
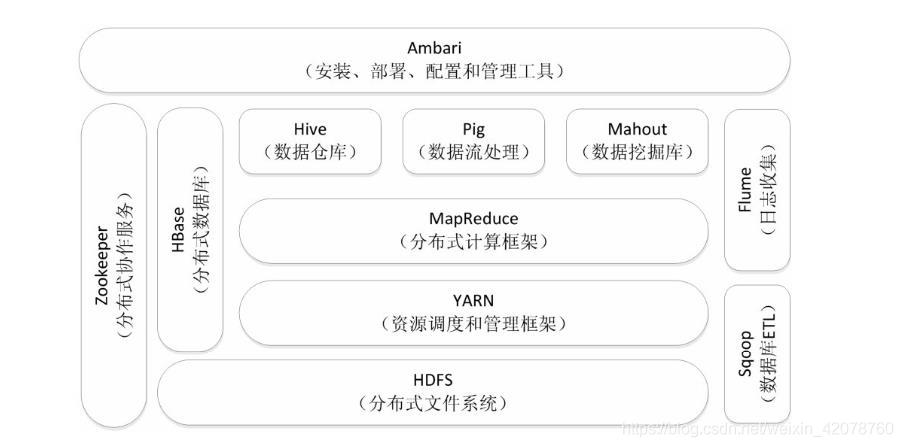
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
2.对比Hadoop与Spark的优缺点。
Hadoop的特性:
高可靠性、高效性、高可拓展性、高容错性、成本低、运行在Linux操作系统中、支持多种语言
Hadoop的缺点:
(1)表达能力有限。计算都必须要转化成Map和Reduce两个操作,但这并不适合所有的情况,难以描述复杂的数据处理过程。
(2)磁盘IO开销大。每次执行时都需要从磁盘读取数据,并且在计算完成后需要将中间结果写入磁盘中,IO开销较大。
(3)延迟高。一次计算可能需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接由于涉及IO开销,会产生较高延迟。而且,在前一个任务执行完成之前,其他任务无法开始,因此难以胜任复杂、多阶段的计算任务。
spark 的优点
(1)Spark的计算模式也属于MapReduce,但不局限于Map和Reduce 操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活。
(2)Spark提供了内存计算,中间结果直接放到内存中,带来了更高的迭代运算效率。
(3)Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
spark缺点
对硬件要求稍高一点
进行实际开发中,hadoop编写数量多的底层代码不高效,相对spark可以提供多种高层次、简洁的api
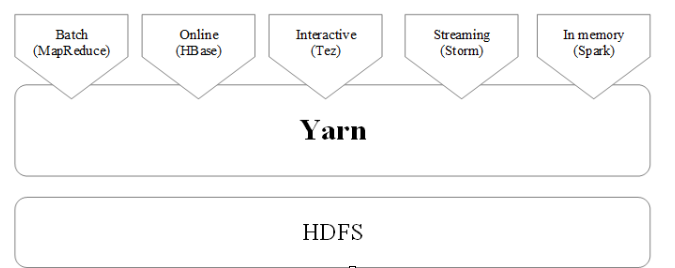
3.如何实现Hadoop与Spark的统一部署?
如图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号