k8s学习笔记7——HPA
Horizontal Pod Autoscaler (HPA)控制器
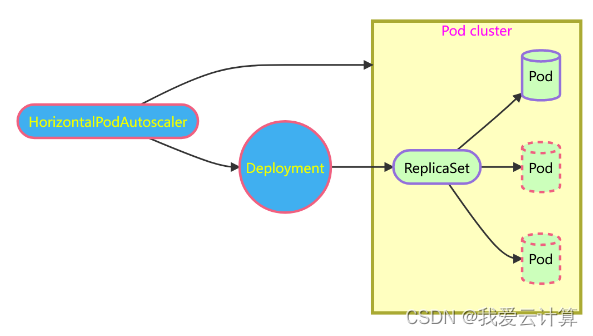
总的来说弹性伸缩应该包括:
- Cluster-Autoscale: 集群容量(node数量)自动伸缩,跟自动化部署相关的,依赖iaas的弹性伸缩,主要用于虚拟机容器集群
- Vertical Pod Autoscaler: 工作负载Pod垂直(资源配置)自动伸缩,如自动计算或调整deployment的Pod模板limit/request,依赖业务历史负载指标
- Horizontal-Pod-Autoscaler: 工作负载Pod水平自动伸缩,如自动scale deployment的replicas,依赖业务实时负载指标
其中VPA和HPA都是从业务负载角度从发的优化,VPA是解决资源配额(Pod的CPU、内存的limit/request)评估不准的问题,HPA则要解决的是业务负载压力波动很大,需要人工根据监控报警来不断调整副本数的问题,有了HPA后,被关联上HPA的deployment,后续副本数修改就不用人工管理,HPA controller将会根据业务忙闲情况自动帮你动态调整。
1)创建被监控的资源对象
1 # 为 Deploy 模板添加资源配额 2 [root@master ~]# vim mydeploy.yaml 3 --- 4 kind: Deployment 5 apiVersion: apps/v1 6 metadata: 7 name: myweb 8 spec: 9 replicas: 1 # 修改副本数量 10 selector: 11 matchLabels: 12 app: httpd 13 template: 14 metadata: 15 labels: 16 app: httpd 17 spec: 18 restartPolicy: Always 19 containers: 20 - name: webserver 21 image: myos:httpd 22 imagePullPolicy: Always 23 resources: # 为该资源设置配额 24 requests: # HPA控制器会根据配额使用情况伸缩集群 25 cpu: 200m # CPU配额
2)创建HPA
1 [root@master ~]# vim myhpa.yaml 2 --- 3 kind: HorizontalPodAutoscaler # 资源对象类型 4 apiVersion: autoscaling/v1 # 版本 5 metadata: # 元数据 6 name: myweb # 资源对象名称 7 spec: # 详细定义 8 minReplicas: 1 # 最少保留的副本数量 9 maxReplicas: 5 # 最大创建的副本数量 10 targetCPUUtilizationPercentage: 50 # 警戒值,以百分比计算 11 scaleTargetRef: # 监控的资源对象 12 kind: Deployment # 资源对象类型 13 apiVersion: apps/v1 # 版本 14 name: myweb # 资源对象名称 15 16 [root@master ~]# kubectl apply -f myhpa.yaml 17 horizontalpodautoscaler.autoscaling/myweb created 18 19 # 刚刚创建 unknown 是正常现象,最多等待 60s 就可以正常获取数据 20 [root@master ~]# kubectl get horizontalpodautoscalers.autoscaling 21 NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS 22 myweb Deployment/myweb <unknown>/50% 1 5 0 23 24 [root@master ~]# kubectl get horizontalpodautoscalers.autoscaling 25 NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE 26 myweb Deployment/myweb 0%/50% 1 5 1 59s
3)HPA原理架构
既然是自动根据业务忙闲来调整业务工作负载的副本数,其实HPA的实现思路很容易想到:通过监控业务繁忙情况,在业务忙时,就要对workload扩容副本数;等到业务闲下来时,自然又要把副本数再缩下去。所以实现水平扩缩容的关键就在于:
- 如何识别业务的忙闲程度
- 使用什么样的副本调整策略
kubernetes提供了一种标准metrics接口,HPA controller通过这个统一metrics接口可以查询到任意一个HPA对象关联的deployment业务的繁忙指标metrics数据,不同的业务的繁忙指标均可以自定义,只需要在对应的HPA里定义关联deployment对应的metrics即可。
标准的metrics查询接口有了,还需要实现metrics API的服务端,并提供各种metrics数据,我们知道k8s的所有核心组件之间都是通过apiserver进行通信,所以作为k8s API的扩展,metrics APIserver自然选择了基于API Aggregation聚合层,这样HPA controller的metrics查询请求就自动通过apiserver的聚合层转发到后端真实的metrics API的服务端(对应下图的Promesheus adapter和Metrics server)。
- 最早的metrics只支持CPU和内存的使用指标,这个版本的metrics对应HPA的版本是autoscaling/v1(HPA v1只支持CPU指标)
- 要支持最新的custom(包括external)的metrics,也需要使用新版本的HPA:autoscaling/v2beta1,里面增加四种类型的Metrics:Resource、Pods、Object、External,每种资源对应不同的场景,下面分别说明:
- Resource支持k8s里Pod的所有系统资源(包括cpu、memory等),但是一般只会用cpu,memory因为不太敏感而且跟语言相关:大多数语言都有内存池及内置GC机制导致进程内存监控不准确。
- Pods类型的metrics表示cpu,memory等系统资源之外且是由Pod自身提供的自定义metrics数据,比如用户可以在web服务的pod里提供一个promesheus metrics的自定义接口,里面暴露了本pod的实时QPS监控指标,这种情况下就应该在HPA里直接使用Pods类型的metrics。
- Object类型的metrics表示监控指标不是由Pod本身的服务提供,但是可以通过k8s的其他资源Object提供metrics查询,比如ingress等,一般Object是需要汇聚关联的Deployment下的所有的pods总的指标。
- External类型的metrics也属于自定义指标,与Pods和Object不同的是,其监控指标的来源跟k8s本身无关,metrics的数据完全取自外部的系统。
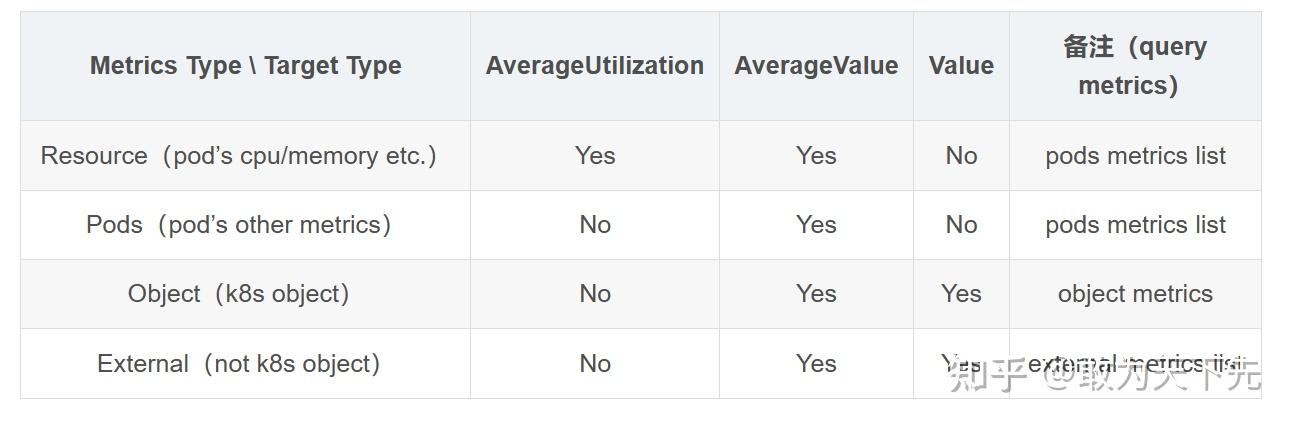
- 在HPA最新的版本 autoscaling/v2beta2 中又对metrics的配置和HPA扩缩容的策略做了完善,特别是对 metrics 数据的目标指标值的类型定义更通用灵活:包括AverageUtilization、AverageValue和Value,但是不是所有的类型的Metrics都支持三种目标值的,具体对应关系如下表。
HPA里的各种类型的Metrics和Metrics Target Type的对应支持关系表
如下是最简单的HPA的定义的例子 (v2beta2)
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50
posted on 2025-09-18 16:50 Karlkiller 阅读(35) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号