KAFKA 实践:【十八】我们可以调整哪些参数来提高生产者的吞吐量?
大家好,这是一个为了梦想而保持学习的博客。这个专题会记录我对于 KAFKA 的学习和实战经验,希望对大家有所帮助,目录形式依旧为问答的方式,相当于是模拟面试。
前言
上一篇中,我们讲了 kafka-java-producer 的架构原理,整体图如下: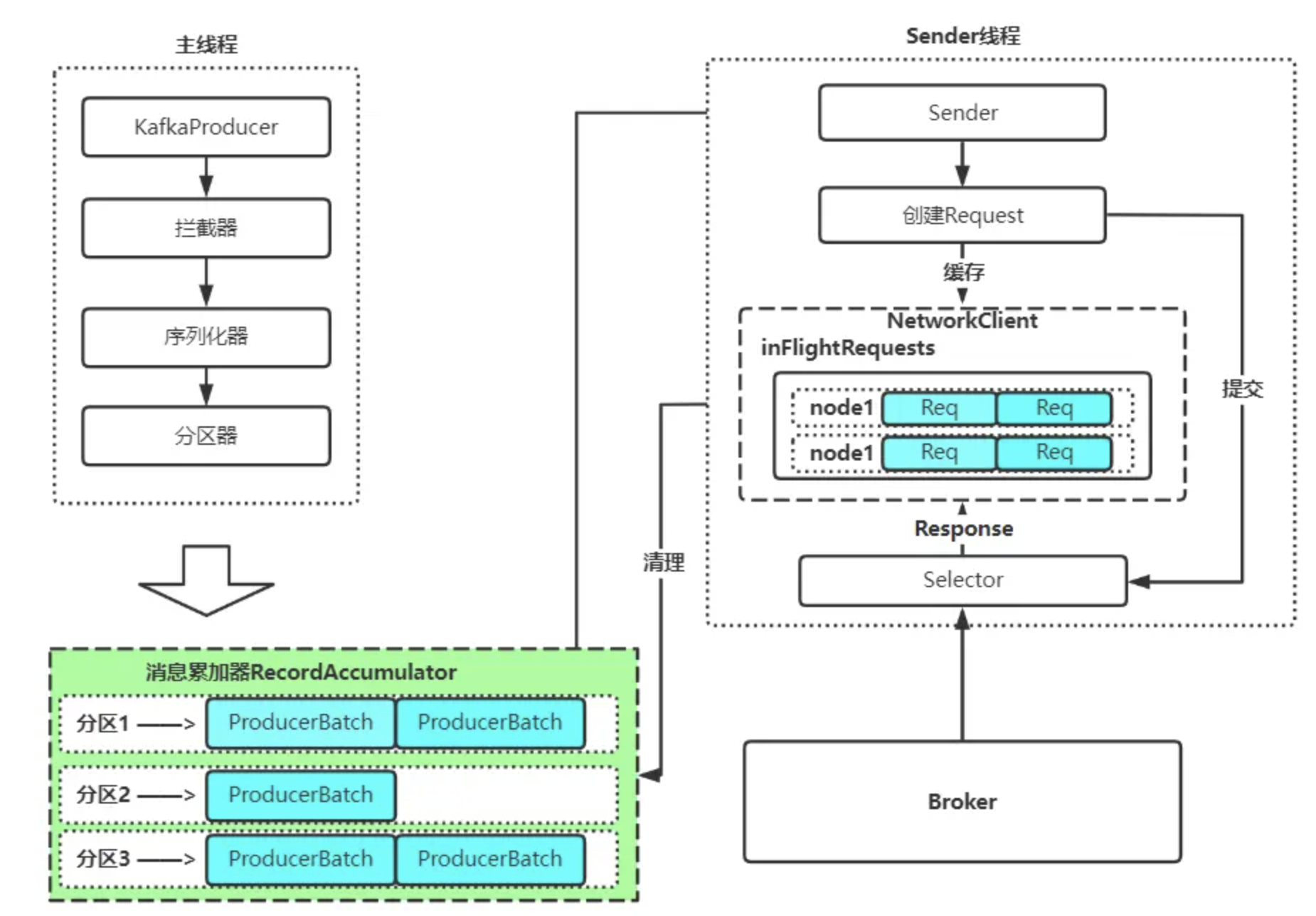
在了解了架构原理以及相关参数的作用之后,我们来思考一下我们生产环境下,如何提高生产者的生产速率,也就是提高生产者的吞吐量。
上面这一张图很重要,我们后续会按照这张图进行分析和整理。
线程安全的生产者客户端
首先,我们之前提到,kafka-java-producer 客户端是线程安全的,也就是上面的主线程那一块,是做了并发控制的。 因此,我们业务在使用的时候,就可以只创建一个 producer 对象,然后在全局进行使用。
常见的 producer 的使用问题:
- 每次业务使用的时候都重新 new 一个 producer 去进行使用。这种使用是非常不可取的,创建 producer 是非常耗时也耗资源的一个操作,如果每发一个消息就 new 一个出来,吞吐量会极低,而且会有频繁的 GC 问题,因为之前我们提到的每创建一个 produer 都会申请 32M 的缓冲区。除此之外还可能产生其他问题,但凡了解一点 kafka,都不应该这么使用。
- 为每个业务线程都创建一个生产者。这种使用方式正常来说是可以的,但是很不优雅,也没必要。为什么呢?因为本身 kafka-java-producer 客户端是线程安全的,而且性能很高,我们完全可以使用一个 producer 对象即可。
那正确的打开方式是如何的呢?
通常情况下,我们都会建议大家封装一个 Utils 类,在其中创建一个 KafkaProducer 对象;业务在需要发送消息的时候呢,直接根据 Utils 去进行发送即可,不用在意多线程问题,因为 kafka-java-producer 客户端是线程安全。
至于是同步发送,还是异步发送,需要根据自己的业务去进行选择。
我这边建议的话,没有一些严格消息丢失 / 消息顺序的要求的话直接异步发送,只需要设置好回调函数即可。
缓冲区
接着,我们顺着上面的思路,消息通过 interceptors、序列化器、分区器,最终会被写到 RecordAccumulator 这个缓冲区中。
我们知道这个缓冲区默认是有大小限制的,32M。 如果你的业务消息非常多,那么是有可能把缓冲区写满的,尤其是在你的单条消息非常大的时候 (上 M 级别)。 所以如果存在上面这两种可能,大家可以根据当前机器的资源情况,把这个参数设置得大一点,64M,128M 都是可以的。
对应的控制参数 (单位是 b):buffer.memory
批处理 & linger.ms
然后,消息存在缓冲区中,会被封装成一个个的 Batch,这个 Batch 默认大小是 16Kb。
这个参数非常关键,因为它不仅仅代表 kafka 的批处理,还影响着上面缓冲区的内存复用单位大小。
我们通常建议大家可以适当调大这个值,尤其是在业务单条数据可能超过 16kb 的时候,因为这会导致缓冲区无法复用内存,直接走内存分配,然后加重gc的负担,从而影响吞吐量。
我们在上一节也提到过,设置了 batch.size 的时候,一定要设置 linger.ms,否则是不生效的。
具体缘由在上一节讲过了就不再重复了,但是还需要讨论下 linger.ms 这个参数该怎么设置,设置多大?
这个没办法给出一个具体的值,最好是进行压测看一下,你设置的 batch.size 大概多长时间可能被写满,然后你就可以把 linger.ms 设置成那么长的时间。
当然,如果你的业务对时延非常敏感,那么这一小节的内容将不适用。
这一小节涉及到的参数:
batch.size根据业务消息大小进行设置linger.ms最好进行压测后再设置,一般设置个 5ms、10ms 也都 ok,不宜太长。
max.in.flight.requests.per.connection
接着,消息被从缓冲区中取出,封装成 Request,最后在发送时,暂存在 InFlightRequests 中。
这里有什么可优化的点吗?这其实就是这一小节的 title 的那个参数,这个参数是控制 InFlightRequests 中节点队列的请求个数的,默认是 5,也就是运行发出去 5 个请求没收到响应,如果是第六个就无法发送,得等前面的超时了或者收到响应了才能被处理。
这个参数,如果不是业务要实现消息不丢失 / 顺序的特殊要求的话,一般不建议修改它;这里提到呢,因为是按照消息流转的顺序进行梳理的。
回调处理
最后,消息被发送出去了,写入 InFlightRequests。最终呢,这个发出去的请求会得到一个具体的结果:成功响应 / 超时。这时候呢,Sender 线程就会去执行我们业务的回调。
这个回调函数的逻辑,是我们进行优化提升最明显的地方。
我强调一下:一定不要在回调函数里面去执行非常重的一些操作,例如更新 db、rpc 等。
至于原因在上一篇中有讲。
那我们实在是要做这些操作怎么办呢?
建议进行异步操作,丢到一个线程池中去处理这些回调操作,不要影响到 kafkaSender 线程。
JVM 参数
在讲完整个消息发送流程之后,如果是 java 应用,不可避免的受到 JVM 的影响。
我之前遇到过一个 case,是客户的 JVM 参数设置的极不合理导致频繁 FullGC。
有多严重呢总共跑了 3000s,GC 的时间占了 2500s... 这是一个真是的按理,所以建议大家从上面的参数都根据情况设置了依旧无法有明显的改善,那么可以用 jstat 看下 JVM 的 GC 情况,以及看下 JVM 参数信息。
其他
最后,我们上面只是从流程方面,梳理了相关可以提升吞吐量的参数。但是实际使用中可能遇到各式各样的问题,什么网络啦、带宽啦,负载啦之类的。
如果大家要排查生产吞吐上不去的问题的话,建议顺序是 :回调函数逻辑 -> 消息大小及上面提到的参数 -> JVM -> 网络及其他 -> 服务端
这里最后一环是服务端,是想让大家明白,有时候吞吐量上不去,不一定是客户端问题,也有可能是服务端处理的问题。
服务端的优化,这里就不讲了,后续有时间再整理一下。如果仅仅是排查为什么服务端生产请求处理慢的话,我们只需要看下服务端的 PRODUCE 请求处理时长即可,看下到底是哪个阶段耗时比较长即可定位。
如果说,看到的耗时阶段是 Send 之类的话,我们可以查下提到的两个网络参数,兴许有所帮助。send.buffer.bytesreceive.buffer.bytes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号