pandas的基本使用
import pandas as pd
import numpy as np
Series
创建Series
使用数组创建
可以使用Py原生的list类型,np的数组类型
a = pd.Series(np.arange(2,10,2))
print(a)
0 2
1 4
2 6
3 8
dtype: int32
如果要设定索引,则
a = pd.Series(np.arange(2,10,2),[f'第{i+1}个' for i in range(4)])
print(a)
第1个 2
第2个 4
第3个 6
第4个 8
dtype: int32
使用字典创建
dict_1 = {
'name':"小明",
'age':20,
'sex':"male"
}
b = pd.Series(dict_1)
print(b)
name 小明
age 20
sex male
dtype: object
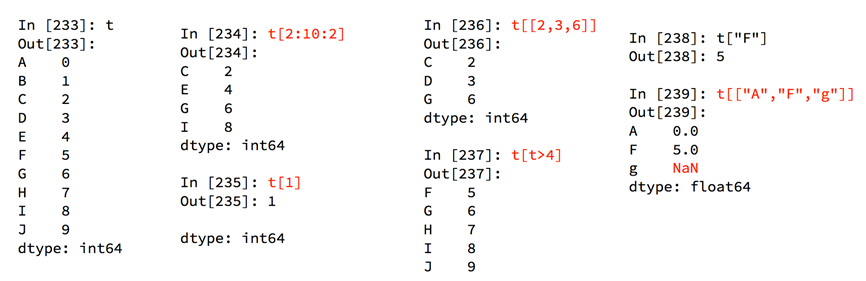
索引和切片

DataFrame
创建DataFrame
使用数组(列表)创建
a =pd.DataFrame(np.arange(12).reshape(3,4))
print(a)
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1

b =pd.DataFrame(np.arange(12).reshape(3,4),index=['a','b','c'],columns=['w','x','y','z'])
print(b)
不一定是二位数组,一维的字典列表也可以
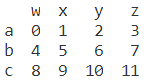
dict_c1 ={
'name' : 'person1',
'age': 20
}
dict_c2 = {
'name' : 'person2',
'age': 21
}
dict_c3 = {
'name' : 'person3',
'age': 22
}
list_c = [dict_c1,dict_c2,dict_c3]
c = pd.DataFrame(list_c)
print(c)

使用字典创建
dict_d = {
'name' : ['person1','person2','person3'],
'age': [19,20,21]
}
d = pd.DataFrame(dict_d)
print(d)
DataFrame的属性

e =pd.DataFrame(np.arange(81).reshape(9,9),index=list("abcdefghi"))
print(e)
print(e.shape)
(9, 9)
print(e.dtypes)
0 int32
1 int32
2 int32
3 int32
4 int32
5 int32
6 int32
7 int32
8 int32
dtype: object
print(e.ndim)
2
print(e.index)
Index(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i'], dtype='object')
print(e.columns)
RangeIndex(start=0, stop=9, step=1)
print(e.values)

print(e.head())
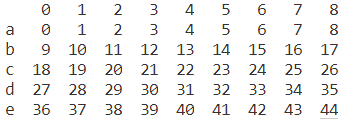
print(e.tail(3))

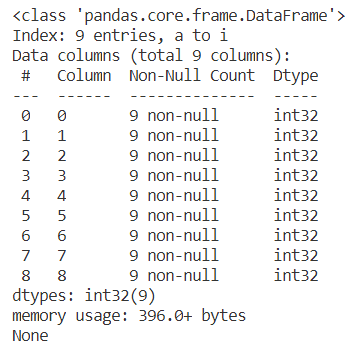
print(e.info())
print(e.describe())

取行和列
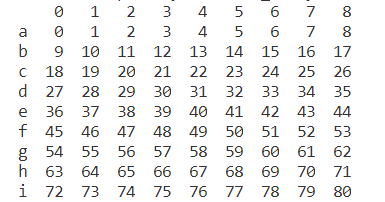
e =pd.DataFrame(np.arange(81).reshape(9,9),index=list('abcdefghi'),columns=list('ABCDEFGHI'))
print(e)
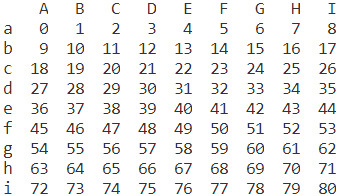
使用索引和切片
索引取列,切片取行
print(e['A'])
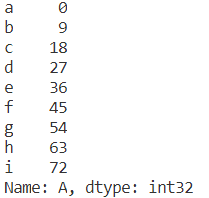
print(e[0:2])

print(e[:]['A'])

使用loc和iloc
df.loc通过标签索引数据df.iloc通过位置获取数据
loc
print(e.loc['a'])

print(e.loc[:,'A'])
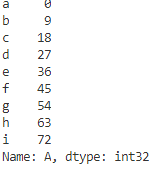
print(e.loc['a':'c',['A','C','D']])

iloc
print(e.iloc[0])

print(e.iloc[:,0])

print(e.iloc[[1,3,4],0:2])
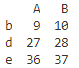
布尔索引
只能够选行
e =pd.DataFrame(np.arange(81).reshape(9,9),index=list('abcdefghi'),columns=list('ABCDEFGHI'))
print(e)
print(e[e.loc[:,'F']>41])

如果有多个调剂需要对每个条件加上括号,然后之间用&和|来表示且和或
print(e[(e.loc[:,'F']>41)&(e.loc[:,'F']<68)])

缺失数据处理
数据缺失处理主要是针对两种情况
- 数据是nan
- 数据是0(不一定要处理,一般使用
t[t==0]=想要设置的值(其中t为DataFrame对象)来处理)
可以设置为np.nan,因为在计算平均值、中位数等情况的时候np.nan是不参与运算的
先创建带有nan的元素的DataFrame
f = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list('ABCD'))
f.iloc[1:,:2] = np.nan
print(f)

判断是否为nan
pd.isnull()和pd.notnull()
print(pd.isnull(f))
print(pd.notnull(f))

处理方法1:删除对应的行或者列
f.dropna(
axis=0, # 0: 对行进行操作; 1: 对列进行操作
how='any', # 'any': 只要存在 NaN 就 drop 掉; 'all': 必须全部是 NaN 才 drop
inplace = False #如果是True则对f进行替换,否则就是生成一个新的DataFrame对象
)

处理方法2:对nan的位置填充数据
使用f.fillna()填充数据
接受的参数为要替换的值可以,设置为f.mean()、f.median()、0等等
h = f.fillna(0)

数据合并
join

merge

 浙公网安备 33010602011771号
浙公网安备 33010602011771号