
break;
// newh 最终会指向新创建的 HeadIndex, 当前指向跳跃表目前的 head
HeadIndex<K,V> newh = h;
// oldbase 指的是数据结点 单链表 的头结点。
Node<K,V> oldbase = h.node;
// 通常来说,循环只会执行一次
for (int j = oldLevel+1; j <= level; ++j)
newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j);
// 上面这一步最大作用就是创建了 headIndex-4 并且它的 right 指向了 index-4, down 指向了 headI
// newh 从指向 headIndex-3 变为指向 headIndex-4
// right
// level-4: headIndex-4 → index-4 ← idxs[4]
// ↓ down ↓
// level-3: headIndex-3 index-3
// ↓ ↓
// level-2: headIndex-2 index-2
// ↓ ↓
// level-1: headIndex-1 index-1
// ↓ ↓
// base_header z-node
// 把 newh 赋值给 head
// casHead 成功之后, 会将跳表的 head 字段指向跳跃表左上角的 headIndex
if (casHead(h, newh)) {
// 更新 h 指向 跳跃表左上角的 headIndex
h = newh;
// level-4 只有一个新的索引结点,且已经和 headIndex-4 链接起来了
// 重置 level, 接下来链接剩余层级的索引 到 跳跃表中。
// 因为 z-node 最上层的 index 已经和 base_header 的最上层 headIndex 链接起来了,
// z-node 的最上层下面的 index 都没还没有链接到相应层级的 链表中,
// 这里让 idx 指向 z-node 所有索引中的倒数第二层
idx = idxs[level = oldLevel];
break;
}
}
除了最上层的索引已经加入到跳跃表了,其他层级的索引还未加入跳跃表。
在doPut的源码中, 有一个 splice: 标出的自旋代码段,这段代码的作用就是把 新建的每个索引 插入到 对应层级的 索引链表中。
所以,接下来无论是新建的索引层级 大于或者等于或者小于 当前跳跃表的索引层级,都需要执行 splice 的逻辑:
// 这块代码主要是寻找合适的插入点,然后就可以将索引插入到 q 和 r 之间了
if (r != null) {
Node<K,V> n = r.node;
// compare before deletion check avoids needing recheck
int c = cpr(cmp, key, n.key);
if (n.value == null) {
if (!q.unlink(r))
break;
r = q.right;
continue;
}
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
所以把这块代码忽略后的代码是这样的:
splice: for (int insertionLevel = level;;) {
int j = h.level;
for (Index<K,V> q = h, r = q.right, t = idx;;) {
if (q == null || t == null)
break splice;
...
if (j == insertionLevel) {
if (!q.link(r, t))
break; // restart
...
if (--insertionLevel == 0)
break splice;
}
if (--j >= insertionLevel && j < level)
t = t.down;
q = q.down;
r = q.right;
}
}
初始值:insertionLevel=3, j=4 时
| 本轮开始时j | 本轮开始时insertionLevel | j == insertionLevel | --insertionLevel == 0 | --j >= insertionLevel && j < level | |
|---|---|---|---|---|---|
| 第一轮循环 | 4 | 3 | 4 == 3 不成立 | 不执行 | 3 >= 3 && 3 < 3 不成立 |
| 第二轮循环 | 3 | 3 | 3 == 3 成立 | 2 == 0 不成立 | 2 >= 2 && 2 < 3 成立 |
| 第三轮循环 | 2 | 2 | 2 == 2 成立 | 1 == 0 不成立 | 1 >= 1 && 1 < 3 成立 |
| 第四轮循环 | 1 | 1 | 1 == 1 成立 | 0 == 0 成立 | 不执行 |
初始值:insertionLevel=3, j=3 时
| 本轮开始时j | 本轮开始时insertionLevel | j == insertionLevel | --insertionLevel == 0 | --j >= insertionLevel && j < level | |
|---|---|---|---|---|---|
| 第一轮循环 | 3 | 3 | 3 == 3 成立 | 2 == 0 不成立 | 2 >= 2 && 2 < 3 成立 |
| 第二轮循环 | 2 | 2 | 2 == 2 成立 | 1 == 0 不成立 | 1 >= 1 && 1 < 3 成立 |
| 第三轮循环 | 1 | 1 | 1 == 1 成立 | 0 == 0 成立 | 不执行 |
初始值: insertionLevel=2, j=3 时
| 本轮开始时j | 本轮开始时insertionLevel | j == insertionLevel | --insertionLevel == 0 | --j >= insertionLevel && j < level | |
|---|---|---|---|---|---|
| 第一轮循环 | 3 | 2 | 3 == 2 不成立 | 不执行 | 2 >= 2 && 2 < 2 不成立 |
| 第二轮循环 | 2 | 2 | 2 == 2 成立 | 1 == 0 不成立 | 1 >= 1 && 1 < 2 成立 |
| 第三轮循环 | 1 | 1 | 1 == 1 成立 | 0 == 0 成立 | 不执行 |
3.删除数据
- 第一步寻找要删除的结点
- 删除数据结点
- 删除数据结点对应的所有索引
- 如果顶层没有索引结点,考虑降低索引层级
3.1 删除数据结点
其中删除数据结点,如下图所示:

3.2 索引降级
private void tryReduceLevel() {
HeadIndex<K,V> h = head;
HeadIndex<K,V> d;
HeadIndex<K,V> e;
// 为了减少错误和减少滞后,只有当最上面的三个级别看起来是空的时,索引级别才会减少一。
// 假设当前 跳跃表的 最高索引层级是 6
// h → headIndex-6 → null
// ↓
// d → headIndex-5 → null
// ↓
// e → headIndex-4 → null
// ↓
// headIndex-3 → ...
// ↓
// headIndex-2 → ...
// ↓
// headIndex-2 → ...
// ↓
// base_header → ...
//
// casHead 将 head 从 headIndex-6 调整到 headIndex-5, 完成降级。
if (h.level > 3 &&
(d = (HeadIndex<K,V>)h.down) != null &&
(e = (HeadIndex<K,V>)d.down) != null &&
e.right == null &&
d.right == null &&
h.right == null &&
casHead(h, d) && // try to set
h.right != null) // recheck
casHead(d, h); // try to backout
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号