CREST——Convolutional Residual Learning for Visual Tracking
CREST
在目标目标跟踪领域,目前最常用大多以相关滤波为主。CREST作者认为现有的相关滤波方法将特征提取与滤波器更新分离开,无法进行端到端训练。而作者则提出了使用一层CNN网络来模拟相关滤波操作,并将特征提取、模型训练等集成在一起,可以进行端到端训练。同时为了避免模型退化,作者采用了残差思想对网络进行了部分优化。
作者认为相关滤波主要有两个缺点:
1)相关滤波的将特征提取与跟踪器训练等隔离开,无法进行端到端的训练;
2)大多数相关滤波进行更新的时候都采用线性插值,这种带有经验性的插值方法不好,可能会使得模型更新后的跟踪器将带有噪声,导致模型漂移。
为了解决上述缺点,作者采用的方法:
1)使用一层卷积网络来代替相关滤波操作,在此处使用卷积网络计算空域相关性去替代频域上面的相关滤波操作;
2)使用残差思想去优化更新过程,使之能更好捕捉目标外观变化等情况。
作者创新点主要有三个:
1)将相关滤波操作用一层CNN进行替代,这样做使得特征提取、生成相应图等集成在一起,可以进行端到端训练;
2)将残差思想应用到tracking中,目的是捕捉时空上的目标外观变化;
3)CREST取得了 state-of-the-art 的效果。
CREST网络结构
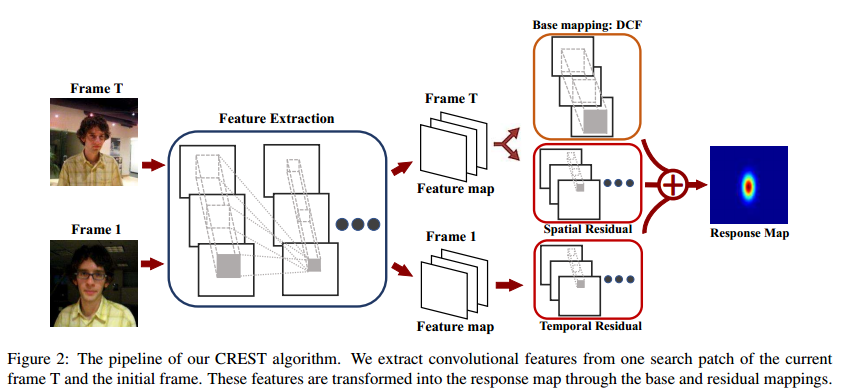
CREST流程如下图所示,首先其特征提取网络采用VGGNET,而用于跟踪网络可以粗略分为两部分,分别为base layer(基础网络)和residual layer(残差网络)。其中base layer是用一层卷积代替相关滤波,而残差网络又细分为空域残差和时域残差两个部分。base layer和residual layer分别得到三个相应图后进行一个合并,将合并后得到的相应图作为最终相应图。

此外,CREST还利用了时间残差,用于应对空间残差无效的情况。时间残差层的网络结构与空间残差层相似。从包含初始目标外观的第一帧提取时间输入。用Xt表示第t帧的输入X,因此CREST可以表示为:(这时的FR应该是FB)
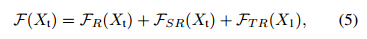
给定输入图像,首先以前一帧的估计位置为中心提取搜索图像块。这个块被送到特征提取网络,然后通过基层和残差层回归,生成响应图。
当目标对象外观变化小时,基层输出与标记值的差异很小,残差层对最终响应图没有什么影响。然而,当目标对象外观变化大时(比如背景混乱),基层的响应是有限的,可能无法区分目标和背景。这时,通过对基层输出与标记值之间的差异进行建模,残差层可以减轻这种限制。通过增加残差层,可以减轻最终输出的噪声响应值。因此,目标响应对目标外观变化较大的情况更鲁棒。
CREST具体流程
模型更新
第一帧以目标为中心裁剪一个patch块,然后将patch块输入VGGNET进行特征提取得到feature map。而跟踪网络部分采用随机初始化,跟踪网络在第一帧的输入feature map而label是第一帧已知目标形成的一个高斯label。利用反向传播进行训练,得到用于跟踪的网络。
在线检测
从第二帧开始进入跟踪阶段,以上一帧得到的目标位置为中心裁剪patch块,然后进入VGG进行特征提取,再将特征放入跟踪网络中进行一次前向传播,得到最后的响应图,而响应图中最大点的响应被认为是目标。
尺度估计
在多个尺度求最大响应,然后考虑到尺度变化问题,作者采用以下更新公式
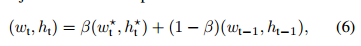
模型更新
作者在论文中每隔2帧对跟踪器进行更新。
实验
搜索区域大小:5倍搜索域;
特征选取:使用只保留前两个池化层的VGG-16网络中conv4-3层经PCA降维到64通道后作为特征;
真值标记:二维高斯分布,峰值为1;
尺度平滑参数beta:0.6;
其他配置:使用MatConvNet框架实现;模型初始化时,训练学习率为5e-8,当loss小于0.02停止;模型更新时,每两帧更新一次,更新时迭代2次,学习率为2e-9;
实验数据集:OTB-2013,OTB-2015,VOT-2016;
https://blog.csdn.net/youmenshan3316/article/details/83625924
https://blog.csdn.net/qq_22763299/article/details/79852758

 浙公网安备 33010602011771号
浙公网安备 33010602011771号