
【杂学】Efficient Training for DiT
Diffusion Transformer
首先说明一下Diffusion Transformer的基本原理,对于传统的diffusion model而言,重点是训练出一个模型,输入为当前图片和时间,输出为预测的噪声;DiT就是将这个模型从一直沿用的U-Net换成了Transformer,并将一些Conditioning融入生成过程,使得生成的图片可以被约束。
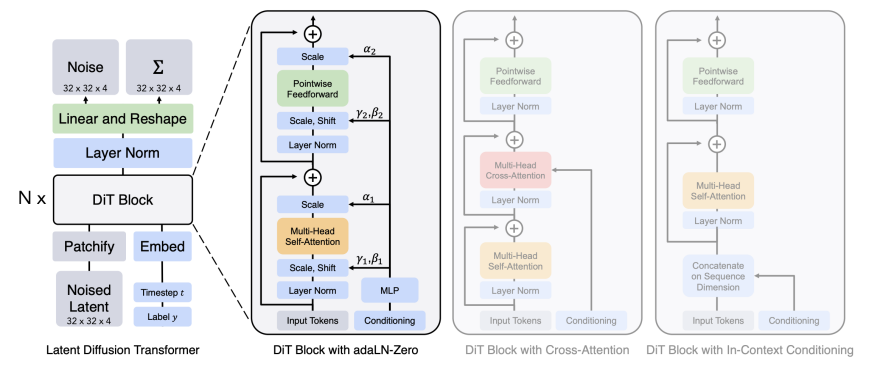
图片来源:《Scalable Diffusion Models with Transformers》
Efficient Training for DiT
接下来介绍几个高效训练DiT的算法,即PixArt家族和SANA。
PixArt-\(\alpha\)
Efficient T2I Transformer
- 引入交叉注意力,采用0初始化
- 引入 AdaLN-single,减少参数量
- g(·)是相加操作,为了兼容预训练的权重,E被特定初始化;初始化的 E 能使参数与 DiT 在 t=500 时相同
Dataset Construction
- 选择 LAION,SAM 作为 base,利用 LLaVA 对其进行精细描述
- 用 JourneyDB 和 10M internal dataset 作为第三阶段的高质量美观数据
Training strategy decomposition (3-stage)
- 从 class-guided 模型(DiT)初始化ImageNet训练得来的参数
- 构建信息密集的数据集,模型训练起来能学到更多信息,收敛更快;
- 利用高质量、美观的数据集进行 fine-tune;JourneyDB和10M internal dataset提升模型审美。
PixArt-\(\Sigma\)
Dataset
- 构建数据集共33M张图片,其中8M张4K图片
- 用Share-Captioner代替LLaVA生成更加准确和细致的描述;描述的平均长度提升到180,text encoder处理长度从120扩展至300
- 构建了30,000张高质量图片用于评估
KV-Compression
- deep layer中,在attention运算之前对key和value压缩成更小的feature。
- PixArt-Σ采用步长为2的\(R \times R\)卷积核的卷积操作,kernel权重初始化为\(1/R^2\)。
- 复杂度从\(O(N^2)\)变为\(O(N^2/R^2)\)
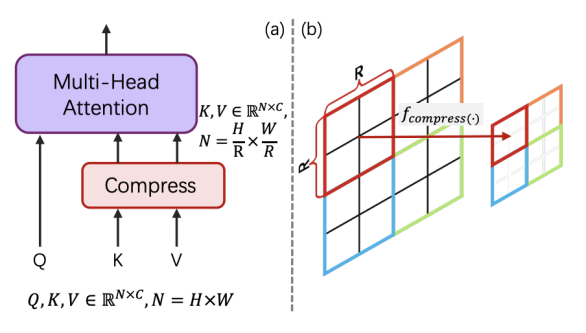
图片来源:《PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation》
Weak-to-Strong Training Strategy
(a) 换成了SDXL’s VAE,SDXL的VAE使用了更大的training batch size(256)
(b) 应用PE Interpolation:高分辨率(HR)的初始PE通过低分辨率(LR)的PE,也就是pixart-alpha权重插值而来,收敛速度加快
(c) 在KV compress时应用类似avg pooling的初始化
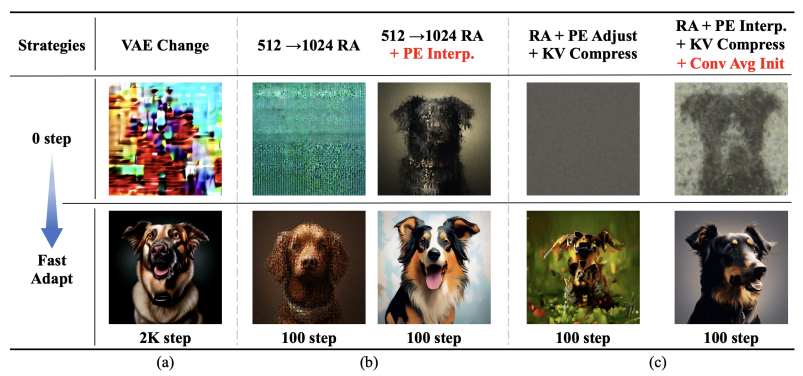
图片来源:《PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation》
SANA
Model
- autoencoder从8x压缩换成了32x压缩:motivation高分辨率图片必然有更多的冗余,应用AE-F32C32P1,token只剩1/4
- 使用Linear DiT(自注意力变为线性注意力,softmax改为ReLU),其中复杂度从O(N^2)变为O(N);由于没有非线性变换,引入Mix-FFN(SiLU: \(x*sig(x)\));由于Mix-FFN的3*3卷积可以融入位置信息,去掉PE
- decoger-only一般被认为有更强的推理能力,本文使用Gemma-2,并且设计了复杂的指令(通过LLM的in-context learning, ICL生成complex human instruction, CHI训练)来提高LLM的理解能力
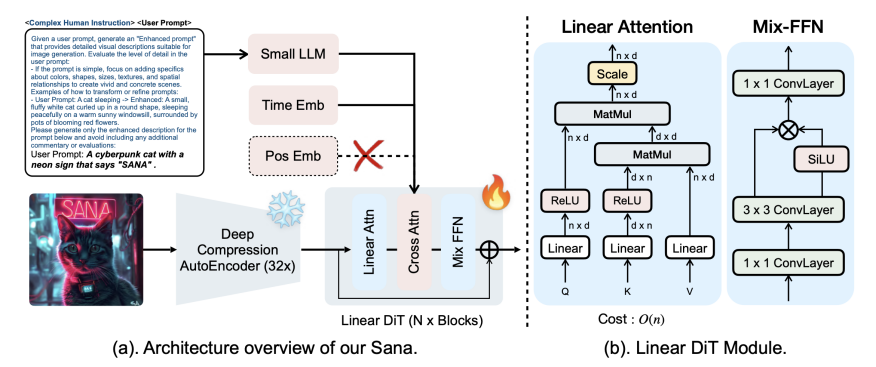
图片来源:《SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers》
Efficient Training/Inference
- 利用多个VLM重新生成image caption
- 基于CLIP分数的训练策略,动态选择高CLIP分数的caption
- 使用Flow-DPM-Solver[1]将推理采样步骤从28-50步减少到14-20步
DPM-Solver基于DDPM连续近似为SDE,去掉扰动,引入速度场变为ODE;利用高阶方法(一般是三阶)快速收敛。 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号