WordCoun优化
一,github地址: https://github.com/kekeing
二,项目PSP表格
PSP2.1表格
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
||
|
· Estimate |
· 估计这个任务需要多少时间 |
445 | 425 |
|
Development |
开发 |
||
|
· Analysis |
· 需求分析 (包括学习新技术) |
30 | 30 |
|
· Design Spec |
· 生成设计文档 |
60 | 55 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
40 | 20 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 | 25 |
|
· Design |
· 具体设计 |
25 | 30 |
|
· Coding |
· 具体编码 |
45 | 55 |
|
· Code Review |
· 代码复审 |
25 | 30 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
45 | 55 |
|
Reporting |
报告 |
30 | 30 |
|
· Test Report |
· 测试报告 |
45 | 35 |
|
· Size Measurement |
· 计算工作量 |
35 | 25 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
35 | 35 |
|
合计 |
445 | 425 |
三,个人接口及其实现
void wordcount(FILE *file, int word) { //定义一个字符型的数据进行文件的字符的储存 char charc; //读取文件中的第一个字符,同时文件指针指向下一个字符的位置 charc = fgetc(file); //在计数菌正式开始工作之前需要做一些准备工作 //比如说需要排除开头就是空格的情况 if (charc == ' ') { while (charc == ' ') charc = fgetc(file);//假如第一个文件字符就是空格,那么就需要跳过,直至读取第一个不是空格的字符为止 } //当前的文件指针 while (charc != EOF) { //将当前的字符加入容器之中 if (charc != ' '&&charc != 10) { v_char.push_back(charc); //如果文件的下一个字符不是空格,就继续循环,否则就要加1 charc = fgetc(file); } if (charc != ' '&&charc != 10) { v_char.push_back(charc); charc = fgetc(file); continue; } else {//生成一个结构体,然后将这个结构体加入容器之中 //首先需要将容器中的字符生成一个字符串 //在生成结构体之前,首先检查是否该字符已经存在,如果存在只是简单的将次数+1 //遍历这个容器,然后生成一个字符串 char *current_char = NULL; if (current_char != NULL) current_char = NULL; current_char = new char[v_char.size()]; for (int i = 0; i<v_char.size(); i++) { //开辟一个动态的字符数组 current_char[i] = v_char[i]; } //如果vector内的元素个数不为0,就需要清空元素个数 if (v_char.size() != 0) v_char.clear(); //于已有的一个类型,就直接加1,否则就创建一个新的节点,加入这个已有的 //先查看是否存在元素,不存在就不需要遍历了 if (file_info_cahr.size() == 0) { //直接创建一个结构体就ok; file_info_ file_; file_.name = new char[sizeof(current_char)]; //将字符数组的内容拷贝到结构体中 strcpy(file_.name, current_char); //将出现次数设置为1; file_.num_appear = 1; //然后加入结构体数组 file_info_cahr.push_back(file_); } else { //结构体中的元素不为空,需要遍历 //设置一个变量,如果有元素则为真 bool exist = false; for (int j = 0; j<file_info_cahr.size(); j++) {//如果不相等,就将变量设置为false if (strcmp(file_info_cahr[j].name, current_char) != 0) exist = false; else { //相等需要将对应结构体的出现次数加1,同时跳出循环 file_info_cahr[j].num_appear++; exist = true; break; } } //循环结束之后,假设没有遇见相等的就需要重新创建一个结构体,加入结构体数组 if (exist == false) { file_info_ file__; file__.name = new char[sizeof(current_char)]; strcpy(file__.name, current_char); //将出现次数设置为1; file__.num_appear = 1; file_info_cahr.push_back(file__); } } }//之后还需要将这些信息记录在结构体数组之中 charc = fgetc(file); }
四,测试用例设计:
我负责的是对单词的统计和排序,所以测试要考虑多种情况,实际测试了20个测试用例,不过这里我仅给出一部分
我输出到控制台,输出到文件有小组其他成员完成,一个一个进行测试,只需修改fopen文件的名字
int main(int argc, char** argcs)
{
//定义文件指针
FILE *file = NULL;
///定义一个字符型的数据进行文件的字符的储存
char charc;
//先检查命令行是否有输入
/*if(argc!=2)
{
printf("Please input a correct file name\n");
return 0;
}
//然后检查文件的文件名的正确性
if(check!=1)
{
printf("This is an incorrect file\n");
return 0;
}
*/
if ((file = fopen("test.txt", "r")) == NULL)
{
printf("This is a broken file\n");
return 0;
}
//按照字节读取数据,然后再来对文件进行操作
//fgetc 这个函数每次从当前文件指针读取一个字符,然后将文件字符指针加1
//循环读取数据,在过程中进行计数,和排序
//调用计数菌
int word = 0;
wordcount(file, word);
//调用排序菌
order(file_info_cahr);
//结束这个进程
return 0;
}
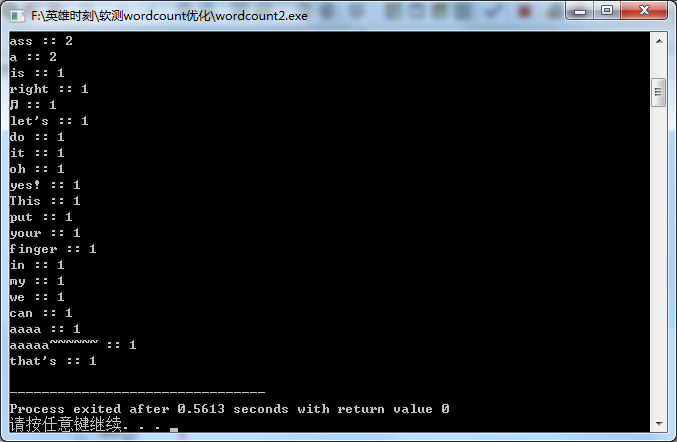
五,测试用力运行截图:
这里我只截取了其中一个,其他太多了
六,小组贡献分:
0.25


 浙公网安备 33010602011771号
浙公网安备 33010602011771号