

一个程序是如何构建的
程序的一生
1.程序的组成
每个程序其实都是由文件组成的,可以是一个也可以是多个。
其实一个文件所组成的程序很简单(一般来说),也就是我们在初学时做的编程题,
写一下
sum.cpp
#include<stdio.h>
int main(){
int a = 0, b = 0;
scanf("%d %d",&a,&b);
printf("sum = %d",a+b);
return 0;
}
但是一个cpp文件时远远不够滴
-
在dev cpp中你觉得写了一个cpp文件,这个程序就能运行了,那是因为IDE(Integrated Development Environment)帮你做好了预处理,编译,汇编,链接这一系列工作。
-
以Linux系统下为例子,你写的.cpp文件变成可以用的程序要经历这样的过程
.cpp -> .i -> .s -> .o -> .out 箭头上分别为预处理,编译,汇编,链接
最终变成了可以使用的可执行文件(.out)(windows系统下是.exe) -
首先说明一点,程序对应的是一个逻辑模型或者说是概念,而文件是构成程序的实体。
换言讲,文件是真实存在的,至少你可以在你的电脑上找到对应的可执行文件,但是程序是不存在的或者是抽象的,你没办法在你的电脑上找到一个程序。
但是当一个个的文件进行打包,变成一个整体时,你就得到了一个程序,可以说程序是一系列文件的总称。让我们回归正题,对于由一个文件组成的程序来说,构建以及后续的更改是十分简单的,但是对于多个文件构成的程序来说则需要对文件进行有效地组织。
2.多文件程序
要讲多文件程序,从OOP(面向对象编程)切入最好的。我们知道在面向对象编程的过程中,类是要声明在头文件中的,而类中方法的实现是要单独声明在另一个.cpp文件中的,而创建类,以及调用类中方法的代码是要放在另一个.cpp文件中(因为这个main函数在这个文件中,下文则称该文件为main.cpp,以便于与另一个.cpp文件区分开来)。
做个小总结并给个小例子
- .h文件负责类成员的定义(属性和方法)
写一个栈的类做个例子
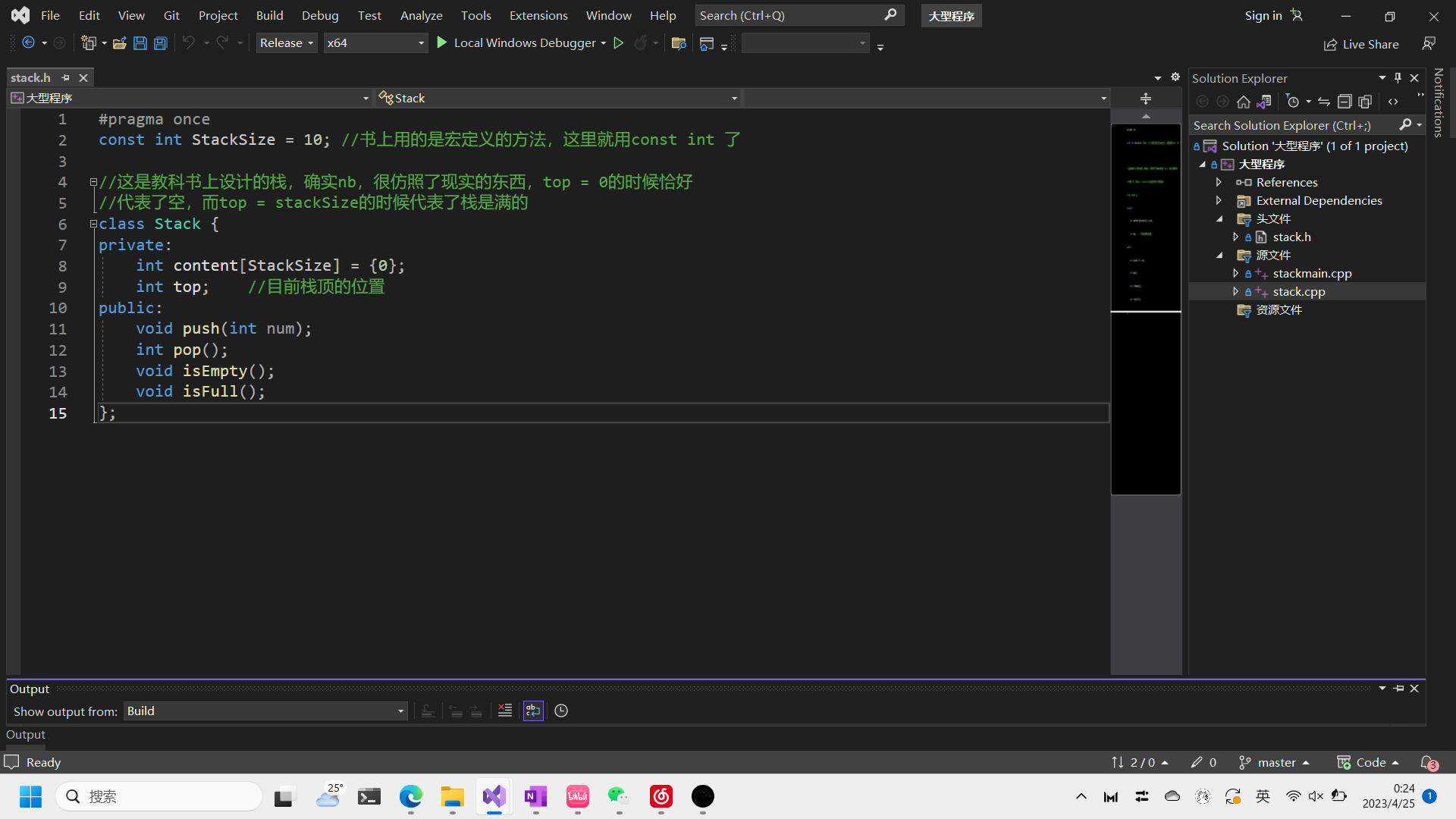
- .cpp文件负责类中成员函数(方法)的实现
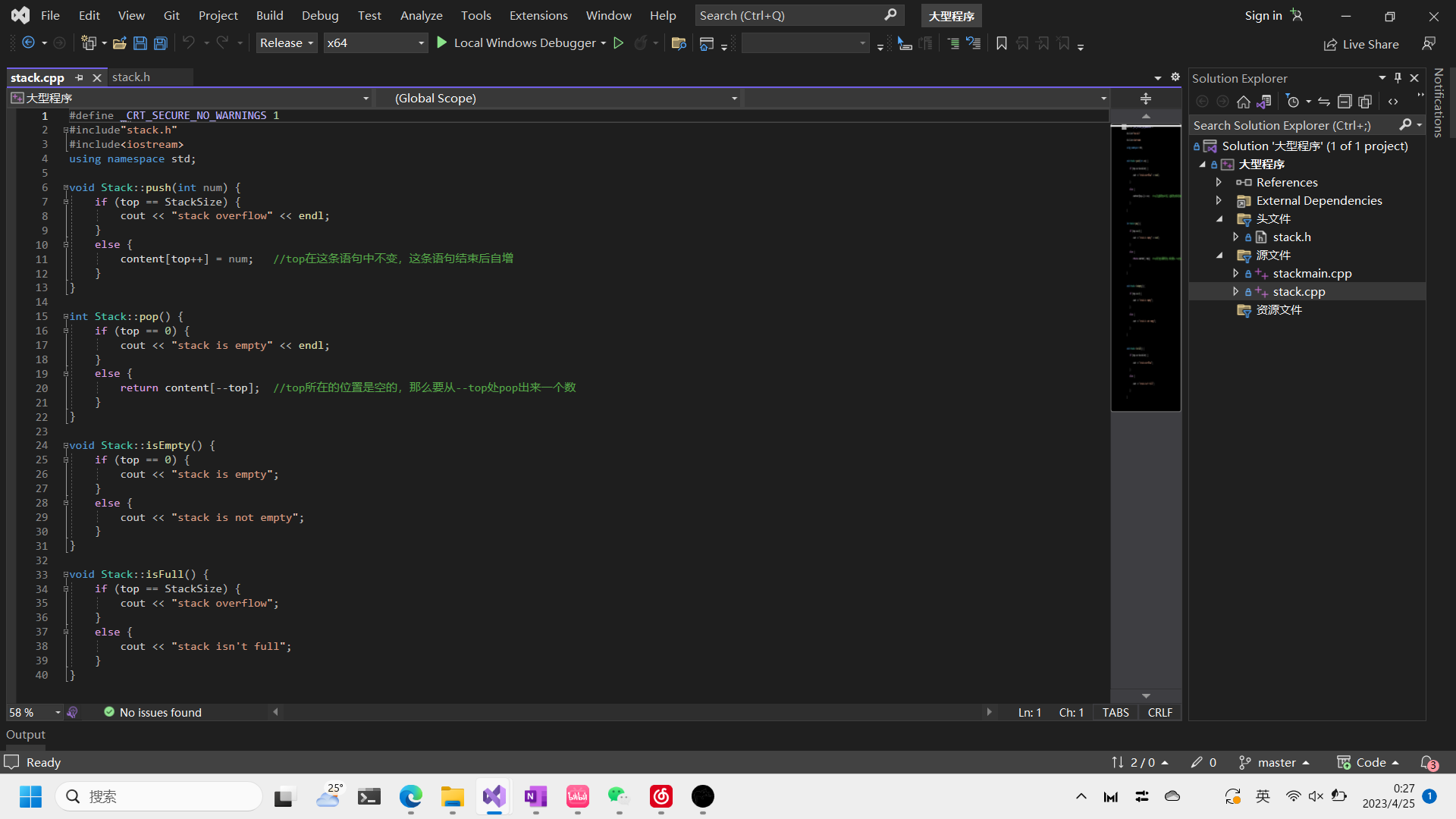
- .cppmain文件负责类的创建以及类中方法的使用
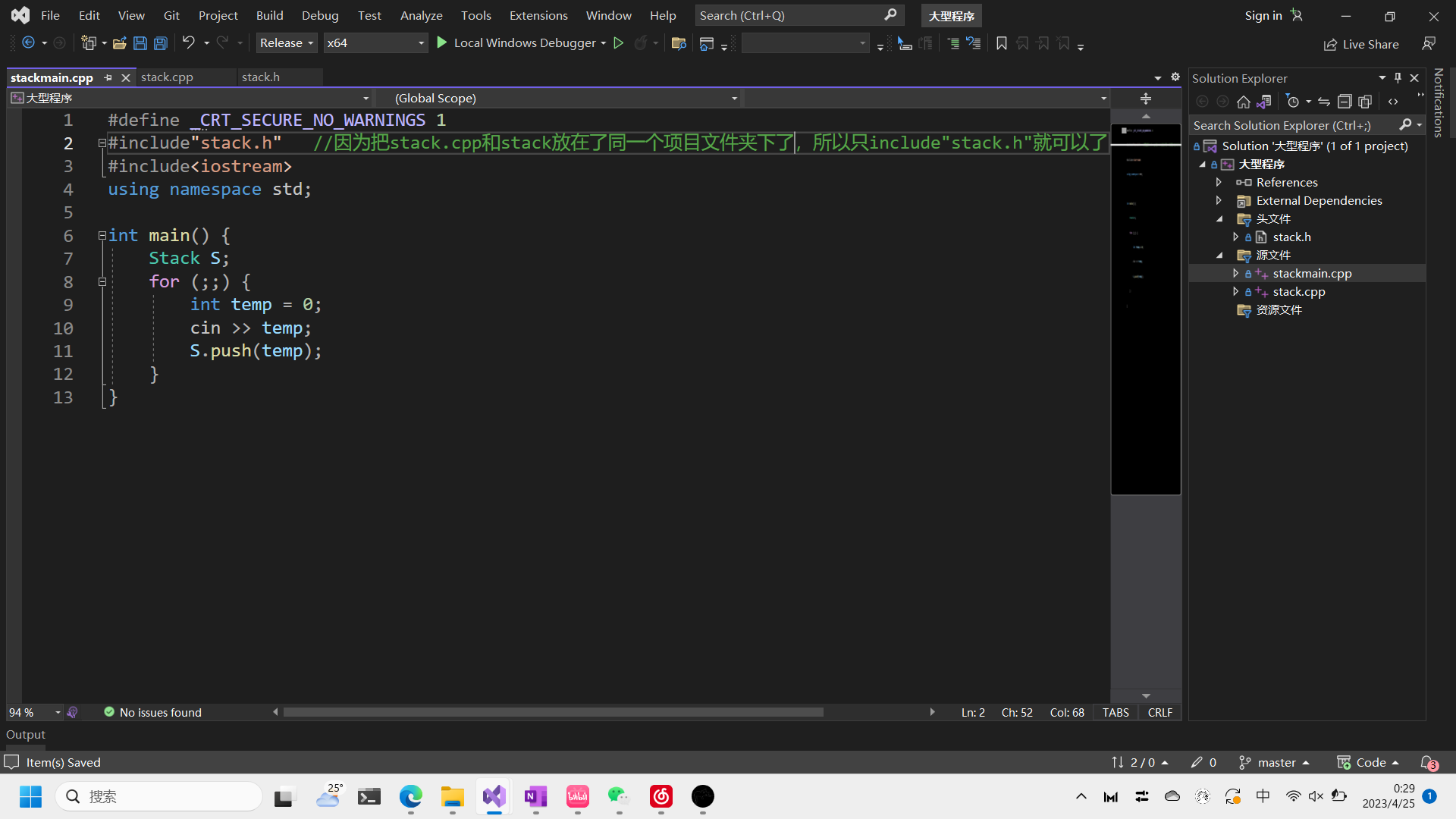
这是最简单,也是最常用的OOP的程序结构。
我们尝试解析一下,为什么要这样(多文件 并且 声明,实现,使用三者分离)去构建一个程序。
-
代码的复用性
程序采取这样的结构进行开发来说,代码的复用性是很高的。就对我举的例子的来说,栈是一种很基础的数据结构,并且不同程序之间对栈的要求差异是不大的。那么当我开发另一个程序或者同一个程序的另一个部分来说,我之前写的Stack类依旧可以发光发热,而不是使用过一遍后就被打入冷宫。这样的做法极大地提升了开发的效率,简言之,这样干是很省力的(项目越大,越到项目的后期就越省力)。 -
程序迭代(修改)起来更加方便
还记得我们在上面提过的.cpp文件是如何变为.out文件的么?
预处理,编译,汇编,链接
我们不去关注预处理和汇编两步,仅将这个过程简化为编译,链接(将n个源文件所产生的n个.o文件组织起来)当我们想对程序进行迭代的时候,肯定是对源文件进行修改
如果一个大型程序(几百M甚至几个G)仅有一个源文件。尽管省去了链接这个过程,但是对于它的修改是非常痛苦的。
因为如果我们只是修改一行代码,这就意味着整个程序需要重新进行编译。你想一下几百M的文件,就因为修改一行代码就要重新编译一遍(几百M的文件编译一遍是耗时的,而且容易卡死),那谁还敢改代码。但当我们将一个大型程序拆分成若干个文件,当我们想要修改这个程序的时候,就可以只修改对应代码所在的文件,而这个文件经过重新编译后,将它与其它文件的编译版本链接一下就可以了。
由于Linux和Unix系统具有make程序,可以跟踪程序依赖的文件以及这些文件的最后修改时间。当运行make时,如果它检测到上次编译后修改了源文件,make将记住重新构建程序所需的步骤。所以只要链接过一次,再次链接将会很快。 -
代码的保密性
当方法的声明文件与方法的实现文件相分离时,对于代码的提供者来说,他对代码有着更好的掌控。他可以只去公开.h文件而不去公布具体的实现文件。
上述三点是我们为什么要去用多文件去实现一个程序,至于如何去实现的细节,则在下篇文章去谈

 浙公网安备 33010602011771号
浙公网安备 33010602011771号