python爬虫:爬取b站热门视频的视频、音频、部分评论和弹幕,并将弹幕进行可视化。
一.选题背景
1.背景:爬虫是从互联网上抓取对于我们有价值的信息。选择此题正是因为随着信息化的发展,大数据时代对信息的采需求和集量越来越大,相应的处理量也越来越大,正是因为如此,爬虫相应的岗位也开始增多,因此,学好这门课也是为将来就业打下扎实的基础。bilibili在当今众多视频网站中,有许多年轻人都在使用这个软件,通过爬取其中热门视频的弹幕可以了解最近年轻人都在看些什么,可以进一步了解现阶段年轻人的观看喜好。
2.预期目标:爬取这个视频的视频、音频、评论和弹幕,并将弹幕可视化之后再进行数据清理和持久化保持。
二.主题式网络爬虫设计方案
1.主题式网络爬虫名称:
爬取b站热门视频的视频、音频、一部分评论和弹幕
2.主题式网络爬虫爬取的内容与数据特征分析
内容:爬取b站热门视频的视频、音频、一部分评论和弹幕,并将弹幕进行可视化
特征分析:对弹幕进行计数,然后进行可视化
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
思路:爬取弹幕,计算次数,进行可视化。
难点:进行可视化会出现错误
三、主题页面的结构特征分析
1.主题页面的结构与特征分析

2.Htmls 页面解析
3.节点(标签)查找方法与遍历方法(必要时画出节点树结构)
遍历方法:(1)遍历输出内容并保存到文件
(2)统计词频
(3)进行情感极性分析,并统计不同情感类别的弹幕数量
(4)去除重复弹幕
四、网络爬虫程序设计
(一).爬取视频和音频
1.导入库
1 # 导入requests库,用于发送HTTP请求 2 3 import requests 4 5 # 导入re库,用于正则表达式操作 6 7 import re 8 9 # 导入json库,用于处理JSON数据 10 11 import json 12 13 # 导入pprint模块,用于美化输出 14 15 from pprint import pprint
2.确定请求url地址
1 url = 'https://www.bilibili.com/video/BV1gN411C7Dn'
3.防伪
1 # 把python代码伪装成浏览器 2 3 headers = { 4 5 # 设置请求头Referer字段 6 7 'Referer': 'https://www.bilibili.com/video/', 8 9 # 浏览器基本身份标识 10 11 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.199.400 QQBrowser/11.8.5300.400' 12 13 }
4.提取视频和音频
1 # 发送请求 2 3 response = requests.get(url=url, headers=headers) 4 5 # 获取标题 6 7 title = re.findall('"title":"(.*?)","pubdate"', response.text)[0] 8 9 # 获取视频数据信息 10 11 html_data = re.findall('<script>window.__playinfo__=(.*?)</script>', response.text)[0] 12 13 json_data = json.loads(html_data) 14 15 # 获取音频的二进制 16 17 audio_url = json_data['data']['dash']['audio'][0]['baseUrl'] 18 19 # 获取视频的二进制 20 21 video_url = json_data['data']['dash']['video'][0]['baseUrl'] 22 23 print(title) 24 25 print(audio_url) 26 27 print(video_url) 28 29 # 获取音频内容 30 31 audio_content = requests.get(url=audio_url, headers=headers).content 32 33 # 获取视频内容 34 35 video_content = requests.get(url=video_url, headers=headers).content 36 37 # 保存音频内容 38 39 with open('video\\' + title + '.mp3', mode='wb') as audio: 40 audio.write(audio_content) 41 42 # 保存视频内容 43 44 with open('video\\' + title + '.mp4', mode='wb') as video: 45 video.write(video_content) 46 # 获取音频内容以及视频画面内容

(二).爬取一部分评论
1.导入库
1 # 导入时间模块 2 3 import time 4 5 # 导入请求模块 6 7 import requests 8 9 # 导入re模块,用于正则表达式匹配 10 11 import re
2.设置循环执行次数
1 # 循环执行10次 2 3 for page in range(1, 11): 4 # 每次循环暂停1秒 5 6 time.sleep(1)
3.确定请求url地址
1 # 评论接口的URL 2 3 url = f'https://api.bilibili.com/x/v2/reply/main?csrf=a52df2167caabb4b136e5a176129e6e1&mode=3&oid=486825901&pagination_str=%7B%22offset%22:%22%7B%5C%22type%5C%22:1,%5C%22direction%5C%22:1,%5C%22data%5C%22:%7B%5C%22pn%5C%22:2%7D%7D%22%7D&plat=1&type=1' 4 5 # 请求头信息 6 7 headers = { 8 9 'cookie': 'buvid3=B0EB5F80-D2B0-14A3-EB3A-87CFA804787250106infoc; b_nut=1685541450; i-wanna-go-back=-1; _uuid=1098D47DD-3A9C-EE54-410C9-3B83B2781A9650989infoc; FEED_LIVE_VERSION=V8; home_feed_column=5; nostalgia_conf=-1; CURRENT_FNVAL=4048; rpdid=|(u)lu|k)uR|0J\'uY)llRuR~u; header_theme_version=CLOSE; browser_resolution=1492-728; SESSDATA=6bf2b085%2C1701519221%2C8f4aa%2A61; bili_jct=a52df2167caabb4b136e5a176129e6e1; DedeUserID=404298709; DedeUserID__ckMd5=5ad8c592423d2b17; PVID=1; fingerprint=99c2f32d86e8c07d1ade297f990f81d8; buvid_fp_plain=undefined; b_ut=5; b_lsid=DDE53241_1888F81F06B; bsource=search_sougo; buvid4=8AE136D9-03A8-2D62-E8CA-A1EB8746EBD551924-023053121-+9JvYED62PxRAFmHznBmEg%3D%3D; sid=ousk7to2; buvid_fp=B0EB5F80-D2B0-14A3-EB3A-87CFA804787250106infoc', 10 11 'origin': 'https://www.bilibili.com', 12 13 'referer': 'https://www.bilibili.com/video/', 14 15 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.199.400 QQBrowser/11.8.5300.400' 16 }
4.爬取部分评论
1 # 发送请求 2 3 response = requests.get(url=url, headers=headers) 4 5 # 从响应中提取评论内容 6 7 content_list = [i['content']['message'] for i in response.json()['data']['replies']] 8 9 # 打印评论内容列表 10 11 print(content_list) 12 13 # 遍历输出内容 14 15 for content in content_list: 16 with open('评论数据.txt', mode='a', encoding='utf-8') as f: 17 18 # 将评论内容写入文本文件 19 20 f.write(content) 21 22 # 写入换行符,以便每条评论占一行 23 24 f.write('\n') 25 26 # 打印每条评论内容 27 28 print(content)

(三).爬取弹幕
1.导入库
1 # 导入requests库,用于发送HTTP请求 2 import requests 3 # 导入re库,用于正则表达式匹配 4 import re 5 # 导入font_manager模块,用于设置字体 6 from matplotlib import font_manager 7 # 导入matplotlib.pyplot模块,用于绘图 8 import matplotlib.pyplot as plt 9 # 导入Counter类,用于统计词频 10 from collections import Counter 11 # 导入seaborn库,用于绘制统计图表 12 import seaborn as sns 13 # 导入WordCloud类,用于生成词云图 14 from wordcloud import WordCloud
2.设置字体
1 # 设置全局字体 2 my_font=font_manager.FontProperties(fname="C:\Windows\Fonts\STSONG.TTF") 3 plt.rcParams['font.family'] = 'STSong' 4 # 替换成所选的中文字体
3.确定url和防伪
1 # 发送HTTP请求,获取弹幕数据的URL,并使用requests库发送GET请求获取响应 2 3 url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=1150981775' 4 5 headers = { 6 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.37' 7 }
4.爬取弹幕
1 # 发送GET请求获取响应 2 response = requests.get(url=url, headers=headers) 3 # 设置响应的编码方式为UTF-8,以解决乱码问题。 4 response.encoding = 'utf-8' 5 # 获取数据 6 data = response.text 7 8 # 解析数据 9 content_list = re.findall('<d p=".*?">(.*?)</d>', data) 10 11 12 # 遍历输出内容并保存到文件 13 with open('弹幕.txt', mode='w', encoding='utf-8') as f: 14 for content in content_list: 15 f.write(content) 16 f.write('\n') 17 print(content)
5.生产词云图并保持
1 # 将弹幕内容列表转换为字符串 2 text = ' '.join(content_list) 3 # 使用WordCloud库生成词云对象 4 wordcloud = WordCloud(font_path='C:\Windows\Fonts\msyh.ttc').generate(text) 5 6 # 将弹幕内容列表转换为字符串,并使用WordCloud库生成词云对象。 7 plt.imshow(wordcloud, interpolation='bilinear') 8 plt.axis('off') 9 # 保存词云图 10 plt.savefig('词云图.png') 11 plt.show()

6.统计词频
1 # 使用Counter类统计词频 2 word_counts = Counter(content_list) 3 # 获取词频最高的前10个词 4 top_words = word_counts.most_common(10) 5 # 获取词频最高的词的标签 6 top_words_labels = [word[0] for word in top_words] 7 # 获取词频最高的词的计数 8 top_words_counts = [word[1] for word in top_words]
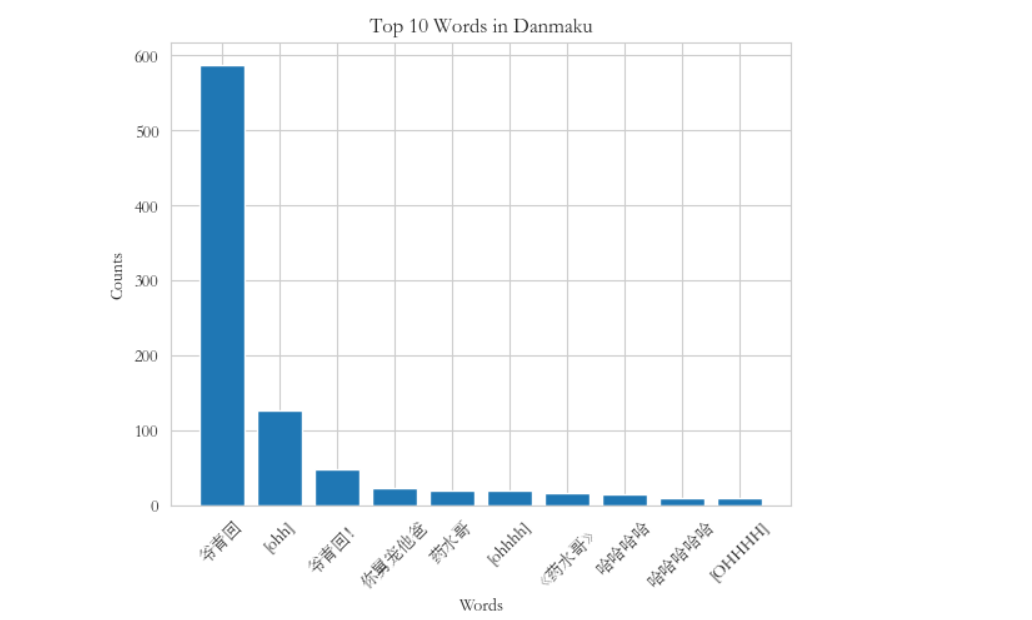
7.生成柱状图并保存
1 # 生成柱状图 2 plt.bar(top_words_labels, top_words_counts) 3 plt.xlabel('Words') 4 plt.ylabel('Counts') 5 plt.title('Top 10 Words in Danmaku') 6 plt.xticks(rotation=45) 7 # 保存柱状图 8 plt.savefig('柱状图.png') 9 plt.show()
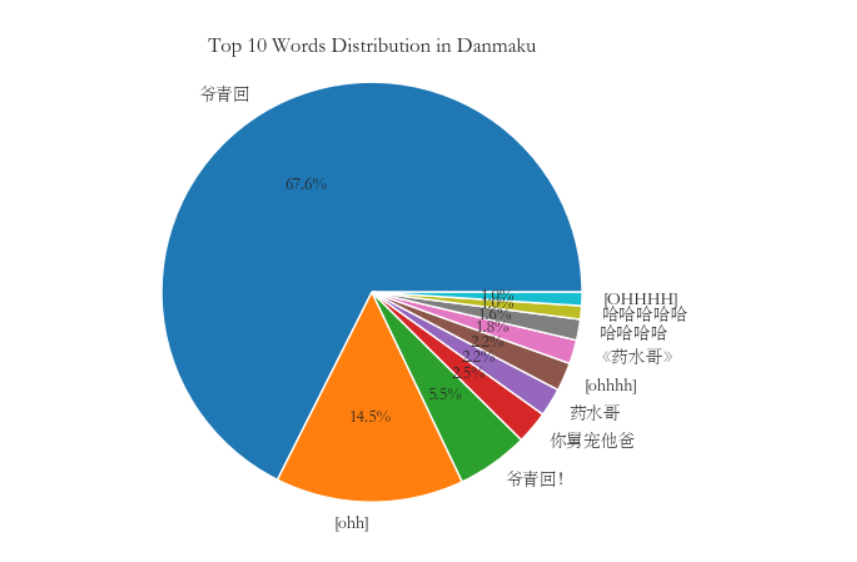
8.生成饼图并保存
1 # 生成饼图 2 labels = top_words_labels 3 sizes = top_words_counts 4 plt.pie(sizes, labels=labels, autopct='%1.1f%%') 5 plt.title('Top 10 Words Distribution in Danmaku') 6 plt.axis('equal') 7 # 保存饼图 8 plt.savefig('饼图.png') 9 plt.show()
9.生成折线图并保存
1 # 生成折线图 2 x_values = range(1, len(top_words_labels) + 1) 3 plt.plot(x_values, top_words_counts, marker='o') 4 plt.xlabel('Words') 5 plt.ylabel('Counts') 6 plt.title('Top 10 Words in Danmaku') 7 plt.xticks(x_values, top_words_labels, rotation=45) 8 # 保存折线图 9 plt.savefig('折线图.png') 10 plt.show()

10.生成漏斗图并保存
1 # 生成漏斗图 2 sns.set_style("whitegrid") 3 plt.figure(figsize=(8, 6)) 4 plt.title("Top 10 Words Funnel",fontproperties=my_font) 5 sns.barplot(x=top_words_counts, y=top_words_labels, palette="Blues_r") 6 plt.xlabel("Counts") 7 plt.ylabel("Words") 8 # 保存漏斗图 9 plt.savefig('漏斗图.png') 10 plt.show()

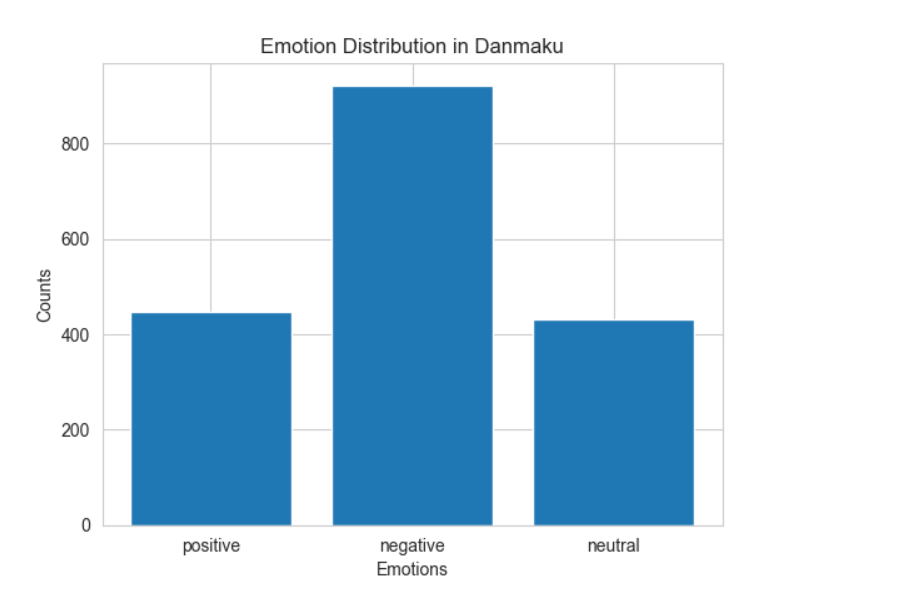
11.进行情感极性分析,并统计不同情感类别的弹幕数量
1 # 进行情感极性分析,并统计不同情感类别的弹幕数量 2 emotions = { 3 'positive': 0, 4 'negative': 0, 5 'neutral': 0 6 } 7 8 for item in content_list: 9 if SnowNLP(item).sentiments > 0.6: 10 emotions['positive'] += 1 11 elif SnowNLP(item).sentiments < 0.4: 12 emotions['negative'] += 1 13 else: 14 emotions['neutral'] += 1 15 16 # 生成柱状图 17 plt.bar(emotions.keys(), emotions.values()) 18 plt.xlabel('Emotions') 19 plt.ylabel('Counts') 20 plt.title('Emotion Distribution in Danmaku') 21 # 保存情感极性分析 22 plt.savefig('情感极性分析.png') 23 plt.show()
12.进行数据清洗
1 # 去除重复弹幕 2 content_list = list(set(content_list)) 3 # 遍历输出清理后的内容并保存到文件 4 with open('弹幕.0.txt', mode='w', encoding='utf-8') as f: 5 for content in content_list: 6 f.write(content) 7 f.write('\n') 8 print(content)

13.总代码
(1)爬取视频和音频
1 # 导入requests库,用于发送HTTP请求 2 3 import requests 4 5 # 导入re库,用于正则表达式操作 6 7 import re 8 9 # 导入json库,用于处理JSON数据 10 11 import json 12 13 # 导入pprint模块,用于美化输出 14 15 from pprint import pprint 16 17 # 确定请求url地址 18 19 url = 'https://www.bilibili.com/video/BV1gN411C7Dn' 20 21 # 把python代码伪装成浏览器 22 23 headers = { 24 25 # 设置请求头Referer字段 26 27 'Referer': 'https://www.bilibili.com/video/', 28 29 # 浏览器基本身份标识 30 31 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.199.400 QQBrowser/11.8.5300.400' 32 33 } 34 35 # 发送请求 36 37 response = requests.get(url=url, headers=headers) 38 39 # 获取标题 40 41 title = re.findall('"title":"(.*?)","pubdate"', response.text)[0] 42 43 # 获取视频数据信息 44 45 html_data = re.findall('<script>window.__playinfo__=(.*?)</script>', response.text)[0] 46 47 json_data = json.loads(html_data) 48 49 # 获取音频的二进制 50 51 audio_url = json_data['data']['dash']['audio'][0]['baseUrl'] 52 53 # 获取视频的二进制 54 55 video_url = json_data['data']['dash']['video'][0]['baseUrl'] 56 57 print(title) 58 59 print(audio_url) 60 61 print(video_url) 62 63 # 获取音频内容 64 65 audio_content = requests.get(url=audio_url, headers=headers).content 66 67 # 获取视频内容 68 69 video_content = requests.get(url=video_url, headers=headers).content 70 71 # 保存音频内容 72 73 with open('video\\' + title + '.mp3', mode='wb') as audio: 74 audio.write(audio_content) 75 76 # 保存视频内容 77 78 with open('video\\' + title + '.mp4', mode='wb') as video: 79 video.write(video_content) 80 # 获取音频内容以及视频画面内容
(2)爬取评论
1 # 导入时间模块 2 3 import time 4 5 # 导入请求模块 6 7 import requests 8 9 # 导入re模块,用于正则表达式匹配 10 11 import re 12 13 # 循环执行10次 14 15 for page in range(1, 11): 16 # 每次循环暂停1秒 17 18 time.sleep(1) 19 20 # 评论接口的URL 21 22 url = f'https://api.bilibili.com/x/v2/reply/main?csrf=a52df2167caabb4b136e5a176129e6e1&mode=3&oid=486825901&pagination_str=%7B%22offset%22:%22%7B%5C%22type%5C%22:1,%5C%22direction%5C%22:1,%5C%22data%5C%22:%7B%5C%22pn%5C%22:2%7D%7D%22%7D&plat=1&type=1' 23 24 # 请求头信息 25 26 headers = { 27 28 'cookie': 'buvid3=B0EB5F80-D2B0-14A3-EB3A-87CFA804787250106infoc; b_nut=1685541450; i-wanna-go-back=-1; _uuid=1098D47DD-3A9C-EE54-410C9-3B83B2781A9650989infoc; FEED_LIVE_VERSION=V8; home_feed_column=5; nostalgia_conf=-1; CURRENT_FNVAL=4048; rpdid=|(u)lu|k)uR|0J\'uY)llRuR~u; header_theme_version=CLOSE; browser_resolution=1492-728; SESSDATA=6bf2b085%2C1701519221%2C8f4aa%2A61; bili_jct=a52df2167caabb4b136e5a176129e6e1; DedeUserID=404298709; DedeUserID__ckMd5=5ad8c592423d2b17; PVID=1; fingerprint=99c2f32d86e8c07d1ade297f990f81d8; buvid_fp_plain=undefined; b_ut=5; b_lsid=DDE53241_1888F81F06B; bsource=search_sougo; buvid4=8AE136D9-03A8-2D62-E8CA-A1EB8746EBD551924-023053121-+9JvYED62PxRAFmHznBmEg%3D%3D; sid=ousk7to2; buvid_fp=B0EB5F80-D2B0-14A3-EB3A-87CFA804787250106infoc', 29 30 'origin': 'https://www.bilibili.com', 31 32 'referer': 'https://www.bilibili.com/video/', 33 34 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.199.400 QQBrowser/11.8.5300.400' 35 } 36 # 发送请求 37 38 response = requests.get(url=url, headers=headers) 39 40 # 从响应中提取评论内容 41 42 content_list = [i['content']['message'] for i in response.json()['data']['replies']] 43 44 # 打印评论内容列表 45 46 print(content_list) 47 48 # 遍历输出内容 49 50 for content in content_list: 51 with open('评论数据.txt', mode='a', encoding='utf-8') as f: 52 53 # 将评论内容写入文本文件 54 55 f.write(content) 56 57 # 写入换行符,以便每条评论占一行 58 59 f.write('\n') 60 61 # 打印每条评论内容 62 63 print(content)
(3)爬取弹幕
1 # 导入requests库,用于发送HTTP请求 2 import requests 3 4 # 导入re库,用于正则表达式匹配 5 import re 6 7 # 导入font_manager模块,用于设置字体 8 from matplotlib import font_manager 9 10 # 导入matplotlib.pyplot模块,用于绘图 11 import matplotlib.pyplot as plt 12 13 # 导入Counter类,用于统计词频 14 from collections import Counter 15 16 # 导入seaborn库,用于绘制统计图表 17 import seaborn as sns 18 19 # 导入WordCloud类,用于生成词云图 20 from wordcloud import WordCloud 21 22 # 设置全局字体 23 my_font=font_manager.FontProperties(fname="C:\Windows\Fonts\STSONG.TTF") 24 plt.rcParams['font.family'] = 'STSong' 25 # 替换成所选的中文字体 26 # 发送HTTP请求,获取弹幕数据的URL,并使用requests库发送GET请求获取响应 27 28 url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=1150981775' 29 30 headers = { 31 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.37' 32 } 33 34 # 发送GET请求获取响应 35 response = requests.get(url=url, headers=headers) 36 37 # 设置响应的编码方式为UTF-8,以解决乱码问题。 38 response.encoding = 'utf-8' 39 40 # 获取数据 41 data = response.text 42 43 # 解析数据 44 content_list = re.findall('<d p=".*?">(.*?)</d>', data) 45 46 47 # 遍历输出内容并保存到文件 48 with open('弹幕.txt', mode='w', encoding='utf-8') as f: 49 for content in content_list: 50 f.write(content) 51 f.write('\n') 52 print(content) 53 54 55 # 将弹幕内容列表转换为字符串 56 text = ' '.join(content_list) 57 # 使用WordCloud库生成词云对象 58 wordcloud = WordCloud(font_path='C:\Windows\Fonts\msyh.ttc').generate(text) 59 60 # 将弹幕内容列表转换为字符串,并使用WordCloud库生成词云对象。 61 plt.imshow(wordcloud, interpolation='bilinear') 62 plt.axis('off') 63 64 # 保存词云图 65 plt.savefig('词云图.png') # 保存词云图 66 plt.show() 67 68 # 统计词频 69 70 # 使用Counter类统计词频 71 word_counts = Counter(content_list) 72 73 # 获取词频最高的前10个词 74 top_words = word_counts.most_common(10) 75 76 # 获取词频最高的词的标签 77 top_words_labels = [word[0] for word in top_words] 78 79 # 获取词频最高的词的计数 80 top_words_counts = [word[1] for word in top_words] 81 82 # 生成柱状图 83 plt.bar(top_words_labels, top_words_counts) 84 plt.xlabel('Words') 85 plt.ylabel('Counts') 86 plt.title('Top 10 Words in Danmaku') 87 plt.xticks(rotation=45) 88 89 # 保存柱状图 90 plt.savefig('柱状图.png') 91 plt.show() 92 93 # 生成饼图 94 labels = top_words_labels 95 sizes = top_words_counts 96 plt.pie(sizes, labels=labels, autopct='%1.1f%%') 97 plt.title('Top 10 Words Distribution in Danmaku') 98 plt.axis('equal') 99 100 # 保存饼图 101 plt.savefig('饼图.png') 102 plt.show() 103 104 # 生成折线图 105 x_values = range(1, len(top_words_labels) + 1) 106 plt.plot(x_values, top_words_counts, marker='o') 107 plt.xlabel('Words') 108 plt.ylabel('Counts') 109 plt.title('Top 10 Words in Danmaku') 110 plt.xticks(x_values, top_words_labels, rotation=45) 111 112 # 保存折线图 113 plt.savefig('折线图.png') 114 plt.show() 115 116 # 生成漏斗图 117 sns.set_style("whitegrid") 118 plt.figure(figsize=(8, 6)) 119 plt.title("Top 10 Words Funnel",fontproperties=my_font) 120 sns.barplot(x=top_words_counts, y=top_words_labels, palette="Blues_r") 121 plt.xlabel("Counts") 122 plt.ylabel("Words") 123 124 # 保存漏斗图 125 plt.savefig('漏斗图.png') 126 plt.show() 127 128 # 进行情感极性分析,并统计不同情感类别的弹幕数量 129 emotions = { 130 'positive': 0, 131 'negative': 0, 132 'neutral': 0 133 } 134 135 for item in content_list: 136 if SnowNLP(item).sentiments > 0.6: 137 emotions['positive'] += 1 138 elif SnowNLP(item).sentiments < 0.4: 139 emotions['negative'] += 1 140 else: 141 emotions['neutral'] += 1 142 143 # 生成柱状图 144 plt.bar(emotions.keys(), emotions.values()) 145 plt.xlabel('Emotions') 146 plt.ylabel('Counts') 147 plt.title('Emotion Distribution in Danmaku') 148 149 # 保存情感极性分析 150 plt.savefig('情感极性分析.png') 151 plt.show() 152 153 154 # 去除重复弹幕 155 content_list = list(set(content_list)) 156 157 # 遍历输出清理后的内容并保存到文件 158 with open('弹幕.0.txt', mode='w', encoding='utf-8') as f: 159 for content in content_list: 160 f.write(content) 161 f.write('\n') 162 print(content)
五、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
在这个视频中除了哈哈哈,爷青回占比最多。爷青回的意思是爷的青春回来了。说明当代年轻人想要找回之前的热血和热情,想要看以前的视频。
有达到预期目标
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
我知道了,跟多的代码,复习了以前的代码,也知道了自己的不足。要完善自己的不足

 浙公网安备 33010602011771号
浙公网安备 33010602011771号