
人体姿态估计学习-2D系列-CPM
基于热力图的,2D,单人的(可应用到多人),自底向上
摘要:
姿态机为学习丰富的隐式空间模型提供了一个顺序预测框架。在这项工作中,我们展示了一个系统的设计,如何将卷积网络整合到姿态机框架中,用于学习图像特征和用于姿态估计任务的图像依赖空间模型。本文的贡献在于对结构化预测任务(如关节姿态估计)中变量之间的长期依赖关系进行隐式建模。我们通过设计一个由卷积网络组成的顺序体系结构来实现这一目标,该体系结构直接操作先前阶段的置信图,产生越来越精确的零件位置估计,而不需要显式的图形模型风格推断。我们的方法通过提供一个自然的学习目标函数来加强中间监督,从而补充反向传播的梯度并调节学习过程,从而解决了训练过程中梯度消失的特征困难。我们展示了最先进的性能,并在包括mpii, lsp和lic数据集在内的标准基准测试中优于竞争方法。
文章解决的问题:
将卷积神经网络融合传统的姿态机,不再需要显示先验的设计,实现了一个隐式的空间模型的端到端的序列化预测模型。(感觉没解决什么新问题,只是提出新结构的方法)
网络结构:
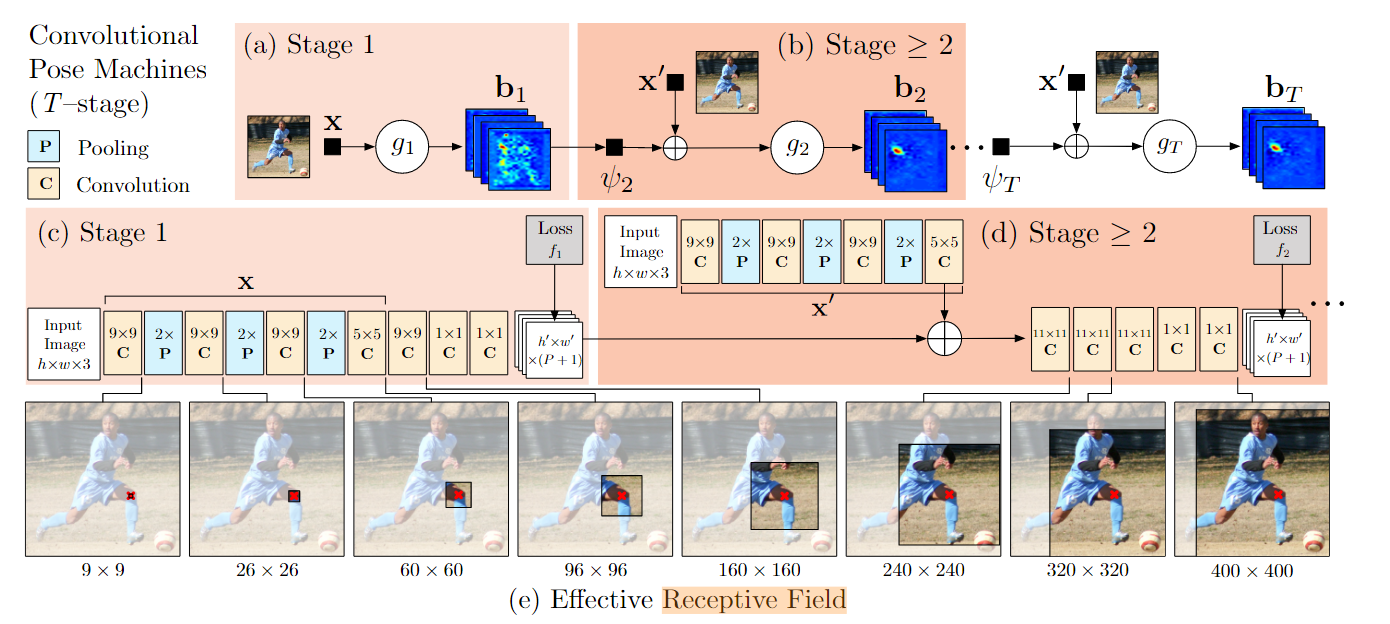
输入一个图片,然后输出n张n个关节的belief map(这个,我看图的感觉就是热力图呀),在stage1输出的过程中,其关节部分的感受野会不断的增大,也就是获取各个关节之间的联系(这一点后文中有提到随着感受野的增大,准确率也随之增加,到能完整包括一个人后再增加就趋于饱和了,符合目的。)至于stage2则是将阶段一的结果和原图一起作为输入,看图这里应该是加法,也就是增加维度,后续的阶段则是利用stage2中输入图片的特征,加上各个阶段的前一阶段的输出。
这里为什么不用阶段一的特征?
主要是卷积的过程有变化,文中提到了二阶段需要尽可能的提高感受野来增强其上下文能力
额,上面说的不对,看了下图好像是一样的,那可能都行,不太确定。
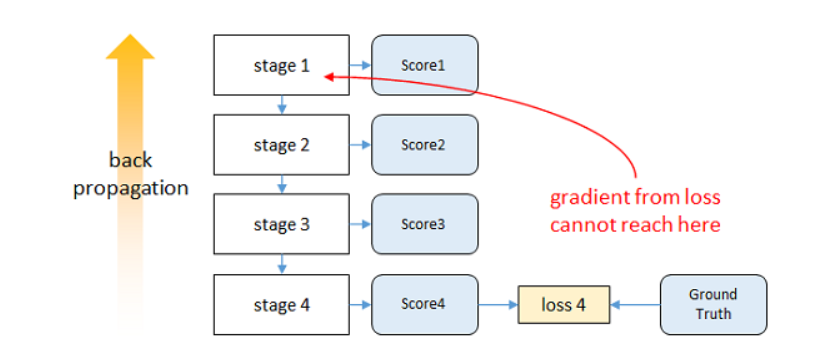
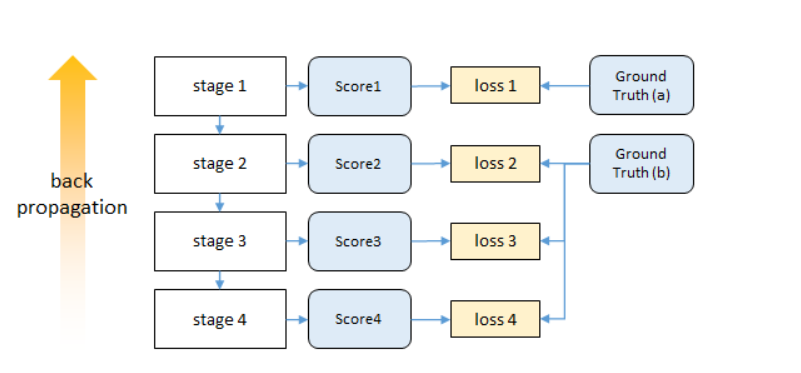
这篇论文还有一点就是监督了,就是反向传播的过程中,越靠近输入损失就越小,而采用中间监督,也就是每个阶段都计算损失,就可以避免这种问题。
最后,这篇文章读的不是太细,没看代码理解还是不太深,关于多人的要加入center map这部分,不是很懂,就略过了,用AI解答一下,大致如下:
在多人姿态估计的任务中,当一张图片中包含多个人物时,为了区分并分别估计每个人的姿态,通常需要为每个人定义一个区域或者标识,这样网络才能针对每个个体进行姿态预测。在这里,提到的 center map 就是一个有效的工具,用于帮助网络定位并识别出图片中的不同人物。
center map 实际上是一个二值或连续值的特征图(heatmap),它表示了图片中每个人物中心的响应强度。通常,center map 的生成方法是,在每个人的真实中心位置附近生成一个高斯响应(Gaussian response),这样中心位置的值最高,而离中心越远的位置值逐渐降低。这个高斯响应的大小(即标准差)可以根据人物的尺寸进行调整。
在多人姿态估计的网络中,center map 的作用主要体现在两个方面:
区域定位:由于 center map 为每个人物中心提供了响应强度,网络可以根据这些响应来确定需要关注的区域,进而为每个个体进行姿态估计。
注意力引导:由于 center map 的响应是局部化的(即在每个人物中心位置附近响应最强),它可以引导网络将注意力集中在正确的区域上,避免对背景或其他人物的干扰。
在训练过程中,网络会学习如何从 center map 和原始图像中提取特征,并预测每个人的姿态。在测试时,网络会首先生成 center map(这可能需要一个额外的检测或定位步骤),然后基于 center map 进行姿态估计。
通过这种方式,多人姿态估计问题就被转化为了多个单人姿态估计问题的组合,从而可以自底向上地处理多人姿态问题。这里的“自底向上”指的是,网络首先定位出每个人物的中心位置,然后针对每个位置进行姿态估计,而不是先检测出所有人的姿态,然后再进行匹配和组合。这种方法在处理遮挡和重叠人物时通常更加有效。
参考文章如下:
2D关键点检测之CPM:Convolutional Pose Machines - 凡心所向素履所往的文章 - 知乎
https://zhuanlan.zhihu.com/p/102468356
http://t.csdnimg.cn/tCX9w

 浙公网安备 33010602011771号
浙公网安备 33010602011771号