HashMap死循环【基于JDK1.7】情景重现与分析(带示意图)
简介
JDK1.7 中 HashMap 多线程成环问题,几乎已经成了Java程序员人人需要了解的知识了,本文就带大家来一切重现一下 HashMap 死循环 ?
前置知识复习
阅读本文前,最好确保你知道 JDK1.7 实现的 HashMap (以下简称 HashMap)learn more 有以下几个特点:
-
首先 HashMap 采用的数据结构是数组 + 链表。
-
使用 new HashMap() 创建对象时,如果构造器参数中没有传入数据,那么就不会调用 inflateTable 来为 table 数组申请内存。
-
HashMap 的成员变量 threshold 表示扩容发生的边界值,loadFactor 表示负载因子,table.length 可以表示内部容量。
-
HashMap 扩容判断是在调用 put 或者 putAll 的时候,且如果需要扩容,扩容(resize)发生在实际插入新数据(createEntry)之前。以 put 举例,扩容条件是
(size >= threshold) && (null != table[bucketIndex])这个稍后举例。 -
HashMap 当前内部容量总是 \(2^n\),每次扩容 Entry 数组长度扩大 1 倍,即新容量为 \(2^{n+1}\)。threshold 总是等于 capacity * loadFactor
-
HashMap 的扩容方法是 resize,扩容时需要创建一个新的 Entry 数组,然后把数据从旧的 Entry 数组迁移到新的 Entry 数组,这个过程的迁移函数是 transfer
哈希算法
哈希算法就是把任意长度的消息压缩至固定长度的消息摘要。相同的输入经过 hash 函数计算得到的结果总是相同的。
虽然从理论上讲,只要哈希结果长度足够长,那么不同的输入,就会产生各不相同的散列值。
然而事实上,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出。此时就会产生哈希冲突。
解决哈希冲突的方法有很多种,HashMap 采用的是链式地址法,也就产生了数组 + 链表的数据结构。
HashMap 利用了哈希算法,把当前元素的关键字通过某个函数映射到数组中的某个位置。

算法:先求输入对象 key 的 hashCode,然后再经过高低位异或计算(^) 得到最终的散列值 hash,然后再调用 indexFor,得到数组下标。
通过反射访问 HashMap 成员方法
现在,我们不能直接调用 indexFor,hash,capacity 这些成员方法,所以我写了一个 HashMapWrapper 来封装反射逻辑。
import java.lang.reflect.Field;
import java.lang.reflect.Method;
import java.util.*;
public class HashMapWrapper {
// 代理 java.util.HashMap 类
private HashMap hashMap;
public HashMapWrapper(HashMap hashMap) {
this.hashMap = hashMap;
}
// 计算对象 k 在 Entry 数组的数组下标
public int indexFor(Object k) {
return indexFor(hash(k), capacity());
}
// 通过反射运行 HashMap#hash(Object)
int hash(Object k) {
try {
Method hash = HashMap.class.getDeclaredMethod("hash", Object.class);
hash.setAccessible(true);
return (Integer) hash.invoke(hashMap, k);
} catch (Exception e) {
e.printStackTrace();
}
return -1;
}
// 通过反射运行 HashMap#indexFor(int, int)
int indexFor(int h, int length) {
try {
Method indexFor = HashMap.class.getDeclaredMethod("indexFor", int.class, int.class);
indexFor.setAccessible(true);
return (Integer) indexFor.invoke(hashMap, h, length);
} catch (Exception e) {
e.printStackTrace();
}
return -1;
}
// 通过反射运行 HashMap#capacity()
int capacity() {
try {
Method capacity = HashMap.class.getDeclaredMethod("capacity");
capacity.setAccessible(true);
return (Integer) capacity.invoke(hashMap);
} catch (Exception e) {
e.printStackTrace();
}
return -1;
}
// 获取 Entry 数组指定下标下的链表
LinkedList<Object> getKeysOfTable(int index) {
LinkedList<Object> result = new LinkedList<Object>();
try {
// 通过反射访问 HashMap#table 即 Entry 数组
Field table = HashMap.class.getDeclaredField("table");
table.setAccessible(true);
Object[] array = (Object[]) table.get(hashMap);
getKeys(array[index], result);
return result;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
// 递归函数,辅助遍历 Entry 链表结构,并将 Entry 的 key 添加到 keys 链表中
private void getKeys(Object o, LinkedList<Object> keys) throws Exception {
if (o == null) return;
Field key = o.getClass().getDeclaredField("key");
key.setAccessible(true);
keys.add(key.get(o));
Field next = o.getClass().getDeclaredField("next");
next.setAccessible(true);
getKeys(next.get(o), keys);
}
}
找出发生哈希冲突的输入值
对应不同的关键字可能获得相同的 hash 值,即 key1≠key2,但是 f(key1)=f(key2)。这种现象就是哈希冲突。
现在我想要找出一组能够产生哈希冲突的关键字。而且成环的条件至少需要 2 个 Entry 元素,且 next 互相指向彼此。
因此,我需要找的这组关键字,扩容前会在同一地址发生哈希冲突,且扩容后仍然会在同一地址发生哈希冲突
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
HashMap<Integer, Object> hashMap = new HashMap<Integer, Object>(4);
HashMapWrapper wrapper = new HashMapWrapper(hashMap);
// new HashMap 之后,不会立即给 Entry 数组分配内存
// HashMap 是允许 null 作为 key 的,因此我用 null 来触发 inflateTable 初始化 Entry 数组
hashMap.put(null, null);
for (int i = 0; i < 100; i++) {
int index = wrapper.indexFor(i);
// 寻找在数组下标为 1 的位置发生冲突的关键字
if (index == 1) {
System.out.print(i);
System.out.print(" ");
}
}
}
}
初始容量为 4 时,在数组下标为 1 位置发生哈希冲突的关键字如下:
1 5 9 13 16 20 24 28 35 39 43 47 50 54 58 62 65 69 73 77 80 84 88 92 99
修改初始容量为 8 时,在数组下标为 1 位置发生哈希冲突的关键字如下:
1 9 16 24 35 43 50 58 69 77 84 92
我挑选了 1 9 16 24 作为我的实验值。
单一线程 HashMap 扩容
import java.util.HashMap;
public class ShowNoProblem {
public static void main(String[] args) {
HashMap<Integer, Object> hashMap = new HashMap<Integer, Object>(4, 0.5f);
HashMapWrapper wrapper = new HashMapWrapper(hashMap);
hashMap.put(1, null);
hashMap.put(9, null);
System.out.println("扩容前容量:" + wrapper.capacity());
System.out.println(wrapper.getKeysOfTable(1));
hashMap.put(16, null);
System.out.println("扩容后容量:" + wrapper.capacity());
System.out.println(wrapper.getKeysOfTable(1));
}
}
控制台输出结果如下:
扩容前容量:4
[9, 1]
扩容后容量:8
[16, 1, 9]

HashMap.Entry 有 key, value, hash, next 四个属性。图中主要展示了三种属性,并且反映出了 HashMap 的数组 + 链表的数据结构。
resize 扩容函数
void resize(int newCapacity) {
// 暂存老 Entry 数组的引用
Entry[] oldTable = table;
// 暂存老 Entry 数组的内部容量
int oldCapacity = oldTable.length;
// 条件成立:已经达到最大容量,无法继续扩容
if (oldCapacity == MAXIMUM_CAPACITY) {
// 提高扩容临界阈值,这样就不会再扩容了
threshold = Integer.MAX_VALUE;
return;
}
// 申请一个新的数组,容量为新的容量
// 如果是 put 单个元素时引起的扩容,newCapacity 等于 2 * oldCapacity,扩大一倍
// 如果是 putAll 多个元素时引起的扩容,newCapacity 等于 2^n * oldCapacity。
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
// 修改扩容阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
transfer 转移函数
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
// 执行 transfer 之前,已经申请了一块新的数组,新的容量就等于新的数组长度
int newCapacity = newTable.length;
// 外层:顺序遍历老数组上的 Entry 引用
for (Entry<K,V> e : table) {
// 从头结点开始依次遍历链表中的所有元素
// e 表示当前正在访问的 Entry,e 相当于“遍历移动指针”
while(null != e) {
// 暂存 e 的 next,防止修改 e.next 引起的遍历指针丢失
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
// 使用“头插法”把 e 从老 Entry 数组转移到新 Entry 数组
// 先修改 e 的 next 指向,指向新 Entry 数组的当前头结点
e.next = newTable[i];
// 修改新 Entry 数组的头结点为 e
newTable[i] = e;
// 此时,移动当前遍历结点为暂存的 next 结点。
// 表示的是老 Entry 数组中的下一个元素,现在已经是新的头结点了
e = next;
}
}
}
createEntry 创建
使用“头插法”向链表中添加新的元素。
void createEntry(int hash, K key, V value, int bucketIndex) {
// 暂存当前的链表头结点,防止老的头结点丢失
Entry<K,V> e = table[bucketIndex];
// new 一个新的 Entry 覆盖头结点,且新的 Entry 头结点的 next 指向老的头结点 e
table[bucketIndex] = new Entry<>(hash, key, value, e);
// HashMap 内部元素数量 + 1
size++;
}
多线程 HashMap 成环问题再现
import java.util.HashMap;
public class ShowProblem {
public static void main(String[] args) {
final HashMap<Integer, Object> hashMap = new HashMap<Integer, Object>(4, 0.5f);
final HashMapWrapper wrapper = new HashMapWrapper(hashMap);
hashMap.put(1, null);
hashMap.put(9, null);
new Thread(new Runnable() {
public void run() {
hashMap.put(16, null);
System.out.println("扩容后容量:" + wrapper.capacity());
System.out.println(wrapper.getKeysOfTable(1));
}
}, "a").start();
new Thread(new Runnable() {
public void run() {
hashMap.put(24, null);
System.out.println("扩容后容量:" + wrapper.capacity());
System.out.println(wrapper.getKeysOfTable(1));
}
}, "b").start();
}
}
预先设置断点
直接运行这段代码,不容易复现此问题,我们需要借助断点。在以下几个位置设置条件断点:
首先,HashMap resize 方法内 581 行和 582 行设置条件断点,条件为 Thread.currentThread().getName().equals("a") || Thread.currentThread().getName().equals("b")。

然后,在 HashMap transfer 方法 594 行设置断点,条件为 Thread.currentThread().getName().equals("a")
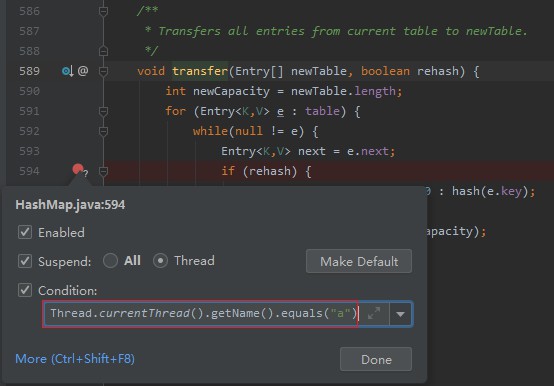
Debug 顺序
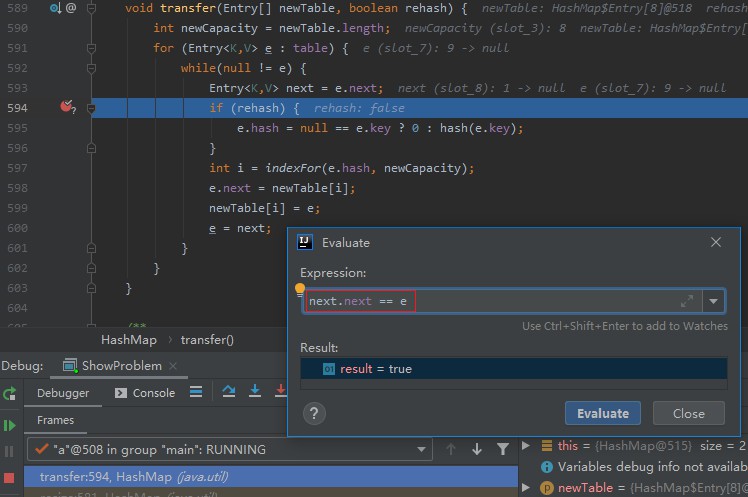
启动 Debug ,线程 a 和线程 b 的代码停留在 transfer 这一行:
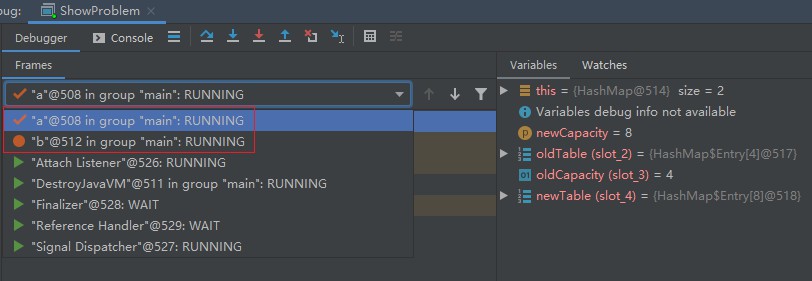
我的这次运行时,红色 √ 是在线程 a,如果你的 红色 √ 在线程 b,那你切换到线程 a。
继续运行线程 a 的代码,让 a 停留在 transfer 方法 next 暂存 e.next 指针之后。
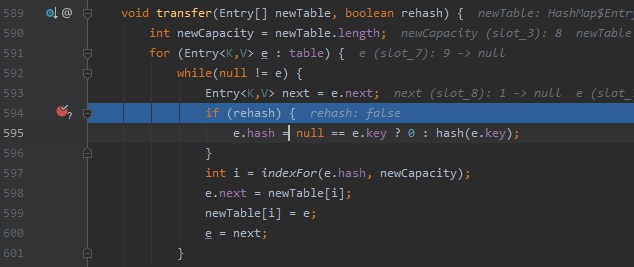
这时候,不要再运行线程 a 的代码了,选中线程 b,并让线程 b 的 transfer 方法执行完。
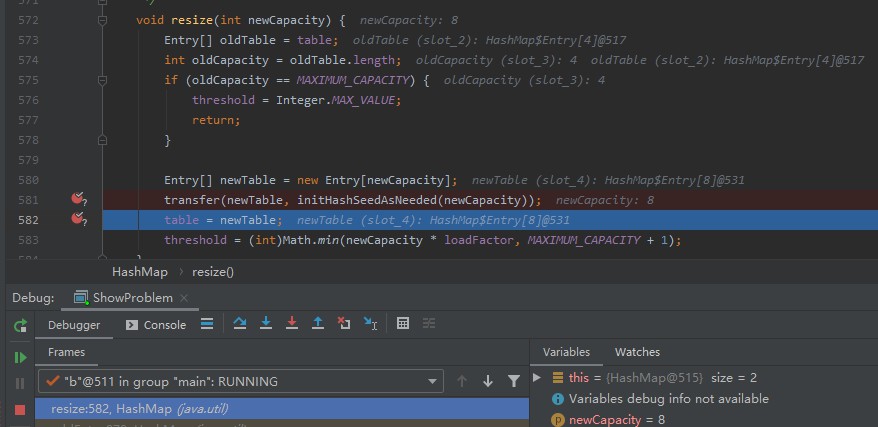
此时切换到线程 a 进行观察,你发现 next.next == e 成立。此时已经成环。
我知道,这样子还是不够直观,并不太容易记住到底怎么成环的,下面我再给出示意图。
成环示意图
为了表现出过程,这次画图我简化一点,Entry 中只显示 key 关键字,next 指针直接用箭头表示。
线程 a 和线程 b 执行过分别申请了新 table 数组,并作为参数传给 transfer 方法。
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
线程 a 执行到 transfer 的 594 行时被我停住了,线程 b 也刚好执行到 transfer 的 594 行,情况如图所示:
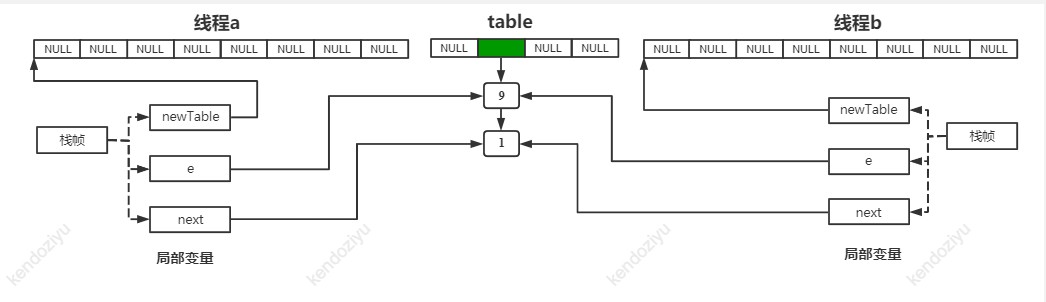
如上图所示,局部变量 e,next 以及方法参数 newTable 都在线程 a 和线程 b 的栈帧中存放着。此时,两个 newTable 都是空的。
线程 b 继续运行,执行完 transfer 方法,停在 HashMap 的 582 行 this.table = newTable; (即使让线程 b 都执行完,结果还是一样的,你可以试一试),此时结果如下:
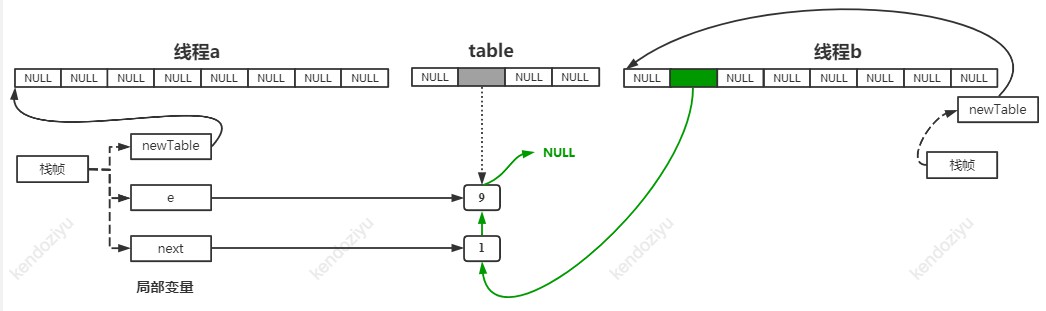
即顺序遍历线程 b 中的 newTable[1] 位置的链表,key的值依次为 1, 9。上图绿色连线就可以表示线程 b 的 newTable。
现在转而执行 线程 a 的代码
// newTable[1]等于 null, 所以 Entry(key=9).next 指向 null
e.next = newTable[i];
// 头结点指向 Entry(key=9)
newTable[i] = e;
继续看下图:

如上图所示,红色连线表示就是线程 a 的 newTable[1] 上的链表。
// 当前线程 a 的栈帧中的 e 被修改为 Entry(key=1)
e = next;
(... 新的一轮循环, 此时 e 指向 Entry(key=1) )
// next 指向 Entry(key=9)
Entry<K,V> next = e.next;
(...省略部分代码)
// newTable[1]等于 Entry(key=9), 所以 Entry(key=1).next 指向 Entry(key=9)
e.next = newTable[i];
// 修改头结点指向 Entry(key=1)
newTable[i] = e;
线程 a 运行到 HashMap 的 600 行 e = next 停住时,此时的情形如下图:
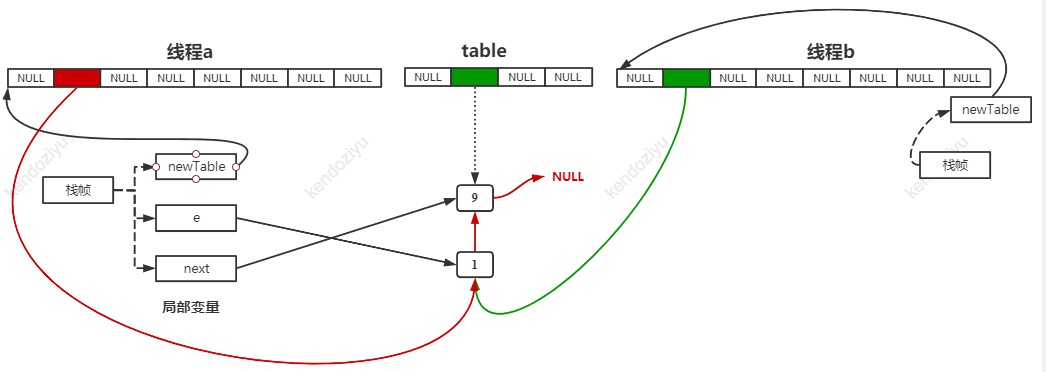
如上图所示,我们发现此时线程 a 的 newTable[1] 的链表已经和线程 b 的 newTable[1] 的链表重合了。而且线程 a 栈帧上的 e 和 next 居然交换位置了!
transfer 方法并不会创建新的 Entry,所以线程 a 和线程 b 是用的同样的 Entry 对象。线程 b 在之前的操作,影响了现在线程 a 的执行。
线程 a 再运行一轮循环:
// 当前线程 a 的栈帧中的 e 被修改为 Entry(key=9)
e = next;
(... 新的一轮循环, 此时 e 指向 Entry(key=9) )
// next 指向 Entry(key=1)
Entry<K,V> next = e.next;
(...省略部分代码)
// newTable[1]等于 Entry(key=1), 所以 Entry(key=9).next 指向 Entry(key=1)
e.next = newTable[i];
// 修改头结点指向 Entry(key=9)
newTable[i] = e;
然后停在 HashMap 600 行,观察此时的状态:
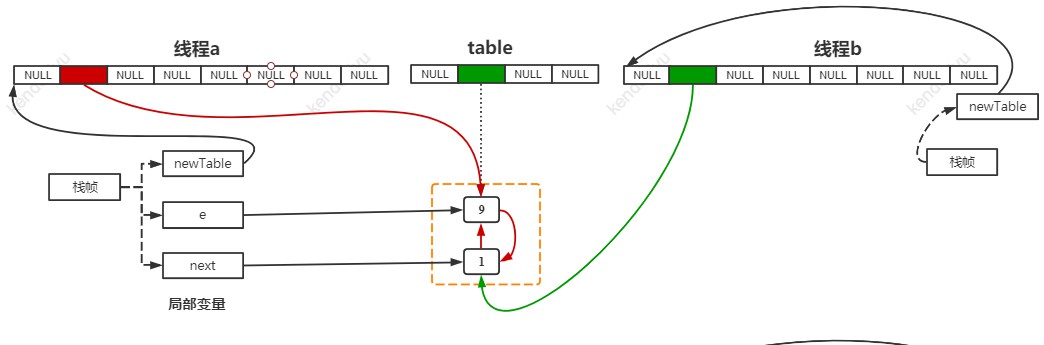
此时就已经成环了。
我们可以再让线程 a 执行一轮循环:
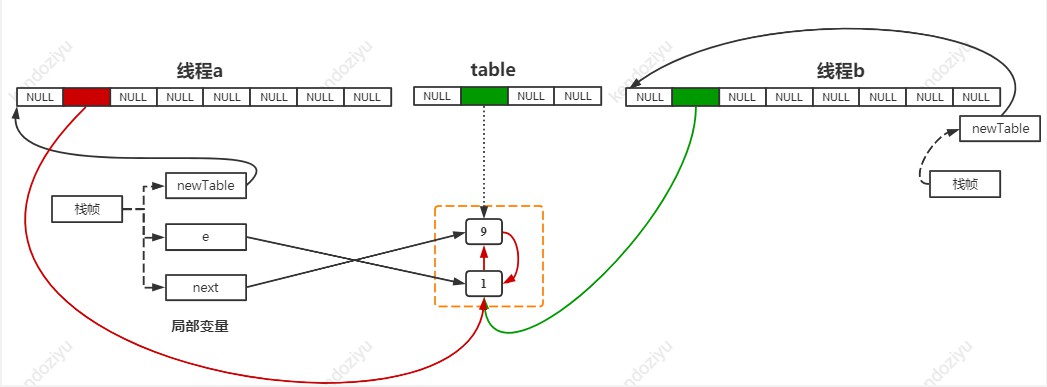
依旧是停在 HashMap 600 行,之后就是最后这两个状态不断切换,不断循环。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号