KAFKA 进阶:【十一】总结一下,KAFKA 的高并发、高吞吐等特性?
大家好,这是一个为了梦想而保持学习的博客。这个专题会记录我对于 KAFKA 的学习和实战经验,希望对大家有所帮助,目录形式依旧为问答的方式,相当于是模拟面试。
写在前面
在我们基本了解了 kafka 服务端的各个角色以及一些机制之后,在这一小节对 kafka 一些特性进行总结。
一、各个特性基础总结
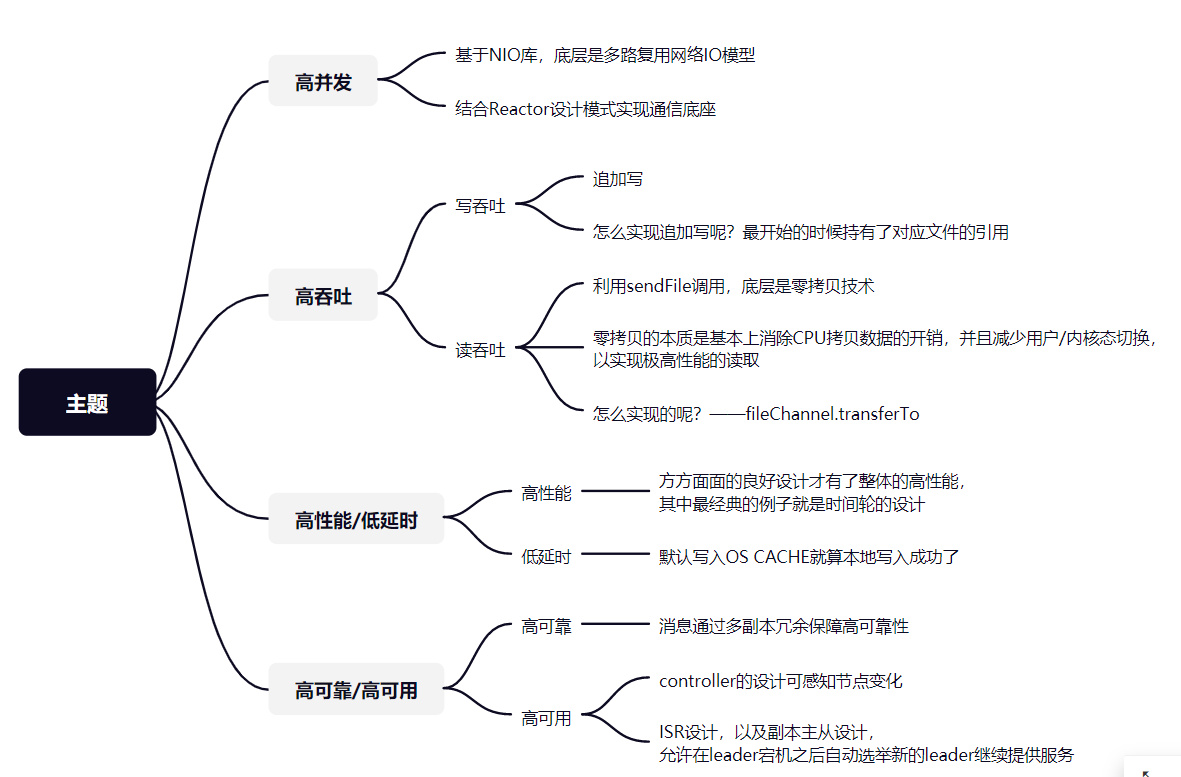
1、高并发
这个通常是说一个系统能承受大量的连接,已经非常高的并发;
在 kafka 中,主要是得益于优秀的网络通信框架设计,即前面讲到的结合 Reactor 设计模式实现的网络底座。
这个网络框架封装自 Java 的 NIO 库,底层的网络 IO 模型采用的是多路复用的网络 IO,也就是通过一个 selector 可以管理成千上万的连接,相比于传统 BIO 大大的节约了服务端维护连接的开销。
其次就是结合 Reactor 设计模式实现的网络底座,分为三个角色,acceptor、processor、handler,将网络事件与业务逻辑进一步拆分解解耦,提升了网络事件的执行效率。
2、高吞吐
吞吐需要分为两部分讨论
2.1、写入吞吐量,主要是得益于追加写的性能极高,kafka 是如何实现追加写的呢?简单的说来其实底层就是持有目标文件的 channel,然后基于 channel 去进行追加写即可,
那么是怎么持有文件的 channel 的呢?在创建 segment 也就是日志文件的时候就已经知道对应文件在哪儿并持有对应的 file 引用了,因此就避免了还需要进行磁盘寻址的开销,
基于这个文件的 channel 就可以进行追加写入。(这里的顺序写理解的有点问题,后续我补充一篇单独说明)
public static FileRecords open(File file,
boolean mutable,
boolean fileAlreadyExists,
int initFileSize,
boolean preallocate) throws IOException {
// 拿到这个log文件对应的fileChannel
FileChannel channel = openChannel(file, mutable, fileAlreadyExists, initFileSize, preallocate);
int end = (!fileAlreadyExists && preallocate) ? 0 : Integer.MAX_VALUE;
return new FileRecords(file, channel, 0, end, false);
}
private static FileChannel openChannel(File file,
boolean mutable,
boolean fileAlreadyExists,
int initFileSize,
boolean preallocate) throws IOException {
// 通过RandomAccessFile拿到对应的fileChannel
if (mutable) {
if (fileAlreadyExists) {
return new RandomAccessFile(file, "rw").getChannel();
} else {
if (preallocate) {
RandomAccessFile randomAccessFile = new RandomAccessFile(file, "rw");
randomAccessFile.setLength(initFileSize);
return randomAccessFile.getChannel();
} else {
return new RandomAccessFile(file, "rw").getChannel();
}
}
} else {
return new FileInputStream(file).getChannel();
}
}
public int writeFullyTo(GatheringByteChannel channel) throws IOException {
// 这个buffermemoryRecords中的一个属性
// 在初始化的时候被赋值的
// 那么在哪里初始化的呢?这个是从ProduceRequest中被取出来的
buffer.mark();
// 经典的NIO写文件循环操作
int written = 0;
while (written < sizeInBytes())
// 直接写os cache中,而不是写在磁盘文件里
written += channel.write(buffer);
buffer.reset();
return written;
}
2.2、读取吞吐量,这个主要是利用网上常说的 zore copy,这零拷贝简单的说来 OS 提供了一个系统调用,可以让网卡根据少量的元数据信息,就可以直接从 OS CACHE 中读取目标数据
从而避免了这部分数据拷贝到用户空间(JVM),再拷贝到 socket 缓冲区,几乎消除了 CPU 拷贝数据的开销,同时也减少了用户态 / 内核态切换的开销,从而在数据发送的方面,zore copy 性能极高。
关系零拷贝的细节,推荐阅读:https://zhuanlan.zhihu.com/p/308054212
话又说回来,kafka 是怎么利用 zore copy 的呢?很简单,源码如下 FileRecords 的 writeTo 函数:(详细细节会在后续的生产 / 消费全链路剖析)
public long writeTo(GatheringByteChannel destChannel, long offset, int length) throws IOException {
long newSize = Math.min(channel.size(), end) - start;
int oldSize = sizeInBytes();
if (newSize < oldSize)
throw new KafkaException(String.format(
"Size of FileRecords %s has been truncated during write: old size %d, new size %d",
file.getAbsolutePath(), oldSize, newSize));
long position = start + offset;
int count = Math.min(length, oldSize);
final long bytesTransferred;
if (destChannel instanceof TransportLayer) {
TransportLayer tl = (TransportLayer) destChannel;
bytesTransferred = tl.transferFrom(channel, position, count);
} else {
bytesTransferred = channel.transferTo(position, count, destChannel);
}
return bytesTransferred;
}
3、高性能,低延时
这两个放在一起讨论呢,主要是这高性能这东西很泛,方方面面的良好设计才有了整体的高性能,举个栗子,前面提到的时间轮的设计,就是很经典的例子。
低延时主要是得益于可以写 OS CACHE,如果不设置强制刷盘的话,写入 OS CACHE 之后就算本地写入成功了,写内存是非常快的,所以结合追加写,整个操作的时延就非常低。
4、高可靠,高可用
高可靠一般是指消息高可靠,主要是基于副本设计,让一条数据有多个副本分散到不同的机器,从而提供了不错的高可靠性。
高可用一般是指机器出现宕机等异常情况依旧能正常提供服务,在服务端的体现的话,主要是就是 controller 的设计,可以通过 zk 感知到 broker 的变化,从而做一系列的状态变更;
最后还有 ISR 的设计,以及副本的主从设计,在出现 leader 副本所在 broker 宕机的时候,可以从剩余的优先副本中选出一个 leader 来继续提供服务,保障服务高可用。
二、思维导图
最后,上面都是进行比较泛口语话的描述,不是很好记忆,下面就给出整理的思维导图,这里说的都比较浅,其中很多细节都需要大家继续细化和深入下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号