Web Scraping using Python Scrapy_BS4 - using Scrapy and Python(2)
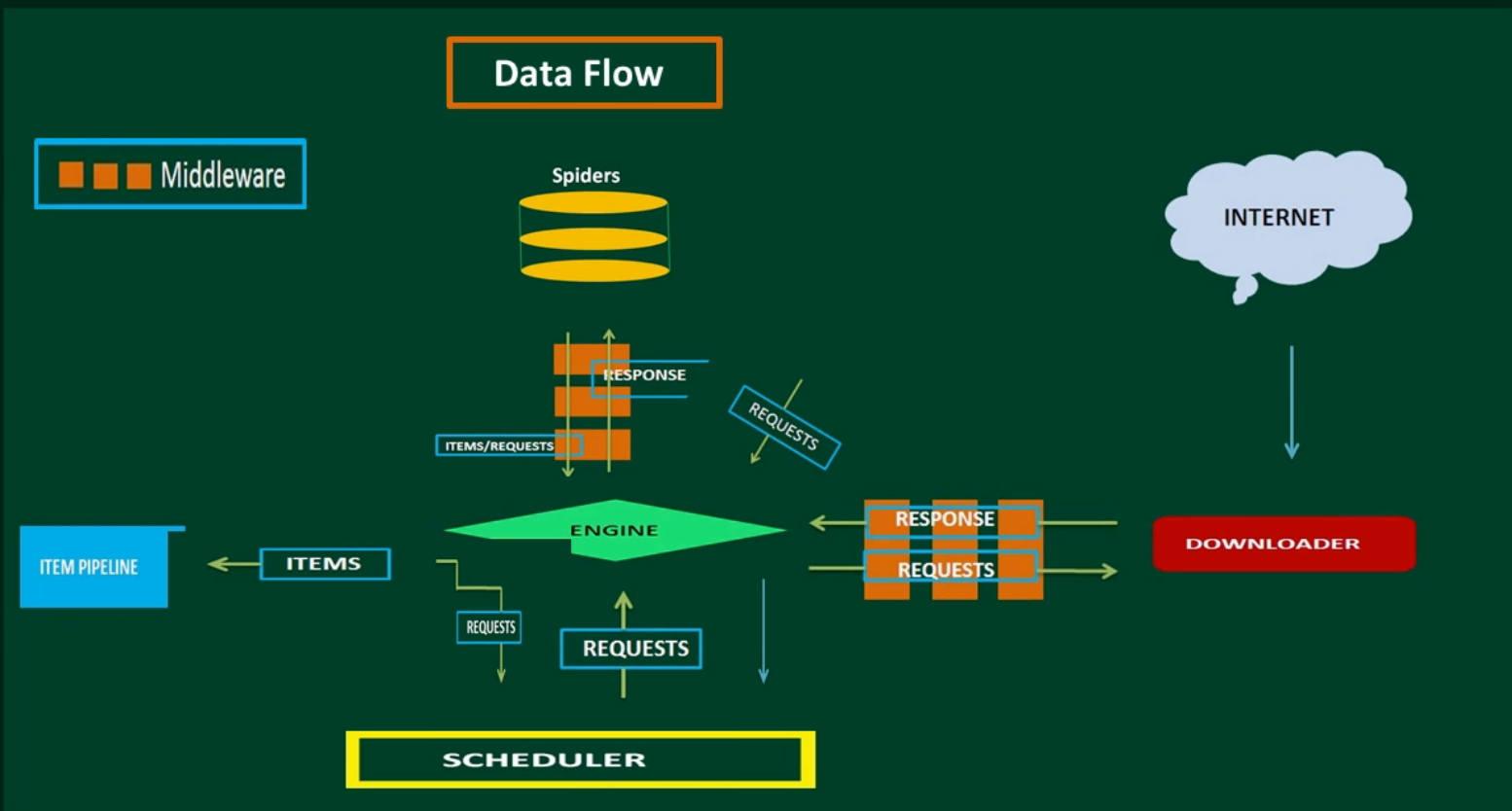
Scrapy Architecture
Creating a Spider.
Spiders are classes that you define that Scrapy uses to scrape(extract) information from a website(s).
import scrapy class QuoteSpider(scrapy.Spider): name = "quote" start_urls = [ 'https://bluelimelearning.github.io/my-fav-quotes/' ] def parse(self, response): for quote in response.css('div.quotes'): yield{ 'quote':quote.css('p.aquote::text').extract(), 'author':quote.css('p.author::text').extract_first(), }

Running your spider and saving scrapped data.
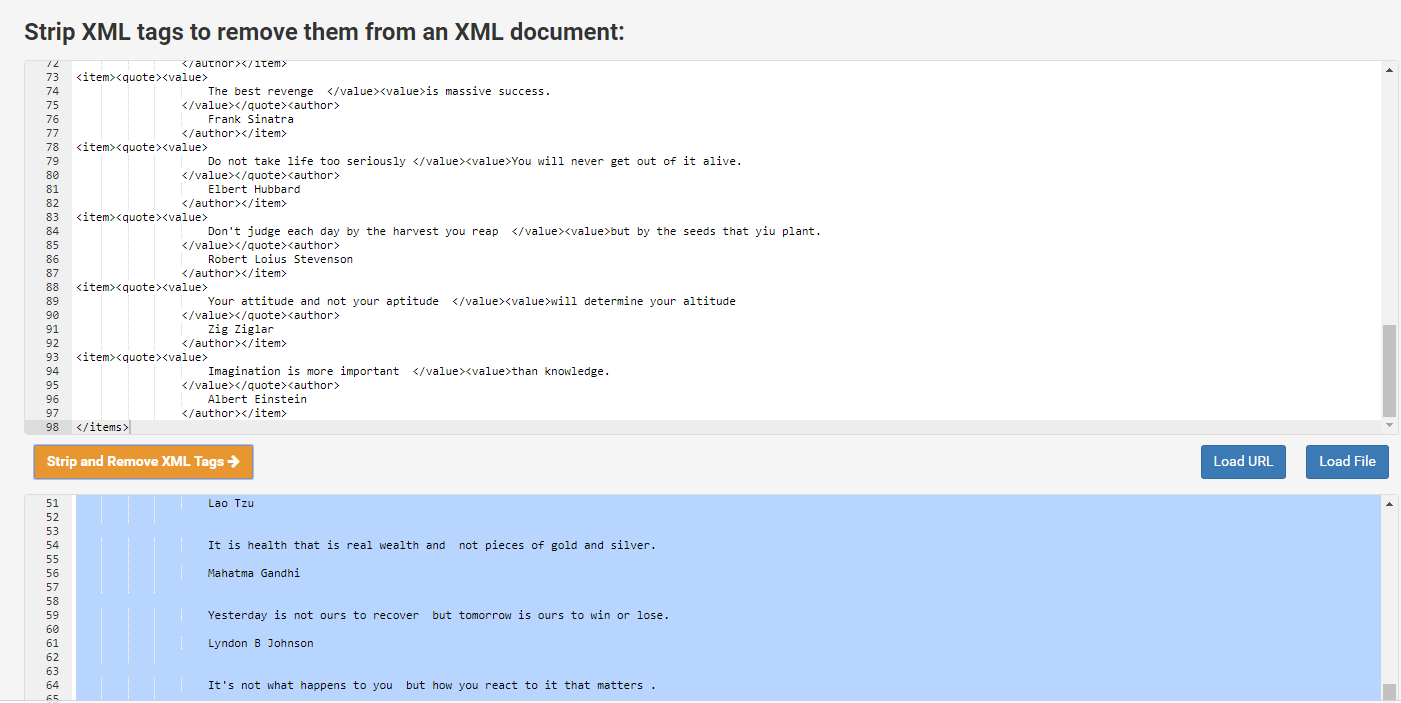
scrapy runspider quotes_spiders.py -o quotes.xml


https://www.cleancss.com/strip-xml/
Scraping data with Scrapy Shell
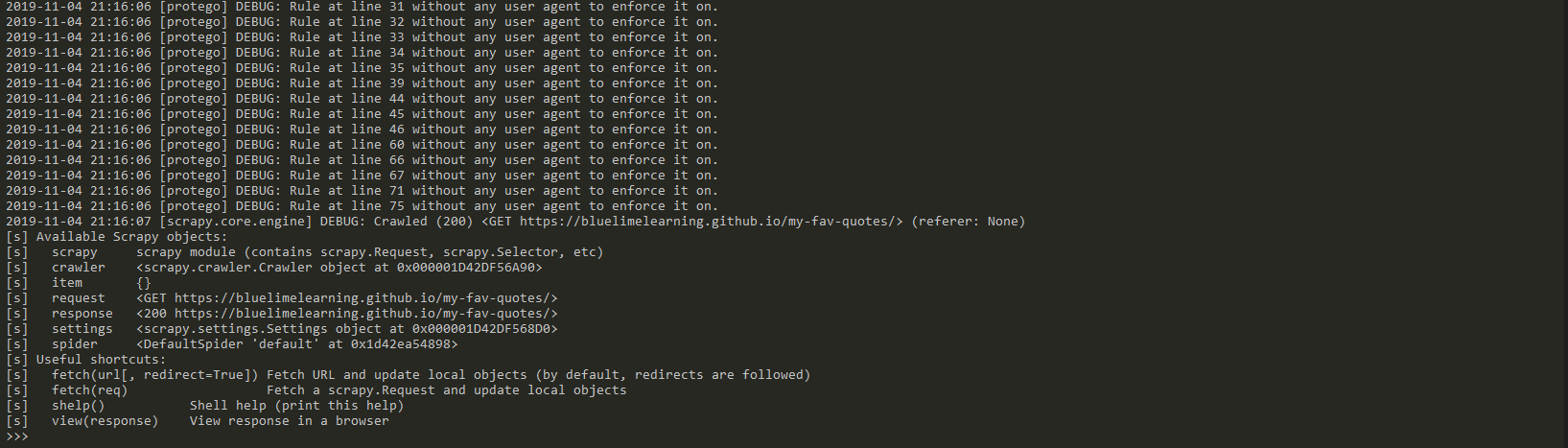
scrapy shell "https://bluelimelearning.github.io/my-fav-quotes/"

response.css('title')

response.css('title::text').extract()

response.css('h1::text').extract()

quote = response.css("div.quotes")[0] aquote = quote.css("p.aquote::text").extract() aquote

相信未来 - 该面对的绝不逃避,该执著的永不怨悔,该舍弃的不再留念,该珍惜的好好把握。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号