Hadoop 集群模式安装 配置
安装Hadoop前置,当前是要准备好基础运行环境,这里我们准备了三台虚机,详见上篇博文
一、 准备上传工具
要安装hadoop相关软件 ,需要将对应的安装包上传到这些虚机服务器(vm centos)上
安装上传下载工具包rz及sz,查看下当前机子上是否有安装包
输入yum provides */rz

安装rz
安装好后,在Xshell端输入rz,在弹出窗口中选择上传文件:hadoop安装包hadoop-2.7.3.tar.gz
当然前提是提前本地下载好对应版本安装包,这里版本是2.7.3
二、 安装hadoop
1、为了统一,我们将hadoop作为程序软件安装在opt目录 下
给hadoop用户 opt目录操作权限 chmod –R 777 /opt

安装hadoop

在安装目录下,新建dfs与tmp目录
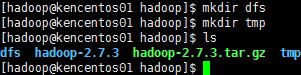
2、检查与配置java环境变量与路径,若已配好,这步可略


配置完成后,让其立即生效

注:上面是使用系统自带的java版本,考虑到所需包的完整性,可以卸载掉后自己重新下载安装
3、配置hadoop环境变量 /etc/profile
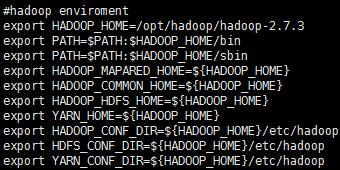
4、修改Hadoop中java 环境变量
$HADOOP_HOME/etc/hadoop/hadoop-env.sh
#export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.131.x86_64
$HADOOP_HOME/etc/hadoop/yarn-env.sh
#export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.131.x86_64
5、指定从服务器
更改$HADOOP_HOME/etc/hadoop/slaves
增加两个从服务器的主机名,这里是kencentos02,03

6、配置core-site.xml
$HADOOP_HOME/etc/hadoop/core-site.xml
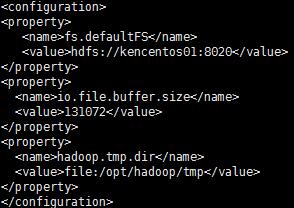
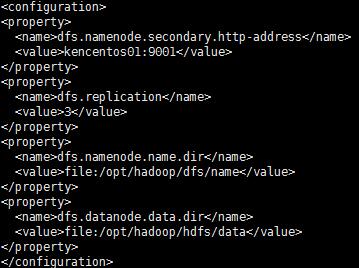
7、 配置hdfs-site.xml
$HADOOP_HOME/etc/hadoop/hdfs-site.xml
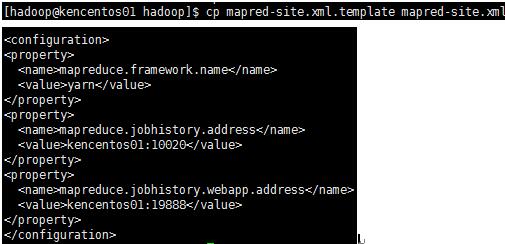
8、配置 mapred-site.xml
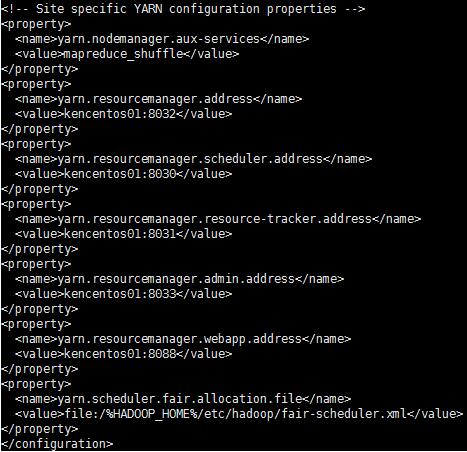
9、配置 yarn-site.xml
10、复制hadoop及相关配置文件到从服务器上
[hadoop@kencentos01 hadoop]$ scp -r /opt/hadoop hadoop@kencentos02:/opt
[hadoop@kencentos01 hadoop]$ scp -r /opt/hadoop hadoop@kencentos03:/opt
11、分别更改centos02,03上的环境变量
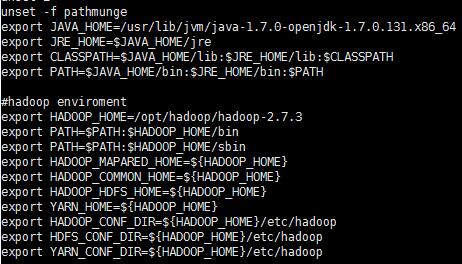
12.启动hadoop
格式化namenode
hdfs namenode –format
启动守护进程
方法一: /hadoop/hadoop-2.7.3/sbin/start-all.sh
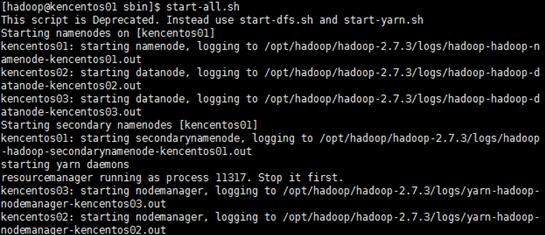
方法二:
启动NameNode和DataNode
$ start-dfs.sh
启动ResourceManager 和 NodeManager 守护进程
$ start-yarn.sh
停止命令
/hadoop/hadoop-2.7.3/sbin/stop-all.sh
$stop-dfs.sh
$stop-yarn.sh
启动节点还可以用下面命令
hadoop-daemon.sh start namenode
Hadoop-daemon.sh start datanode
执行jps命令
jps 可以查看 hadoop 上 当前运行的java 进程
(不是hadoop的什么命令,是java的命令,所以直接执行就行了)

13、查看节点是否正常
访问50070端口 ,我这里是http://192.168.52.128:50070
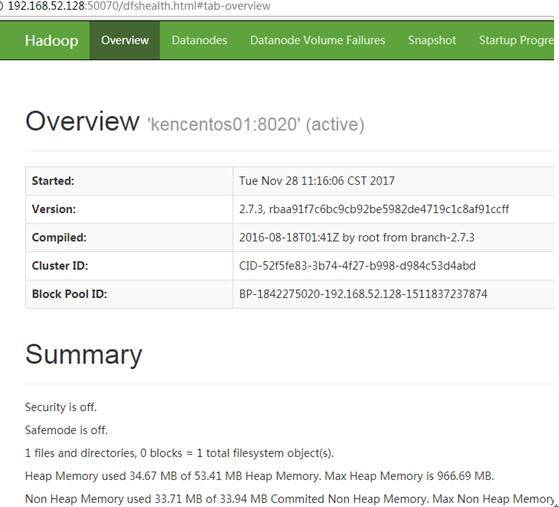
若不能正常显示,则可能是节点未正常启动
我遇到的是因为namenode二次format时导致VERSION中的clusterID 冲突问题
解决方法:将dfs对应的data,tmp目录下文件都删除,重新format下
再启动服务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号