

elk2


如果使用codec-》json进行解码,表示输入到logstast中的input数据必须是json的格式,否则会解码失败

java中一句代码异常会抛出多条的堆栈日志,我们可以使用上面的mutiline进行聚合

^\s匹配以字符开头的,previous表示当前如果不是以字符开头就连接上上面的数据之后,上面就满足了第2 3 4 5 6 都不满足以字符开头,就可以把抛出了多条异常日志合并到一条日志上
总结:把多条日志合并到一条日志中
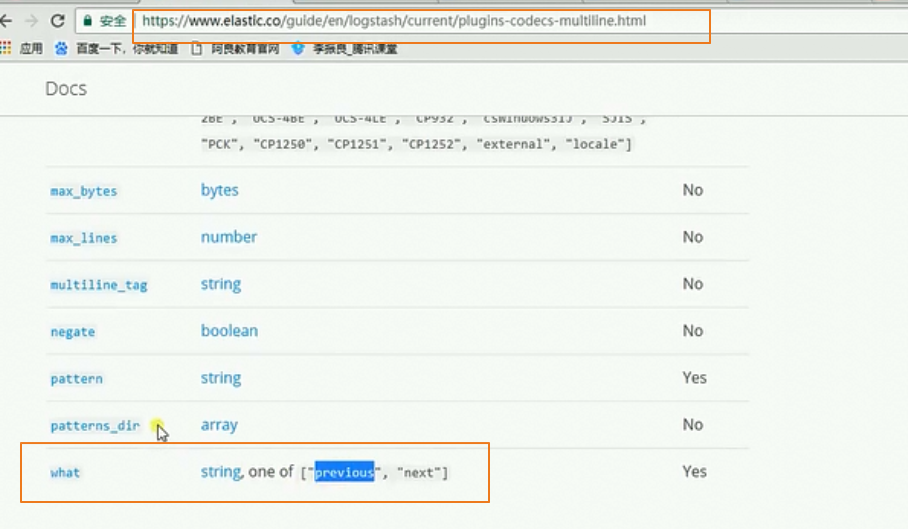
next表示不匹配合并到下一条数据的后面

logstash的filter插件

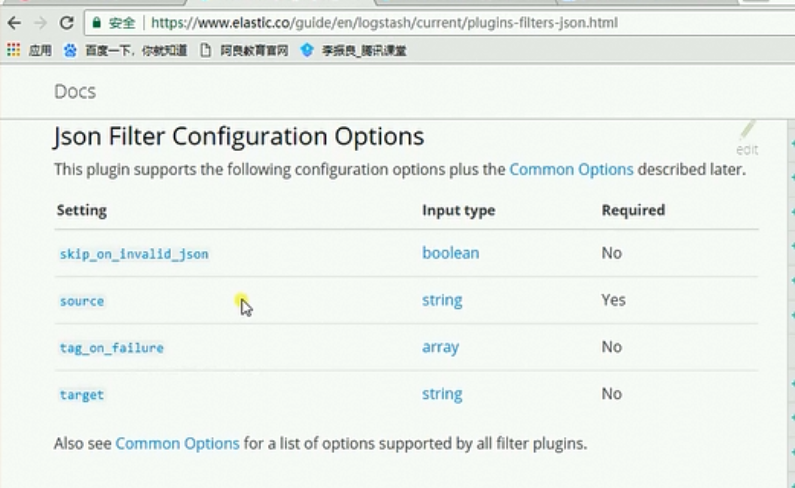
json字段参数配置
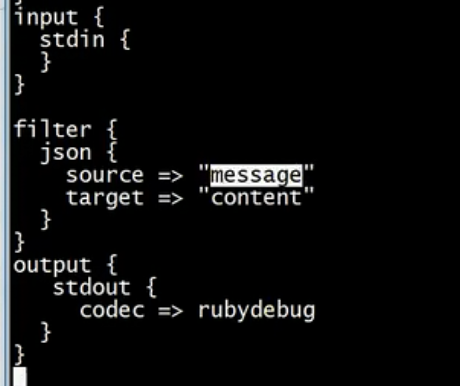
source表示你要解析的内容中来自message字段,解析之后将解析之后的内容存储在content字段中
分隔符号
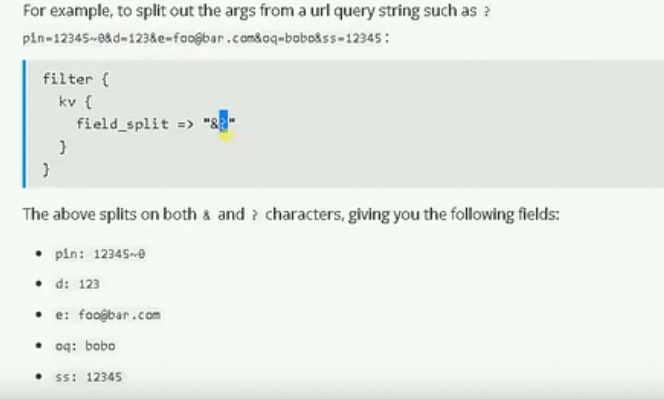

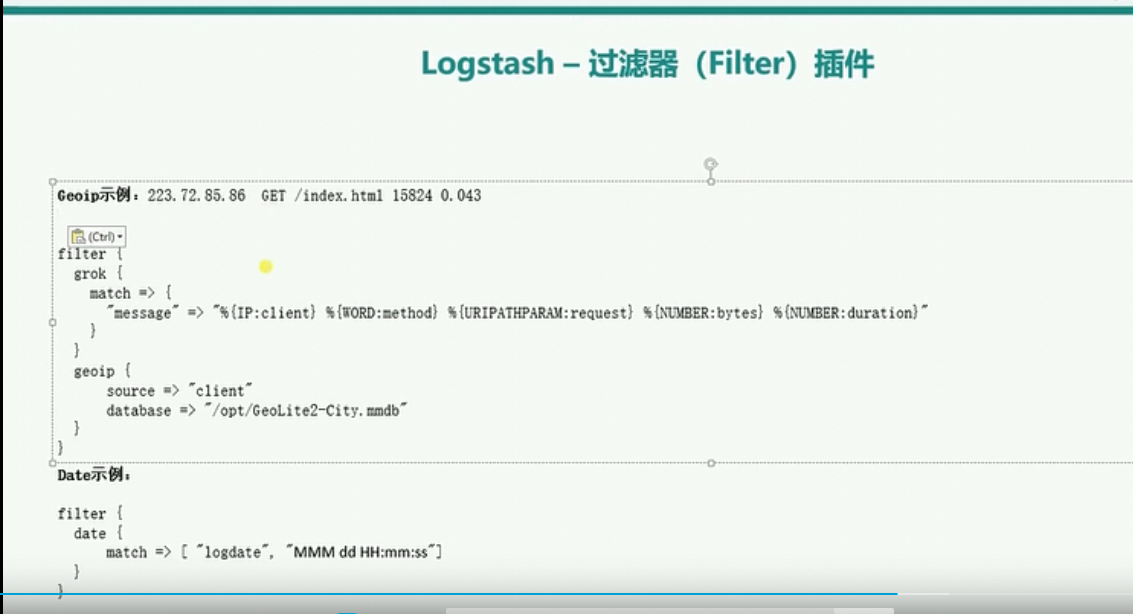
geoip
logstash得grok可以对收集得数据进行过滤,geoip可以对过滤后得数据字段再进行细分,然后根据内建得geoip库来得知访问得ip来自于哪个城市了。官方文档详解地址https://www.elastic.co/guide/en/logstash/current/logstash-config-for-filebeat-modules.html#parsing-nginx
首先我们需要去下载地址库,可以自行选择城市还是国家。https://dev.maxmind.com/geoip/geoip2/geolite2/
这个数据库因该放在logstash主机上,能够被过滤器插件访问和使用。
database指定geoip数据库所在的位置
上面gork插件中%{IP:client}实际上IP使用了gork自带的下面的IP对于的表达式进行匹配
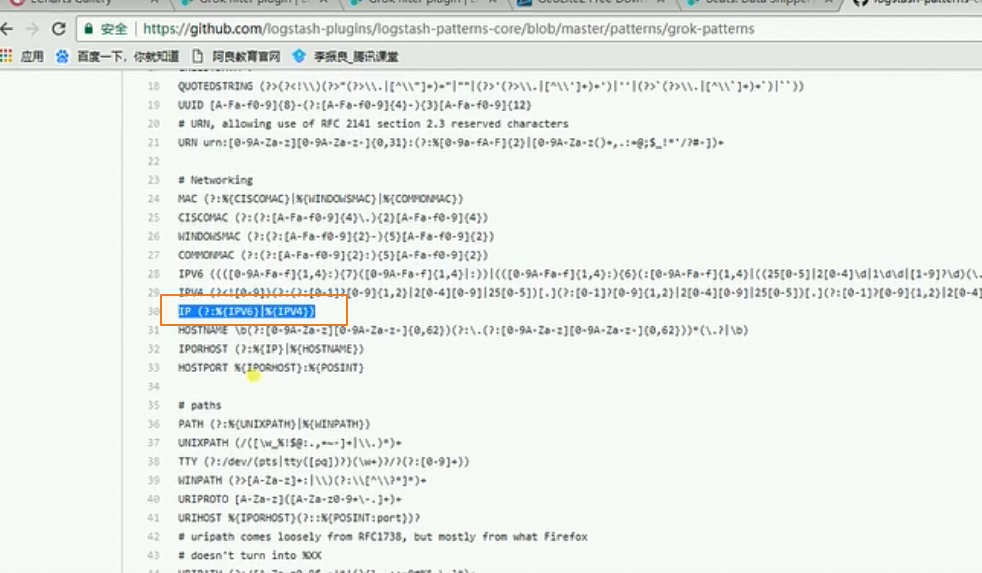


模板



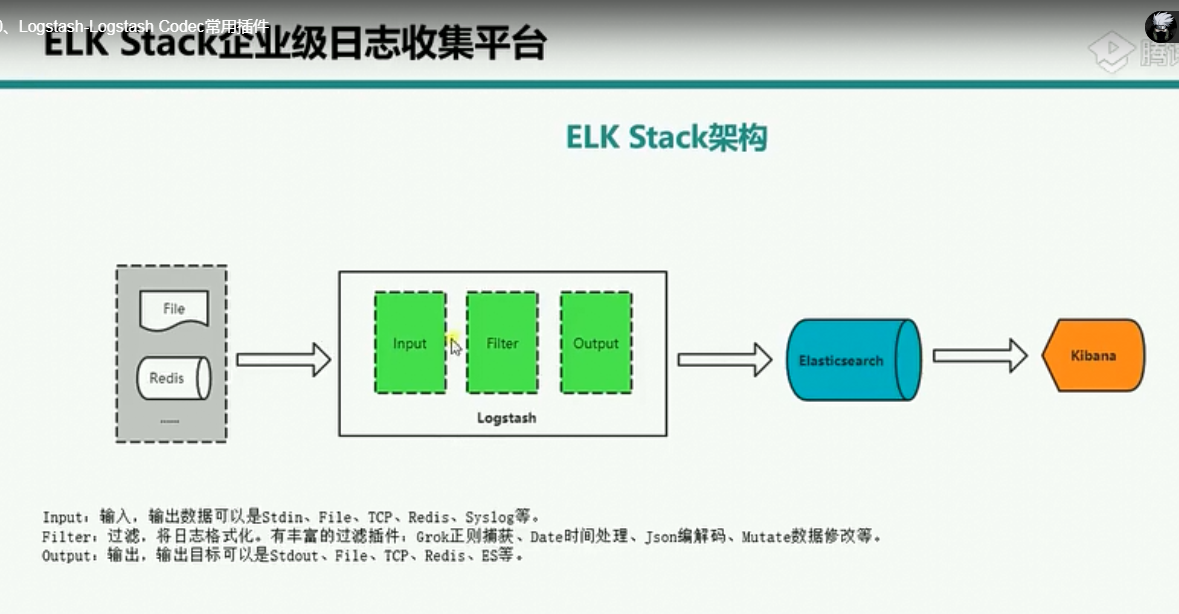
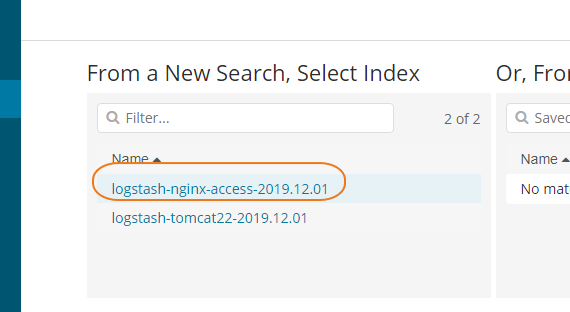
索引日志按照天进行存储, type和tags是进行日志区分的

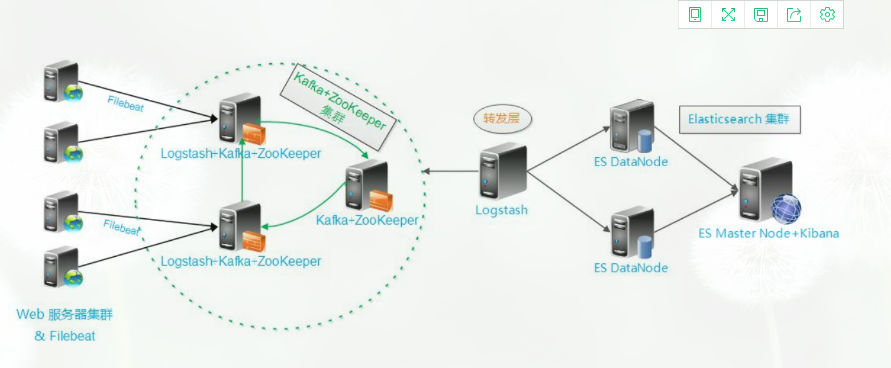
引入redis可以减少数据库elasticserach的压力,减少数据库的io操作。首先logstash收集日志存储到redis中,然后另外一台logstash从redis中读取数据
logstash既可以收集日志,也可以对redis中的数据进行filter进行过滤
默认的yum源中没有redis,我们可以先安装下面的yum源

我们来看看匹配文件
logstash收集日志的配置文件
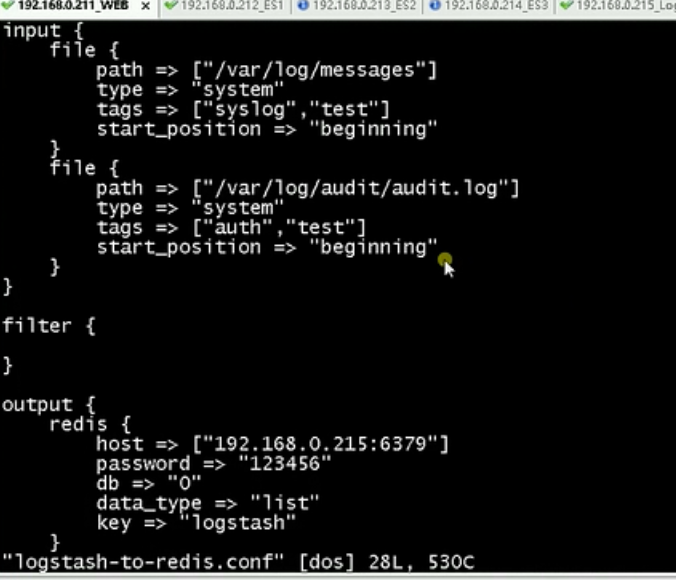
logstash过滤redis的配置文件,redis的密码是123456,这里注意host可以写redis的集群地址
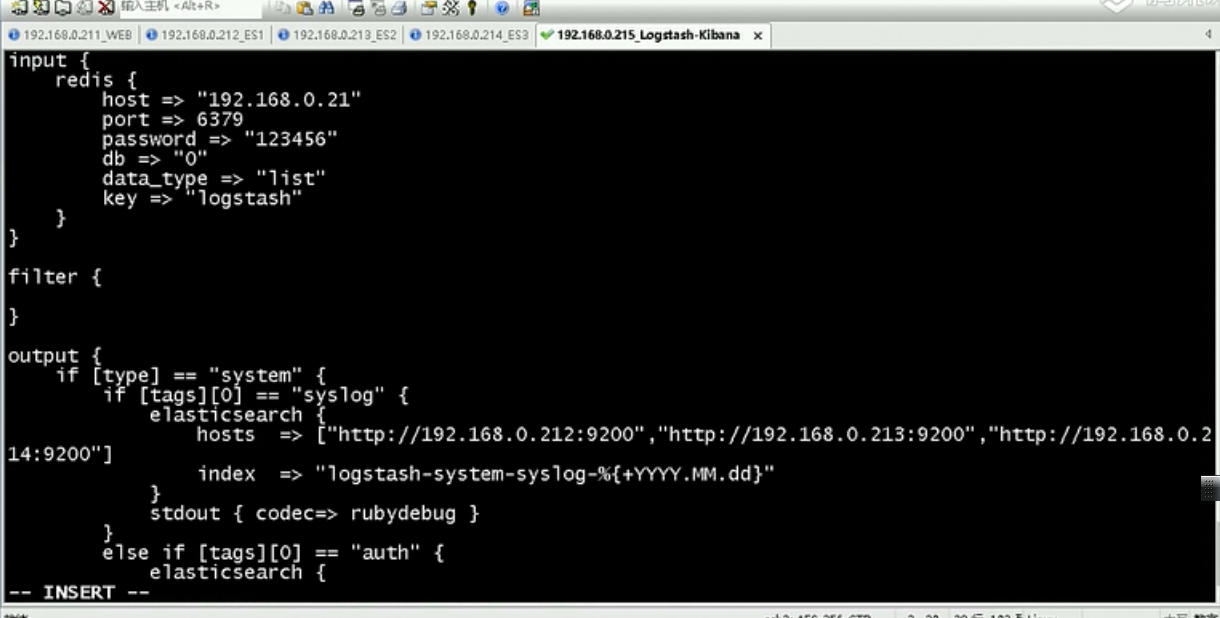
这里从redis读取数据的数据只能写某一台机器的具体名称,不能写redis的集群地址,要指定你要读取的key
上面架构的缺点:logstash是java开发的,占用资源较高,当数据量过大的时候,占用的cpu和内存都过大,官方推荐使用filebeat替换logstash收集日志

logstash的下面的配置

用filebeat修改为如下形式
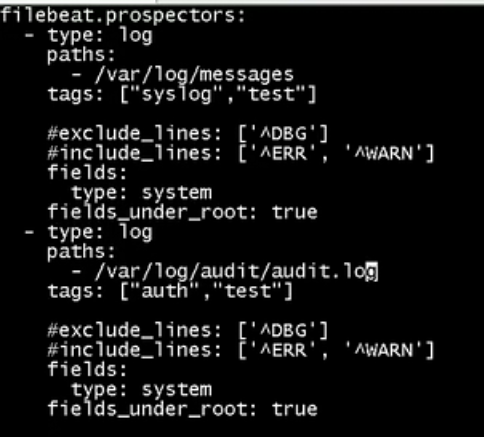
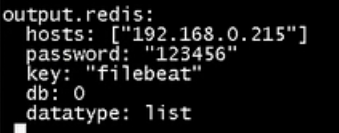
filebaeat想比较logsstah更加节省资源,我们可以对比下
filebeat和logstash在启动进程没有收集资源,不做任何处理情况下cpu和内存的一个对比



1、测试场景1.收集nginx的日志
nginx需要配置日志的类型为json类型
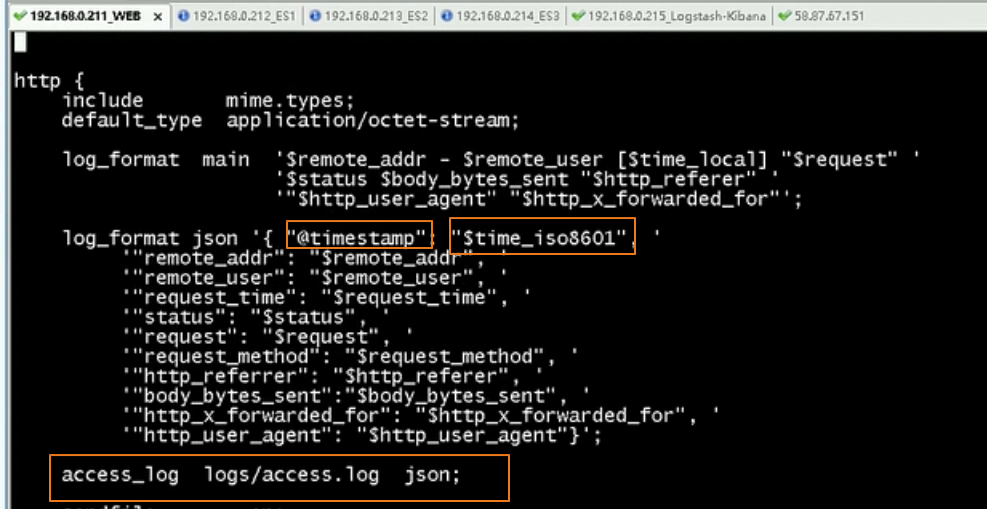
我们niginx的配置如下
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
log_format json '{"@timestamp":"$time_iso8601",'
'"clientip":"$remote_addr",'
'"status":$status,'
'"bodysize":$body_bytes_sent,'
'"referer":"$http_referer",'
'"ua":"$http_user_agent",'
'"handletime":$request_time,'
'"url":"$uri"}';
access_log logs/access.log;
access_log logs/access.json.log json;
使用当前用户请求的时间替换掉默认的kibana的@timestamp时间

logstash的配置文件如下所示


geoip依据请求的ip地址查询当前ip地址属于哪个城市,添加到字段geoip中
https://blog.csdn.net/weixin_40308100/article/details/88852842
接下来需要安装下面的插件
windows下安装如下
install logstash-filter-geoip
install logstash-filter-mutate
logstash-filter-useragent
windows下进入到logstash的bin目录下





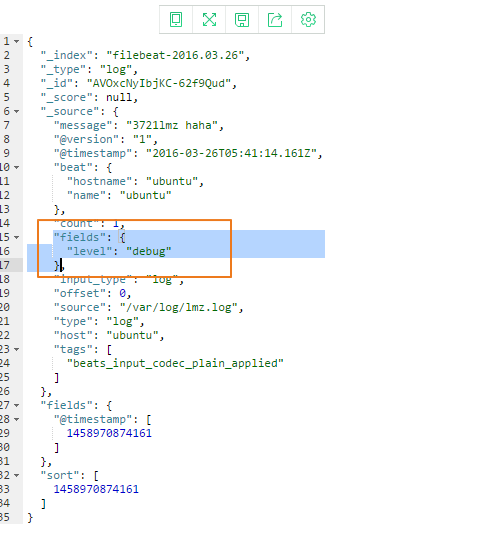
fields_under_root:如果该选项设置为true,则新增fields成为顶级目录,而不是将其放在fields目录下。
未设置为true
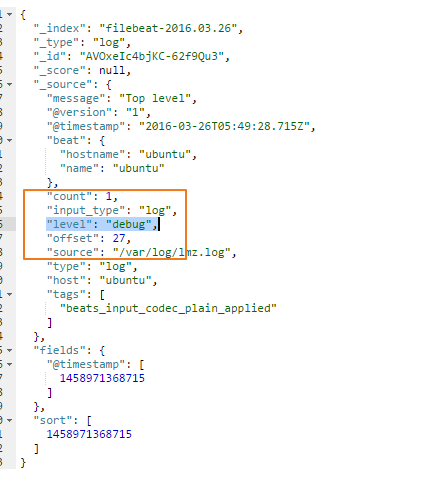
设置为true之后,level字段就在顶级目录之下
我们来看看整个配置文件
ngin的配置文件如下
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
log_format json '{"@timestamp":"$time_iso8601",'
'"remote_addr":"$remote_addr",'
'"status":$status,'
'"bodysize":$body_bytes_sent,'
'"referer":"$http_referer",'
'"ua":"$http_user_agent",'
'"handletime":$request_time,'
'"url":"$uri"}';
access_log logs/access.log;
access_log logs/access.json.log json;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
#引入自定义配置文件
include reverse-procy.conf;
server {
listen 8088;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
# another virtual host using mix of IP-, name-, and port-based configuration
#
#server {
# listen 8000;
# listen somename:8080;
# server_name somename alias another.alias;
# location / {
# root html;
# index index.html index.htm;
# }
#}
# HTTPS server
#
#server {
# listen 443 ssl;
# server_name localhost;
# ssl_certificate cert.pem;
# ssl_certificate_key cert.key;
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 5m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
# location / {
# root html;
# index index.html index.htm;
# }
#}
}
filebeat的配置值文件
filebeat.prospectors:
- type: log
enabled: true
paths:
#- /var/log/*.log
- C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.json.log
fields:
#- app表示项目名称
app: www
type: nginx-access
fields_under_root: true
- type: log
enabled: true
paths:
#- /var/log/*.log
- C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/error.log
fields:
#- app表示项目名称
app: www
type: nginx-error
fields_under_root: true
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output:
kafka:
hosts: ["localhost:9092"]
topic: nginx22
logstash的配置文件
input {
kafka {
bootstrap_servers => "localhost:9092"
topics => ["nginx22"]
group_id => "kafakaweithlogsh"
codec => "json"
}
}
filter {
if[app] == "www" {
if [type] == "nginx-access" {
json {
source => "message"
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
geoip{
# nginx源为字段
source => "remote_addr"
# 目标默认为geoip
target => "geoip"
database => "C:/Users/Administrator/Desktop/ELK/GeoLite2-City_20191126/GeoLite2-City_20191126/GeoLite2-City.mmdb"
# 目标默认为geoip
# 添加字段,值为经度
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
# 添加字段,值为纬度
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ]
}
mutate {
# 定义经纬度字段值为float格式
convert => [ "[geoip][coordinates]", "float"]
}
}
}
}
output{
elasticsearch {
hosts => ["http://localhost:9200"]
index => "logstash-%{type}-%{+YYYY.MM.dd}"
}
stdout {
codec=>rubydebug
}
}
这里特别要强调的是:es的优化
index => "logstash-%{type}-%{+YYYY.MM.dd},这里按照应用名称type+每天建立一个索引,不然会导致索引文件过大,导致es奔溃,这里很经典的东西,就可能存在一个索引文件过大有几十个G,elas就奔溃了
如果按照上面的方式建立索引,索引文件一般只有10G,效率很高

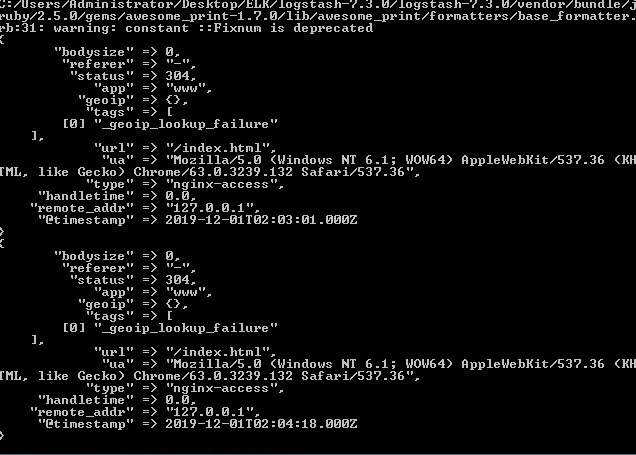
logstash中output到控制台的效果如下
![]()
1、生产上收集tomcat的堆栈日志
安装插件 logstash-filter-multiline
在线安装插件
# logstash-plugin install logstash-filter-multiline
Validating logstash-filter-multiline
Installing logstash-filter-multiline
Installation successfu
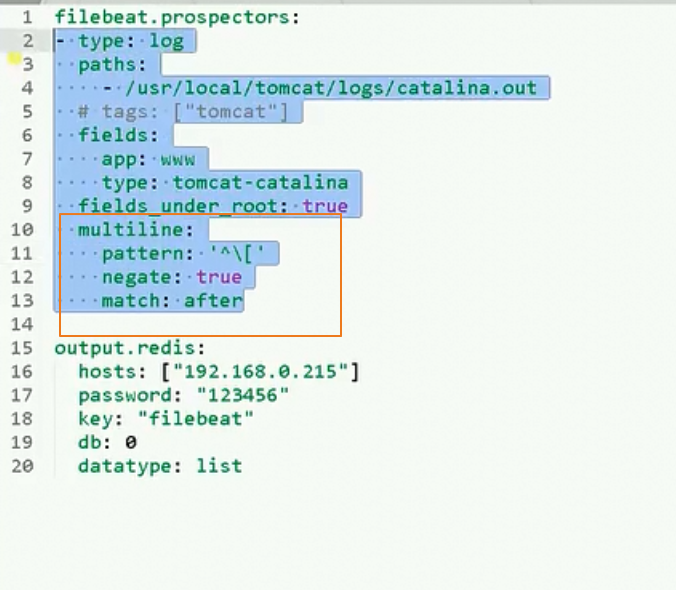
filebeat的配置文件如下
filebeat.prospectors:
- type: log
enabled: true
paths:
#- /var/log/*.log
- C:/Users/Administrator/Desktop/ELK/apache-tomcat-8.5.45/logs/catalina.log
fields:
#- app表示项目名称
app: www
type: tomcat
fields_under_root: true
multiline.pattern: '^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}'
multiline.negate: true
multiline.match: after
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output:
kafka:
hosts: ["localhost:9092"]
topic: tomcat22
logstash的配置文件如下
input {
kafka {
bootstrap_servers => "localhost:9092"
topics => ["tomcat22"]
group_id => "kafakaweithlogshtomcat"
}
}
output{
elasticsearch {
hosts => ["http://localhost:9200"]
index => "logstash-tomcat22-%{+YYYY.MM.dd}"
}
stdout {
codec=>rubydebug
}
}
这里有几个点需要注意的

tomcat产生堆栈异常日志的时候,格式是上面的形式
multiline.pattern: '^\s'
multiline.negate: true
multiline.match: after
上面表示,如果不以空格开头,则这一行是一条异常日志的开头行,它与接下来有1或多个空格开头的各行、构成一条完整日志。,匹配之后的内容添加到前一局内容的后面,这样就将异常的日志构建到一行上面

pv,统计每分钟的访问量


y轴选择度量指标为count
x轴选择时间


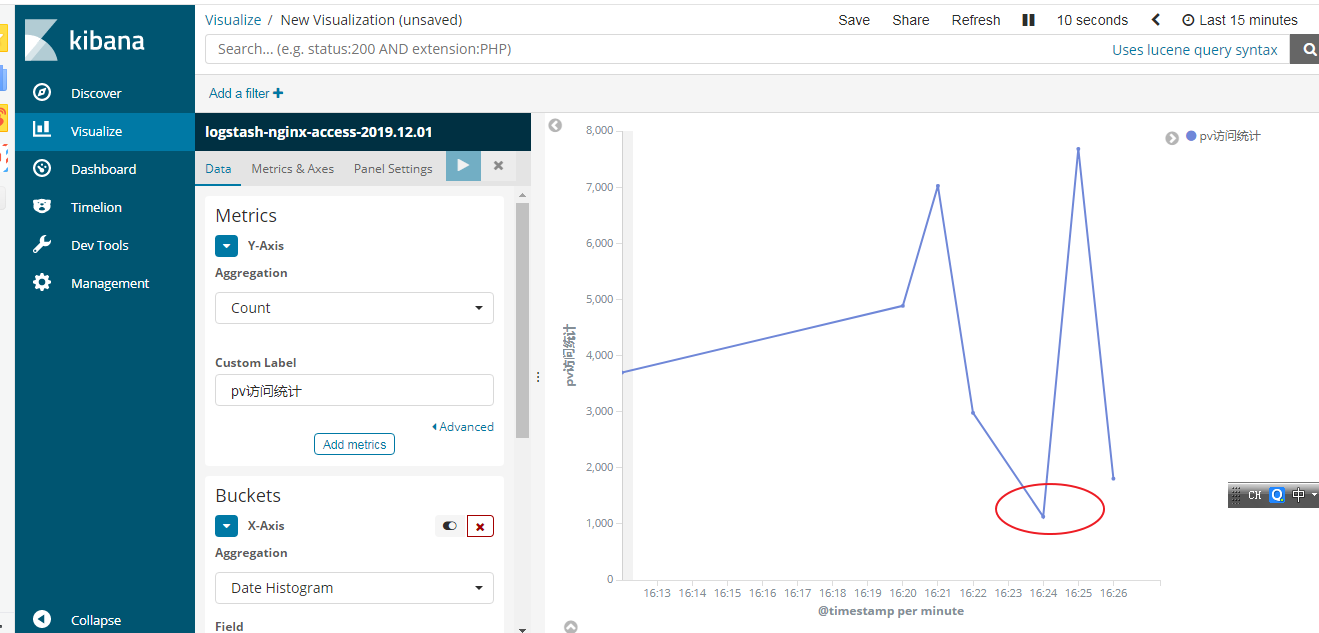
我们来看看16点24分钟的一个访问统计
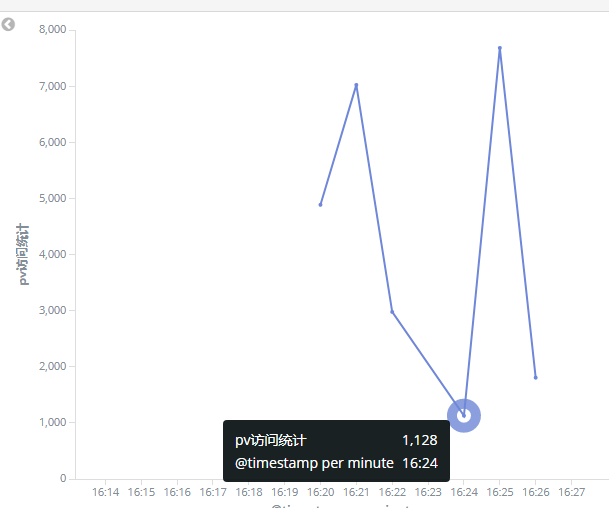
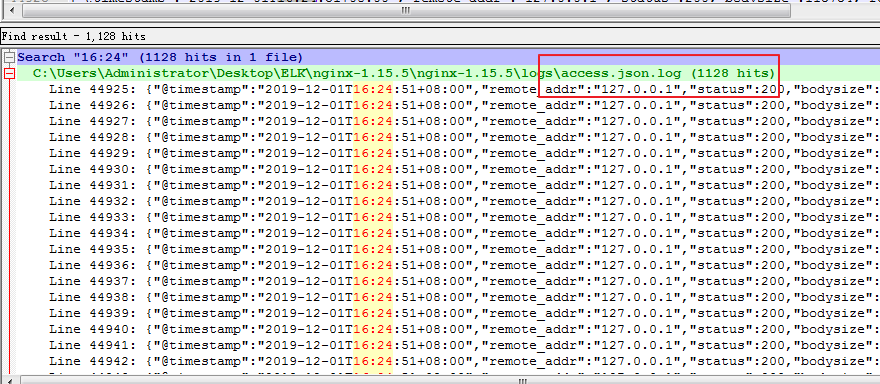
在16点24分之内一共访问了1128次,我们打开nginx的access.json.log日志,我们来对比下,和上面分析的一样
接下来我们来统计uv的统计
uv就是统计不同的ip地址
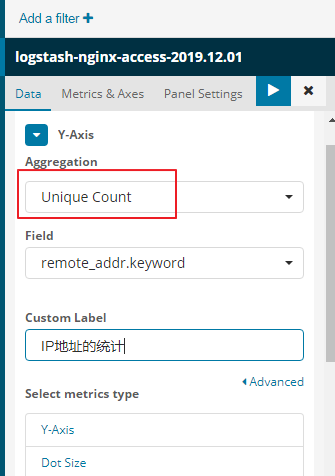
用户请求的IP地址有重复的,需要进行去掉重复的操作
展示效果如下

接下来统计geoip城市地址的统计
新建地图的地址
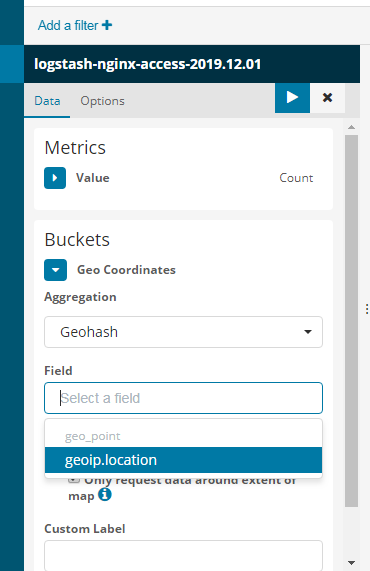
统计用户访问了哪些url
我们以列表的形式
y轴还是选择count
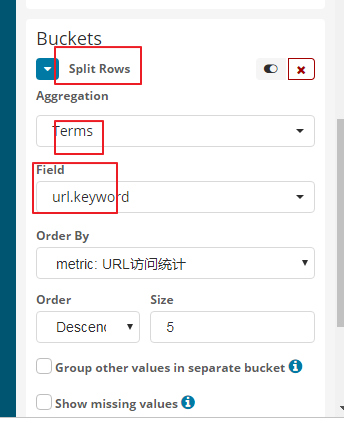
5表示你要显示的url的个数
我们也可以依据http的状态码进行统计
我们也是新建table的列表的形式进行展示

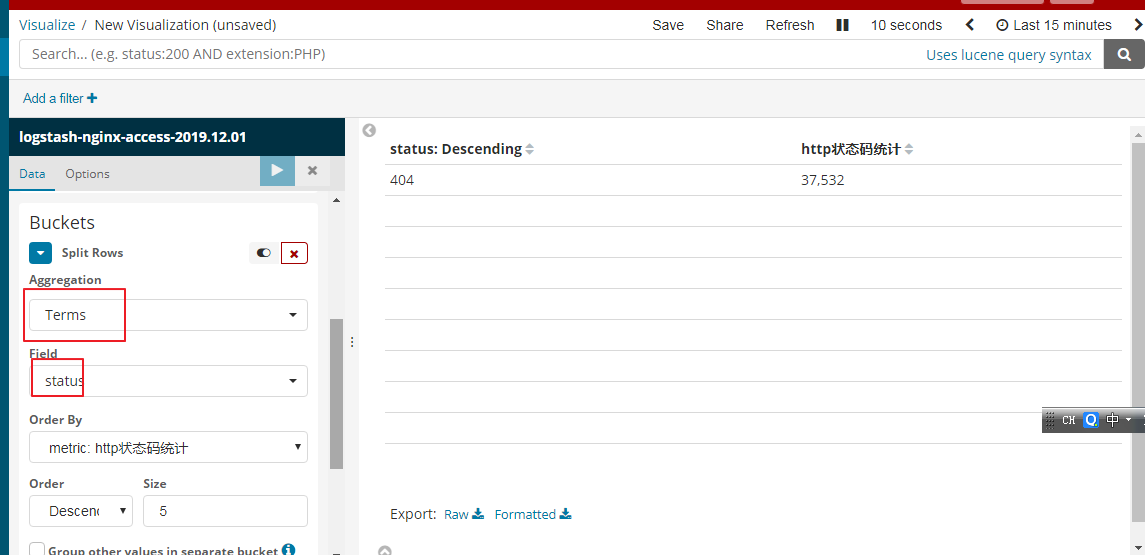
右上角可以选择你查看的时间

我们也按照访问的ip地址进行统计展示,效果如下

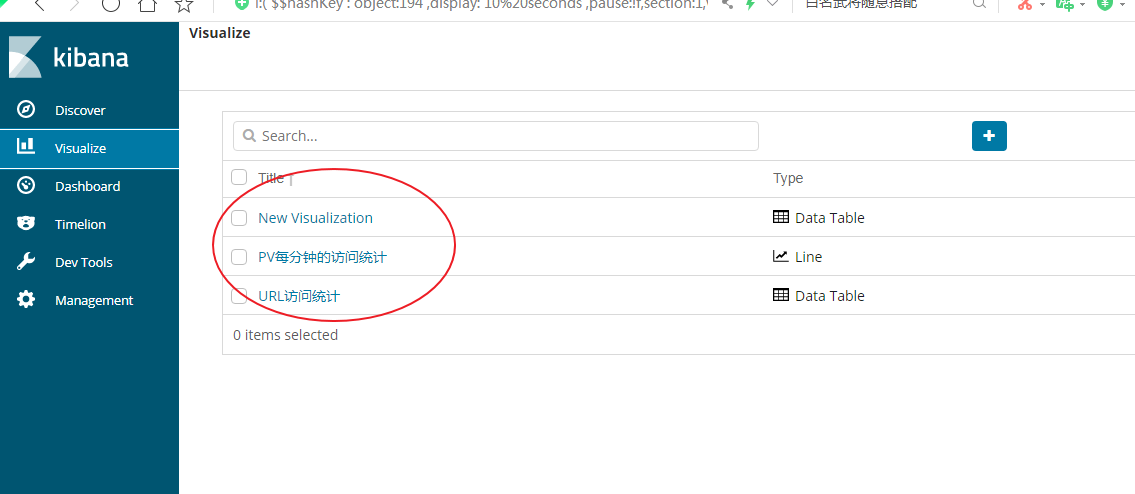
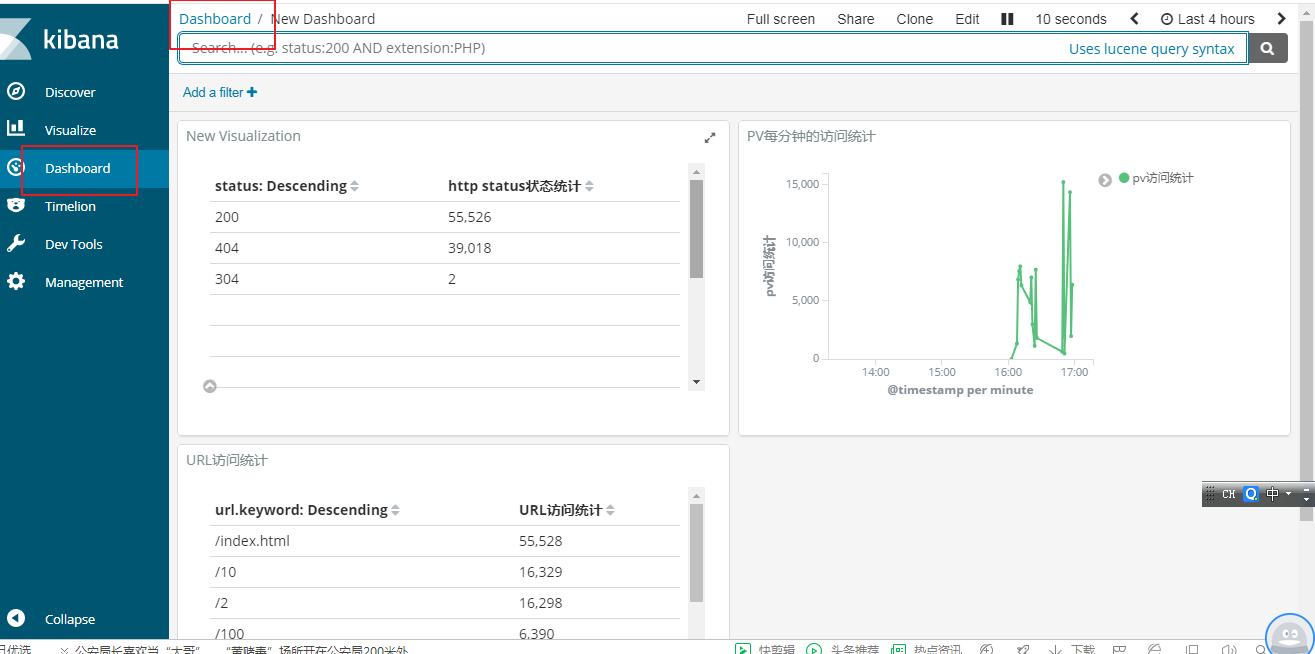
我们在可视图中创建了上面三种可视图的类型
我们接下来我们把上面的三种可视图类型添加到dashboard中
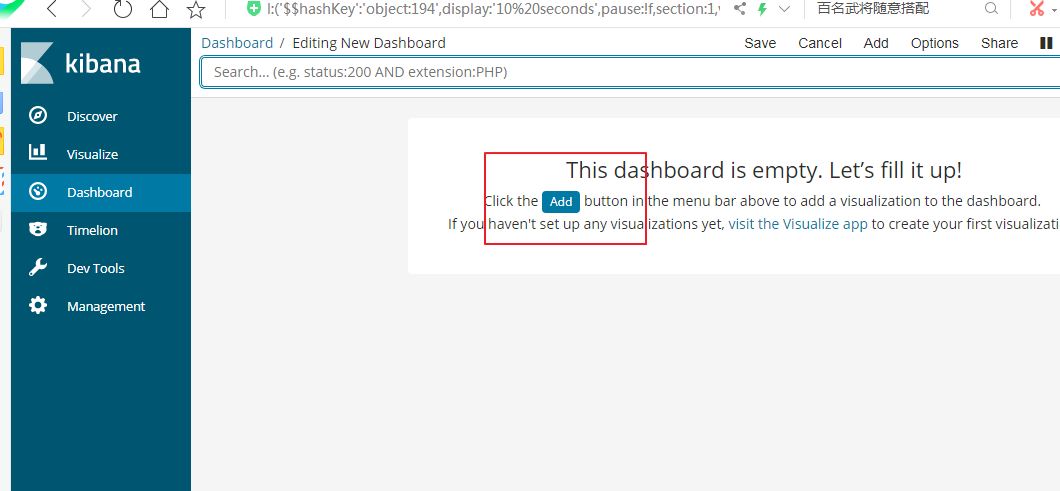
posted on 2019-11-29 11:07 luzhouxiaoshuai 阅读(302) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号