MySQL 常见错误
导致结果:
连接数过多,导致连接不上数据库,业务无法正常进行
#默认连接数 mysql> show variables like '%max_connection%'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 151 | +-----------------+-------+ 1 row in set (0.00 sec)
解决问题思路:
1、首先先要考虑在我们 MySQL 数据库参数文件里面,对应的 max_connections 这个参数值是不是设置的太小了,导致客户端连接数超过了数据库所承受的最大值。
-
该值默认大小是 151,可以根据实际情况进行调整。
-
对应解决办法:
set global max_connections=500
所以这又反映出了,在新上线一个业务系统的时候,要做好压力测试。保证后期对数据库进行优化调整。
结果:
如果写入大数据时,因为默认的配置太小,插入和更新操作会因为 max_allowed_packet 参数限制,而导致失败。
当一个MySQL客户或mysqld服务器得到一个max_allowed_packet个字节长的包, 它发出一个Packet too large错误并终止连接。
mysql> show variables like 'max_allowed_packet'; +--------------------+---------+ | Variable_name | Value | +--------------------+---------+ | max_allowed_packet | 4194304 | +--------------------+---------+

默认是4M大小
可以使用mysqld的命令行选项设置max_allowed_packet为一个更大的尺寸。 例如, 如果将一个全长的BLOB存入一张表中, 需要用max_allowed_packet=24M选项来启动mysql。
Max_allowed_packet的取值范围是1024B~1GB
当然不要乱设置,根据具体环境要求,设置太大业务
# 具体设置max_allowed_packet大小 mysql> set @@global.max_allowed_packet= #在my.cnf 加入这个 max_allowed_packet= 10M
如果是静态参数还是要重启服务才会生效,动态参数则不用
#默认连接数 mysql> show variables like '%max_connection%'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 151 | +-----------------+-------+ 1 row in set (0.00 sec) #修改连接数为500 mysql> set @@global.max_connections=500; Query OK, 0 rows affected (0.00 sec) #查看是否修改成功 mysql> show variables like '%max_connection%'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 500 | +-----------------+-------+ # 在my.cnf 的[mysqld]下面加上 max_connections=500就可以了,也不用重启服务
忘记了MySQL的root用户的口令 在my.cnf中添加skip-grant-tables=1选项重启mysqld
[root@mysql-150 ~]# mysql -u root -h 127.0.0.1 mysql> flush privileges; mysql> grant all privileges on *.* to root@'localhost' identified by '456789'; mysql> exit # 在my.cnf 将skip-grant-tables=1选项去掉 # 重启mysqld之后就可以用最新的密码登录 [root@mysql-150 ~]# vim /etc/my.cnf [root@mysql-150 ~]# service mysql restart Shutting down MySQL............ SUCCESS! Starting MySQL. SUCCESS! [root@mysql-150 ~]# mysql -u root -p456789 -h 127.0.0.1
# 创建一个用户 mysql> create user keme@'localhost' identified by '123456'; # 给一个只读权限 mysql> grant select on *.* to keme@'localhost'; # 可以从本地登录 [root@mysql-150 ~]# mysql -u keme -p123456 # 把keme@'localhost' 给lock住,不让其使用 mysql> alter user keme@'localhost' account lock; # 在看看能不能从本地登录 [root@mysql-150 ~]# mysql -u keme -p123456 mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 3118 (HY000): Access denied for user 'keme'@'localhost'. Account is locked. # 查看该用户是否锁定 mysql> select host,user,account_locked from mysql.user where user='keme'; +-----------+------+----------------+ | host | user | account_locked | +-----------+------+----------------+ | localhost | keme | Y | +-----------+------+----------------+ Y已锁定 # 然后解锁该keme用户 mysql> alter user keme@'localhost' account unlock; # 再去登录keme用户 [root@mysql-150 ~]# mysql -u keme -p123456
临时添加:
# 首先要确定mysql 的安装位置 shell> export PATH=$PATH:/usr/local/mysql/bin
永久设置:
# 在/etc/profile 中末尾添加 PATH=$PATH:$HOME/bin:/usr/local/mysql/bin export PATH 保存退出后执行: source /etc/bash_profile即可。
模式定义MySQL应支持哪些SQL语法, 以及应执行哪种数据验证检查。 这样可以更容易地在不同的环境中使用MySQL, 并结合其它数据库服务器使用MySQL。
查看当前的sql_mode
mysql> show variables like 'sql_mode'; +---------------+-------------------------------------------------------------------------------------------------------------------------------------------+ | Variable_name | Value | +---------------+-------------------------------------------------------------------------------------------------------------------------------------------+ | sql_mode | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | +---------------+-------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> select @@sql_mode; +-------------------------------------------------------------------------------------------------------------------------------------------+ | @@sql_mode | +-------------------------------------------------------------------------------------------------------------------------------------------+ | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | +-------------------------------------------------------------------------------------------------------------------------------------------+
- ANSI
更改语法和行为, 使其更符合标准SQL。
- STRICT_TRANS_TABLES
- TRADITIONAL
sql mode常用值
- ONLY_FULL_GROUP_BY
但这有个条件:如果查询是主键列或是唯一索引且非空列,分组列根据主键列或者唯一索引且空(null)则sql 分组查询有效
- NO_AUTO_VALUE_ON_ZERO
该值影响自增长列的插入。默认设置下,插入0或NULL代表生成下一个自增长值。如果用户希望插入的值为0,而该列又是自增长的,那么这个选项就有用了。
- STRICT_TRANS_TABLES
为事务存储引擎启用严格模式, 也可能为非事务存储引擎启用严格模式。
严格模式控制MySQL如何处理非法或丢失的输入值。 有几种原因可以使一个值为非法。 例如, 数据类型错 误, 不适合列, 或超出范围。 当新插入的行不包含某列的没有显示定义DEFAULT子句的值,则该值被丢失。 对于事务表, 当启用STRICT_ALL_TABLES或STRICT_TRANS_TABLES模式时, 如果语句中有非法或丢失值, 则会出现错误。 语句被放弃并回滚。
- NO_ZERO_IN_DATE
在严格模式下,不允许日期和月份为零
- NO_ZERO_DATE
设置该值,mysql数据库不允许插入零日期,插入零日期会抛出错误而不是警告。
- ERROR_FOR_DIVISION_BY_ZERO
在INSERT或UPDATE过程中,如果数据被零除,则产生错误而非警告。如果未给出该模式,那么数据被零除时MySQL返回NULL
- NO_AUTO_CREATE_USER
禁止GRANT创建密码为空的用户
- NO_ENGINE_SUBSTITUTION
如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常
- PIPES_AS_CONCAT
将”||”视为字符串的连接操作符而非或运算符,这和Oracle数据库是一样的,也和字符串的拼接函数Concat相类似
举例:
# 创建一个测试表 CREATE TABLE `employee` ( `eid` int(11) NOT NULL, `ename` varchar(64) DEFAULT NULL, `sex` int(11) DEFAULT NULL, PRIMARY KEY (`eid`) ) ENGINE=InnoDB; # 插入几条数据 insert into employee (eid,ename,sex) values (1,'keme',18),(2,'xixi',22),(3,'yj',18),(4,'kk',18),(5,'yy',18),(6,'xx',35); # 设置当前会话的sql_mode为如下 mysql> set @@sql_mode='STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION'; mysql> select eid,ename,count(*) from employee group by ename; +-----+-------+----------+ | eid | ename | count(*) | +-----+-------+----------+ | 1 | keme | 1 | | 4 | kk | 1 | | 2 | xixi | 1 | | 6 | xx | 1 | | 3 | yj | 1 | | 5 | yy | 1 | +-----+-------+----------+ # 重新设置当前的sql_mode 为如下 mysql> set @@sql_mode='ONLY_FULL_GROUP_BY'; mysql> select eid,ename,count(*) from employee group by ename; ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'beta.employee.eid' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by mysql> select eid,ename ,count(*) from employee group by eid; +-----+-------+----------+ | eid | ename | count(*) | +-----+-------+----------+ | 1 | keme | 1 | | 2 | xixi | 1 | | 3 | yj | 1 | | 4 | kk | 1 | | 5 | yy | 1 | | 6 | xx | 1 | +-----+-------+----------+ 6 rows in set (0.00 sec) mysql> set @@sql_mode='STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION'; mysql> insert into employee values(7,'ke','male'); ERROR 1366 (HY000): Incorrect integer value: 'male' for column 'sex' at row 1 mysql> set @@sql_mode='ANSI'; Query OK, 0 rows affected (0.00 sec) mysql> select @@sql_mode; +--------------------------------------------------------------------------------+ | @@sql_mode | +--------------------------------------------------------------------------------+ | REAL_AS_FLOAT,PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,ONLY_FULL_GROUP_BY,ANSI | +--------------------------------------------------------------------------------+ #改成ANSI模式就可以插入成功了,只不过识别成了0 mysql> insert into employee values(7,'ke','male'); Query OK, 1 row affected, 1 warning (0.01 sec) mysql> select * from employee where eid=7; +-----+-------+------+ | eid | ename | sex | +-----+-------+------+ | 7 | ke | 0 | +-----+-------+------+ 1 row in set (0.00 sec) mysql> set @@sql_mode='STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION'; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> select @@sql_mode; +--------------------------------------------+ | @@sql_mode | +--------------------------------------------+ | STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION | +--------------------------------------------+ 1 row in set (0.00 sec) mysql> insert into employee values (8,'ww',17/0); Query OK, 1 row affected (0.00 sec) mysql> select * from employee where eid=8; +-----+-------+------+ | eid | ename | sex | +-----+-------+------+ | 8 | ww | NULL | +-----+-------+------+ mysql> set @@sql_mode='STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION,ERROR_FOR_DIVISION_BY_ZERO'; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> select @@sql_mode; +-----------------------------------------------------------------------+ | @@sql_mode | +-----------------------------------------------------------------------+ | STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION | +-----------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> insert into employee values (9,'ee',18/0); ERROR 1365 (22012): Division by 0 mysql> alter table employee modify ename varchar(5); mysql> set @@sql_mode='STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION'; mysql> insert into employee values (9,'qweradsf',11); ERROR 1406 (22001): Data too long for column 'ename' at row 1 mysql> set @@sql_mode='ANSI'; mysql> insert into employee values (9,'qweradsf',11); mysql> select * from employee where eid=9; +-----+-------+------+ | eid | ename | sex | +-----+-------+------+ | 9 | qwera | 11 | +-----+-------+------+ mysql> set @@sql_mode='TRADITIONAL'; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> select @@sql_mode; TRADITIONAL模式有如下值: |STRICT_TRANS_TABLES,STRICT_ALL_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,TRADITIONAL,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION |
MAX_UPDATES_PER_HOUR:一个用户在一个小时内可以执行修改的次数(仅包含修 改数据库或表的语句)
MAX_CONNECTIONS_PER_HOUR:允许用户每小时连接的次数
MAX_USER_CONNECTIONS:一个用户可以在同一时间连MySQL实例的数量
通过执行create user/alter user设置/修改用户的资源限制
# 创建一个用户并设置其资源限制 CREATE USER 'keme1'@'localhost' IDENTIFIED BY '123456' WITH MAX_QUERIES_PER_HOUR 20 MAX_UPDATES_PER_HOUR 10 MAX_CONNECTIONS_PER_HOUR 5 MAX_USER_CONNECTIONS 2; #keme1 这个用户 一个小时可以查询20次, 修改10次,一个小时可以连接5次,同一时刻只允许两个用户 #取消某项资源限制既是把原先的值修改成0 mysql> alter user 'keme1'@'localhost' WITH MAX_CONNECTIONS_PER_HOUR 0; # 当针对某个用户的max_user_connections非0时, 则忽略全局系统参数max_user_connections, 反之则全局系统参数生效
在确保主从数据一致性的前提下,可以在从库进行错误跳过。
像从库如果不提供什么服务的话可以在从库中开启 read_only 参数,禁止在从库进行写入操作,还有用户必须没有super 权限,设置read_only才会生效。
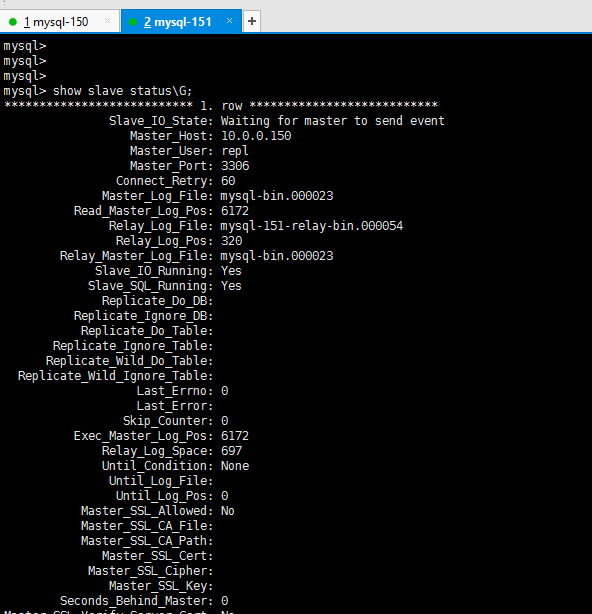
这是正常的状态
10.0.0.150 是主
10.0.0.151 是从
先模拟故障
# 这是本次的表结构 mysql> show create table students; | students | CREATE TABLE `students` ( `sid` int(11) NOT NULL, `sname` varchar(20) DEFAULT NULL, `sex` int(11) DEFAULT NULL, PRIMARY KEY (`sid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 #主库执行,是个空表 mysql> select * from students; Empty set (0.00 sec) #在从库 ,给students 加1条数据: mysql> insert into students values (1,'keme',0); mysql> show slave status\G; ... Slave_IO_Running: Yes Slave_SQL_Running: Yes ... 看主从状态是正常的 # 从库查看students 数据 mysql> select * from students; +-----+-------+------+ | sid | sname | sex | +-----+-------+------+ | 1 | keme | 0 | +-----+-------+------+ # 在主库查看students 表 mysql> select * from students; Empty set (0.00 sec) # 插入相同主键的值 mysql> insert into students values (1,'keme',1); # 查看students表 mysql> select * from students; +-----+-------+------+ | sid | sname | sex | +-----+-------+------+ | 1 | keme | 1 | +-----+-------+------+ # 查看从库状态 mysql> show slave status\G; ... Slave_IO_Running: Yes Slave_SQL_Running: No Last_SQL_Error: Could not execute Write_rows event on table beta.students; Duplicate entry '1' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysql-bin.000023, end_log_pos 11789 ... # 主从状态不一致了,造成的原因是主键冲突
解决办法
# 停止从库 mysql> stop slave; # 在从库删除主键冲突的那条语句, 把主库执行的那条语句在从库执行 mysql> delete from students where sid=1; mysql> insert into students values (1,'keme',1); # 同步跳过临时错误 mysql> set global sql_slave_skip_counter = 1; mysql> start slave; mysql> show slave status\G; ... Slave_IO_Running: Yes Slave_SQL_Running: Yes ... # 主库再次插入数据,看看从库是不是能够同步 mysql> insert into students values (2,'keme',1); # 从库查看 mysql> select * from students; +-----+-------+------+ | sid | sname | sex | +-----+-------+------+ | 1 | keme | 1 | | 2 | keme | 1 | +-----+-------+------+ 2 rows in set (0.00 sec) # OK,同步成功了, 一般主从错误也就解决了
首先主从问题不一致了,你的监控预警机制了,给你发短信或者钉钉,这时候你应该尽快去修复从库,比如就像上面跳过临时同步错误,暂时让其恢复正常同步。
现在修改我的主从模式为GTID,这是我的测试环境随便改,
enforce_gtid_consitency=on :使用GTID模式复制时,需要开启此参数,用来保证GTID的一致性。
log-bin=on :Msql 做主从必须开启binlog
log-slave-updates=1 :觉得slave 从master 接收到的更新且执行完之后,执行的binlog是否记录到slave的binlog中,建议开启
binlog_format=row :强烈建议binlog_format使用row格式 在mysql 5.7.6 版本以后默认就是row
skip-slave-start=1 :当slave 数据库启动的时候,slave 不会自动开启复制
主库操作,在[mysqld] 加一下参数,我这个做过主从, 只加一部分参数
# my.cnf 中内容 [mysqld] gtid-mode=on enforce-gtid-consistency=on log-slave-updates=1
从库操作
# my.cnf 中内容 [mysqld] gtid-mode=on enforce-gtid-consistency=on log-slave-updates=1 skip-slave-start=1
重启主从数据库
在从库 操作重新设置主从库的复制关系
mysql> CHANGE MASTER TO MASTER_HOST = '10.0.0.150', MASTER_PORT = 3306, MASTER_USER = 'repl', MASTER_PASSWORD = '123456', MASTER_AUTO_POSITION = 1; mysql> start slave; #查看主从状态 mysql> show slave status\G; ... Slave_IO_Running: Yes Slave_SQL_Running: Yes ...
如果是在GTID模式下出现复制报错, 则使用SQL_SLAVE_SKIP_COUNTER语句会报错
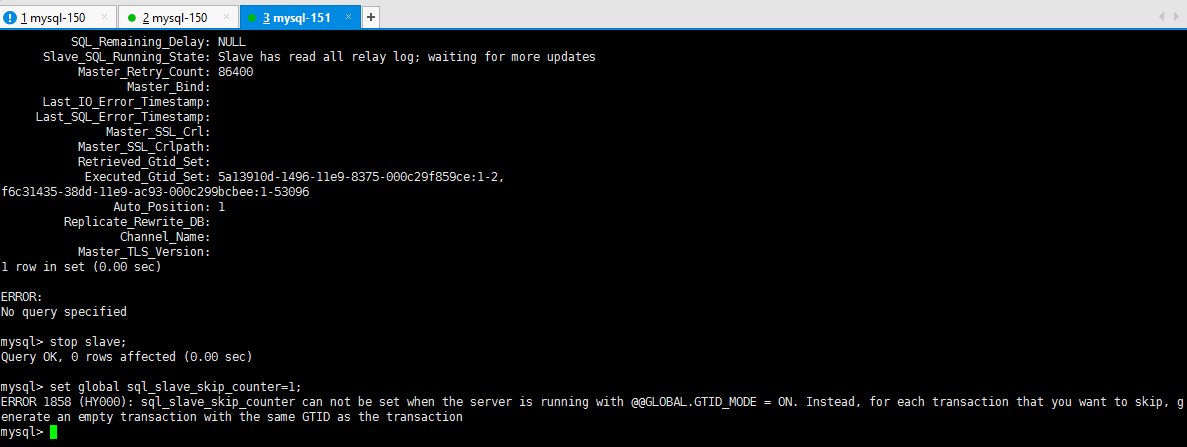
在GTID 模式的复制情况下,如果slave 发生错误,则可以通过跳过该事务的方式恢复主从复制。
现在人为制造slave错误
# 在从库的sutdents 表插入一条数据 mysql> select * from students; +-----+-------+------+ | sid | sname | sex | +-----+-------+------+ | 1 | keme | 1 | | 2 | keme | 1 | +-----+-------+------+ mysql> insert into students values (3,'keme',0); # 在查看从库的数据 mysql> select * from students; +-----+-------+------+ | sid | sname | sex | +-----+-------+------+ | 1 | keme | 1 | | 2 | keme | 1 | | 3 | keme | 0 | +-----+-------+------+ # 主库也插入主键为3这条数据,引发主从同步错误 mysql> insert into students values (3,'keme',1);
主从报错了:
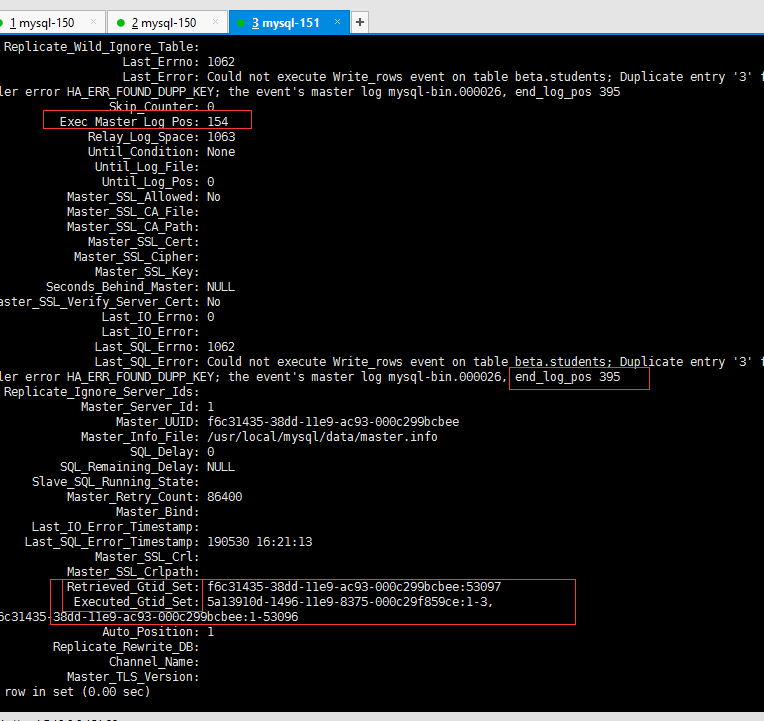
开始位置(Exec_Master_Log_Pos)是154 ,结束位置是(end_log_pos ) 395,可以去主库分析下binlog ,看一下发生冲突的事务是哪个。
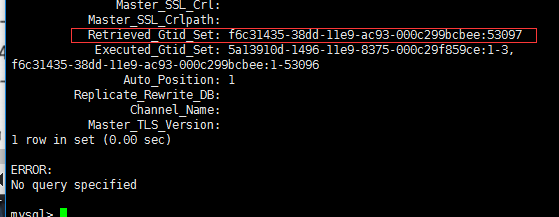
可以看到接收并且执行了GTID事件 是
从库执行了这些 5a13910d-1496-11e9-8375-000c29f859ce:1-3, f6c31435-38dd-11e9-ac93-000c299bcbee:1-53096 收到却没执行的事务号: Retrieved_Gtid_Set: f6c31435-38dd-11e9-ac93-000c299bcbee:53097
mysql> select * from students where sid=3; +-----+-------+------+ | sid | sname | sex | +-----+-------+------+ | 3 | keme | 0 | +-----+-------+------+
基于GTID模式的复制,跳过一个事务,需要利用一个空事务来完成。
mysql> stop slave; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> set GTID_NEXT='f6c31435-38dd-11e9-ac93-000c299bcbee:53097'; Query OK, 0 rows affected (0.00 sec) mysql> begin;commit; Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) mysql> set GTID_NEXT='AUTOMATIC'; Query OK, 0 rows affected (0.00 sec) mysql> start slave; Query OK, 0 rows affected (0.00 sec)
查看slave 状态

哪主从库数据是否一致,就看3那条
# 主库数据 mysql> select * from students where sid=3; +-----+-------+------+ | sid | sname | sex | +-----+-------+------+ | 3 | keme | 1 | +-----+-------+------+ #从库数据 mysql> select * from students where sid=3; +-----+-------+------+ | sid | sname | sex | +-----+-------+------+ | 3 | keme | 0 | +-----+-------+------+
1 手动修改或者插入
2 用pt用具 来修复或者检查不一致数据
由于我这是我的本地环境,我只手动修改数据,再看主从状态
mysql> update students set sex=1 where sid=3; Query OK, 1 row affected (0.03 sec) Rows matched: 1 Changed: 1 Warnings: 0
注:不止是要主从解决错误,还要主从数据的一致性
如果是生产的核心库主从不一致,一定要查明原因,不然老是 dba 或者运维 背锅
还有如果主从不一致性实在是太多太多不一致了,就重做数据库吧
如果检查的数据某几张表不一致的情况下,可以把这几张道出来,恢复到从库
如何修改了系统编码了:
# centos 6.x 版本是/etc/sysconfig/i18n 修改这个文件 shell> vim /etc/sysconfig/i18n # 这一行改为utf8 LANG=en_US.UTF-8 # 修改完,不要重启,立即生效如下 shell> source /etc/sysconfig/i18n # centos 7.x 版本是/etc/locale.conf 这个文件 [root@mysql-150 ~]# vim /etc/locale.conf LANG="en_US.UTF-8" #立即生效 [root@mysql-150 ~]# source /etc/locale.conf
- 数据库层面:
在参数文件中的[mysqld] 下,加入相应utf8字符集
# 注意数据库的系统版本 5.6.x 和 5.7.x设置字符集参数不一样,8.x和5.7.x设置是一样的 #查看当前数据库的字符集参数,查看当前字符集参数 mysql> show variables like '%character%'; # 查看数据库支持的字符编码,和编码的排序规则 mysql> show character set; # 修改sutdents表中sname 字段的字符编码 mysql> alter table students modify sname varchar(66) character set gbk; Query OK, 3 rows affected (0.06 sec) Records: 3 Duplicates: 0 Warnings: 0 #看看表结构 mysql> show create table students; ... | students | CREATE TABLE `students` ( `sid` int(11) NOT NULL, `sname` varchar(66) CHARACTER SET gbk DEFAULT NULL, `sex` int(11) DEFAULT NULL, PRIMARY KEY (`sid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 | ... # 查看连接级字符集和排序规则 mysql> show variables like '%collation%'; +----------------------+-----------------+ | Variable_name | Value | +----------------------+-----------------+ | collation_connection | utf8_general_ci | | collation_database | utf8_general_ci | | collation_server | utf8_general_ci | +----------------------+-----------------+
从上面示例可以得出:
-
列级别字符集
-
表级别字符集
-
库级别字符集
-
mysql 实例字符集
vim /etc/my.cnf [mysqld] init-connect='SET NAMES utf8' character-set-server=utf8 然后去数据库操作: mysql> set @@global.character_set_server=utf8; Query OK, 0 rows affected (0.00 sec) mysql> set @@global.init_connect='SET NAMES utf8'; Query OK, 0 rows affected (0.00 sec) # 注 用户操作的时候看看有没有super权限,对super用户权限 set names 不生效
有人说,修改完还是乱码, 这时候就乱码是哪个库的字符集,哪个表的字符集,哪个字段的字符集,还有操作系统字符集,程序连接的字符集,这些都的查看。
比如:
# 举例init_connect mysql> SET @@GLOBAL.init_connect='SET AUTOCOMMIT=0;set names utf8'; shell> vim my.cnf [mysqld] init_connect='SET AUTOCOMMIT=0;set names utf8'
-
每个数据库客户端连接都有自己的字符集和排序规则属性,
客户端发送的语句的字符集是由character_set_client决定,
而与服务端交互时会根据character_set_connection和collation_connection两个参数将接收到的语句转化。当涉及到显示字符串的比较时,由collation_connection参数决定,
-
character_set_result参数决定了语句的执行结果以什么字符集返回给客户端
-
客户端可以很方便的调整字符集和排序规则,比如使用SET NAMES 'charset_name' [COLLATE 'collation_name']表明后续的语句都以该字符集格式传送给服务端,而执行结果也以此字符集格式返回。
set names 字符集
set names charset_name 语句相当于执行了以下三行语句: SET character_set_client = charset_name; SET character_set_results = charset_name; SET character_set_connection = charset_name;
SET character_set_client = charset_name; SET character_set_results = charset_name; SET character_set_connection = @@character_set_database;
数据库从: 全局数据库server字符集——>数据库字符集——> 表字符集——> 列字符集
解决思路:
首先我们要先查看数据库的 error log。然后判断是表损坏,还是权限问题。还有可能磁盘空间不足导致的不能正常访问表,操作系统的限制也要关注下,相关应用限制也要关注下;
#ulimit -n 查看系统的最大打开文件数 [root@mysql-150 ~]# ulimit -n 65535
查看数据库的打开文件数
mysql> show variables like 'open_files_limit'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | open_files_limit | 5000 | +------------------+-------+ # 根据业务实际情况修改打开文件数一般足够用了,低版本的打开文件数,可能有点小, 注意一下
哪就是其他的问题了,可能是表的权限,也可能是表出问题,根据错误日志,具体分析
处理方法
-
repair table tablename -
chown mysql.mysql 权限 目录 -
清理磁盘中的垃圾数据
-
-
mysql 参数的问题,是不是参数配置的不合理,一直不释放连接;
-
mysql 语句的问题,数据库查询不够优化,过度耗时。
-
大并发情况问题,导致 sleep 情况过多;
很多人都是重启大法,重启大法确实好, 能够释放,生产重启对业务有影响的,不能随便重启的
shell脚本+cron计划任务,来kill sleep 线程,这个不靠谱啊, 你不知道 sleep 线程,里面是不是还有事务还在执行没有提交,也是sleep 状态,这个kill 操作有点莽夫,对生产数据数据库还是要理智啊。
我临时解决的办法:
-
-
修改 mysql 参数问题 ,修改
wait_timeout和interactive_timeout默认都是28800秒有,也就是8个小时以后才释放空链接。
例子:

不同用户登录到数据库,wait_timeout和interactive_timeout都是28800秒
修改参数,我生产环境设置的是半个小时,也就是1800秒
mysql> set global wait_timeout=1800; mysql> set global interactive_timeout=1800; shell> vim my.cnf [mysqld] wait_timeout=1800 interactive_timeout=1800
#开启两个会话窗口 mysql> # 重新登录了会话,wait_timeout和interactive会生效 mysql> show variables like 'wait_timeout'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | wait_timeout | 1800 | +---------------+-------+ 1 row in set (0.00 sec) mysql> show variables like 'interactive_timeout'; +---------------------+-------+ | Variable_name | Value | +---------------------+-------+ | interactive_timeout | 1800 | +---------------------+-------+ 1 row in set (0.00 sec) #session2 mysql> #这个是其他用户连接的mysql,这个会话一直没有断开,参数还是28800 mysql> show variables like 'wait_timeout'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | wait_timeout | 28800 | +---------------+-------+ 1 row in set (0.01 sec) mysql> show variables like 'interactive_timeout'; +---------------------+-------+ | Variable_name | Value | +---------------------+-------+ | interactive_timeout | 28800 | +---------------------+-------+ 1 row in set (0.00 sec)

这时候就要知道 造成 sleep 线程过多的原因来解决:
-
程序执行完毕,应该显式调用mysql_close
-
-
能逐步分析系统的SQL查询,找到查询过慢的SQL优化
-
合理设置mysql参数值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号