

软件工程第三天
这是我这次作业的代码已经上传到码云:https://gitee.com/kbfei/query_times/tree/master
2017*****7023
董玉林
第一段是读取文件
def process_file(dst): # 读文件到缓冲区
try: # 打开文件
a = open(dst,"r")
except IOError as s:
print (s)
return None
try: # 读文件到缓冲区
bvffer = a.read()
except:
print ('Read File Error!')
return None
a.close()
return bvffer
第二段计算每个单词出现的次数,并保存
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
for ch in'"!?;,."':
bvffer = bvffer.lower().replace(ch,"")
word = bvffer.strip().split()
for word in word:
word_freq[word] = word_freq.get(word,0)+1
return word_freq
第三段 输出出现最多次数的单词
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
print(item)
第四段main 主函数
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('dst')
args = parser.parse_args()
dst = args.dst
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
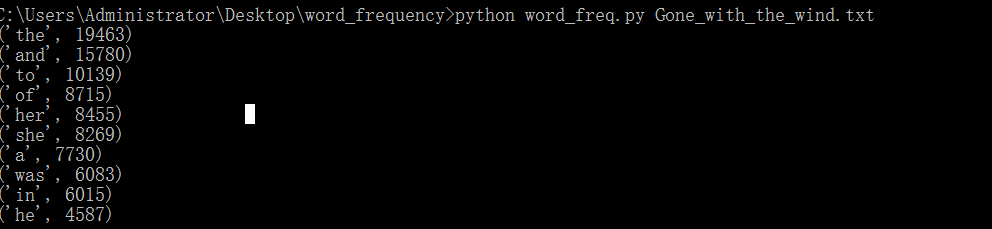
这是单词出现的次数

出现最多的代码

运行时间最长的代码
总结:又让我熟悉了一下查找单词和查看时间的方法,效率是一个工作能力最完美的体现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号