堆排序
定义
Heap是一种数据结构具有以下的特点:
1)完全二叉树;
2)heap中存储的值是偏序;
Min-heap: 父节点的值小于或等于子节点的值;
Max-heap: 父节点的值大于或等于子节点的值;
用通俗语言来说,大根堆就是每个最大的数字在每个子树的最上方,及大根堆pop值为最大值,小根堆反之
堆的存储
堆的存储一般由数组表示,由于堆的实质就是完全二叉树,所以对于每个i来说(从0开始),左右孩子分别为2i+1,2i+2,父节点为(i-1)/2,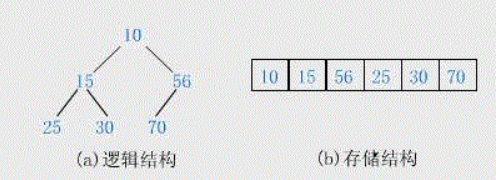
堆的核心操作(手写与系统均有)
heapinsert与heapify
1.heapinsert:加入一个节点,通过上升的方式,依次进行比较,(上升操作),时间复杂度为o(logN)因为树的深度为logN
swap为交换操作


private void heapInsert(int[] arr, int index) { while (arr[index] > arr[(index - 1) / 2]) { swap(arr, index, (index - 1) / 2); index = (index - 1) / 2; } }
2.heapify:弹出根结点之后的,将剩余变成堆的操作(下沉操作),因为弹出根结点后,会将数组最后面的数字顶替为根结点,所以只需将该结点进行下沉操作即可,时间复杂度为o(logN)树的深度为logN
首先设置研究这个问题的前置条件:
假设目标堆是一个满堆,即第 k 层节点数为 2ᵏ。输入数组规模为 n, 堆的高度为 h, 那么 n 与 h 之间满足 n=2ʰ⁺¹ - 1,可化为 h=log₂(n+1) - 1。 (层数 k 和高度 h 均从 0 开始,即只有根节点的堆高度为0,空堆高度为 -1)。
建堆过程中每个节点需要一次下滤操作,交换的次数等于该节点到叶节点的深度。那么每一层中所有节点的交换次数为节点个数乘以叶节点到该节点的深度(如第一层的交换次数为 2⁰ · h,第二层的交换次数为 2¹ · (h-1),如此类推)。从堆顶到最后一层的交换次数 Sn 进行求和:
Sn = 2⁰ · h + 2¹ · (h - 1) + 2² · (h - 2) + ...... + 2ʰ⁻² · 2 + 2ʰ⁻¹ · 1 + 2ʰ · 0
把首尾两个元素简化,记为①式:
①: Sn = h + 2¹ · (h - 1) + 2² · (h - 2) + ...... + 2ʰ⁻² · 2 + 2ʰ⁻¹
对①等于号左右两边乘以2,记为②式:
②: 2Sn = 2¹ · h + 2² · (h - 1) + 2³ · (h - 2) + ...... + 2ʰ⁻¹ · 2 + 2ʰ
那么用②式减去①式,其中②式的操作数右移一位使指数相同的部分对齐(即错位相减法):
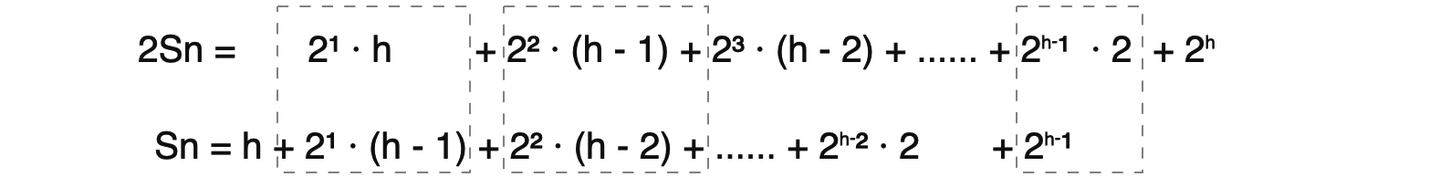
化简可得③式:
③ = Sn = -h + 2¹ + 2² + 2³ + ...... + 2ʰ⁻¹ + 2ʰ
对指数部分使用等比数列求和公式:
在这个等比数列中,a1=2, q=2,则③式为:
化简为④式:
④ = Sn = 2ʰ⁺¹ - (h + 2)
在前置条件中已得到堆的节点数 n 与高度 h 满足条件 n=2ʰ⁺¹ - 1(即 2ʰ⁺¹=n+1) 和 h=log₂(n+1) - 1,分别代入④式中的 2ʰ⁺¹ 和 h,因此:
化简后为:
Sn = n - log₂(n + 1)
因此最终可得渐进复杂度为 O(n).

swap为交换操作
/** * * @param arr 数组 * @param index 索引 * @param heapSize 堆大小 */ private void heapify(int[] arr, int index, int heapSize) { int left = index * 2 + 1; while (left < heapSize) { int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left; largest = arr[largest] > arr[index] ? largest : index; if (largest == index) { break; } swap(arr, largest, index); index = largest; left = index * 2 + 1; } }
堆排序
首先堆排序分为2部分
1.将一个无序数组变成堆
2.将堆进行排序核心操作(heapfiy,因为如果是大根堆的话,最大值在上方一直,heapfiy即可+swap(交换)即可)
首先分析第一个部分
通常有2中方法
1.最常用的一种是将数组依次遍历,最后一次加入堆中,便可将数组变成堆,但是此种方法的因为将数组中所以数进行遍历 (N),将每个数进行heapinsert(logN),所以时间复杂度为O(N*logN)
// O(N*logN) for (int i = 0; i < arr.length; i++) { // O(N) heapInsert(arr, i); // O(logN) }
2.对此有一种优化方法,从数组尾部开始遍历,然后进行下沉,由于是从尾部,那边可以得到下沉数字一定为有限常数
可以尝试这么理解,刚开始从尾部遍历,那么底部只有一层嘛,这时候heapify就为下沉0,倒数第二层时候,heapify为下沉1层,倒数第三层,heapify为下沉2层,有限个数时间复杂度为o(1)
那么总体便为o(N*1)=O(N)
for (int i = arr.length - 1; i >= 0; i--) { heapify(arr, i, arr.length); }
然后分析第二个部分
变成堆之后,例如大根堆,最大是数字是根结点,那么将最大的数字为尾部交换,然后将–heapsize,然后循环依次swap,heapify就ok了
这个方法的时间复杂度为o(n*logN)从顶部开始下沉,heapify是logN哈
详细代码如下
// 堆排序额外空间复杂度O(1) public static void heapSort(int[] arr) { if (arr == null || arr.length < 2) { return; } // O(N*logN) // for (int i = 0; i < arr.length; i++) { // O(N) // heapInsert(arr, i); // O(logN) // } //O(N) for (int i = arr.length - 1; i >= 0; i--) { heapify(arr, i, arr.length); } int heapSize = arr.length; swap(arr, 0, --heapSize); // O(N*logN) while (heapSize > 0) { // O(N) heapify(arr, 0, heapSize); // O(logN) swap(arr, 0, --heapSize); // O(1) } }
什么时候使用语言自带api,什么时候使用自己的手写api
首先我们需要明确一点,我们需要重写编写一个类代替原有api,肯定当前api无法满足我们的情况,我们来重写api达到我们的效果
我们现在来看一种效果,我们现在不是int类型,是一个引用类型例如Teacher(假设包含id,name),我们通过比较器(后续博客会有一篇详细结束比较器的,会更新的,嘿嘿)
对其进行id比较,变成堆之后,(切记是以及变成堆之后)我们对其中某一个Teacher进行操作,将他的id变化,那么这个时候整个堆会发生巨大变化(变成不是堆结构),而这不是用户本意,用户只是想修改某一个teacher的信息,然后依然希望这个list是堆,换句话说,修改之后依然希望类自己进行维护,修改之后的结构自己进行复原变成堆
所以这个时候,语言自带的api无法完成这个操作(java,python没有,就算某些语言有,也是进行整体heapinsert,时间复杂度太高不适应)这个时候我们便需要自己首先一个api,来完成此操作
手写解决上述问题优化的堆
核心思想便是使用HashMap<T, Integer> indexMap;对修改位置的索引进行记录,在push的时候将指针(地址)与索引进行记录在pop的时候进行删除,
核心在于regsion
通过值可以得到索引,然后对索引依次进行heapify与heapinsert巧妙在于因为堆的特性要么上升要么下沉,时间复杂度与o(logN)
public static class MyHeap<T> { private ArrayList<T> heap; private HashMap<T, Integer> indexMap; private int heapSize; private Comparator<? super T> comparator; public MyHeap(Comparator<? super T> com) { heap = new ArrayList<>(); indexMap = new HashMap<>(); heapSize = 0; comparator = com; } public boolean isEmpty() { return heapSize == 0; } public int size() { return heapSize; } public boolean contains(T key) { return indexMap.containsKey(key); } public void push(T value) { heap.add(value); indexMap.put(value, heapSize); heapInsert(heapSize++); } public T pop() { T ans = heap.get(0); int end = heapSize - 1; swap(0, end); heap.remove(end); indexMap.remove(ans); heapify(0, --heapSize); return ans; } public void resign(T value) { int valueIndex = indexMap.get(value); heapInsert(valueIndex); heapify(valueIndex, heapSize); } private void heapInsert(int index) { while (comparator.compare(heap.get(index), heap.get((index - 1) / 2)) < 0) { swap(index, (index - 1) / 2); index = (index - 1) / 2; } } private void heapify(int index, int heapSize) { int left = index * 2 + 1; while (left < heapSize) { int largest = left + 1 < heapSize && (comparator.compare(heap.get(left + 1), heap.get(left)) < 0) ? left + 1 : left; largest = comparator.compare(heap.get(largest), heap.get(index)) < 0 ? largest : index; if (largest == index) { break; } swap(largest, index); index = largest; left = index * 2 + 1; } } private void swap(int i, int j) { T o1 = heap.get(i); T o2 = heap.get(j); heap.set(i, o2); heap.set(j, o1); indexMap.put(o1, j); indexMap.put(o2, i); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号