MySQL调优
首先得知道哪一步影响了速度。
主要是分析器和优化器部分。
如何判断是哪一步出现了问题?
使用自带的show profile for query n 来查询。这种方式在5.7及以前的版本还是非常ok的,但是以后的版本可能会淘汰,使用performance schema来代替。
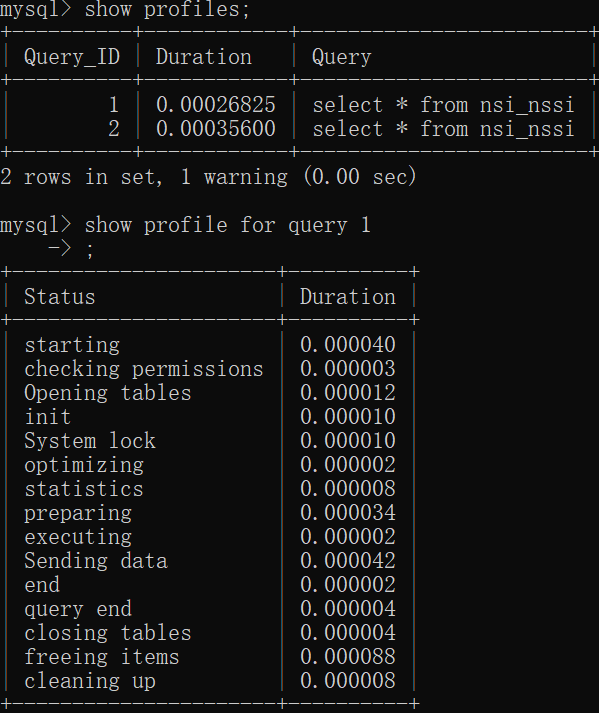
performance schema是啥?
一个监控数据库的工具,开启会消耗一定性能,但是可以对性能监控功能很友好。该数据库里面的表不会持久化。
要优化,必须要看执行计划。
访问索引也是有io的,所以尽量不要多次访问索引。
索引是什么?
为了快速查找数据,对数据库的一列或多列数据进行排序的数据结构。
索引为什么快?
首先明确mysql的数据是数据页的方式存储的,页与页之间是由双向链表连接的,页内的具体数据是由单向链表连接的,如果不使用索引,也就是使用一个普通列来查询的话,需要遍历页(每次读取页都是一次IO,要加载到内存中),然后页内也需要循环遍历,速度非常慢。
如果使用了索引的话,索引是一个B+树的形式的数据结构,可以使用2分法大大减少扫描的数据量。而且,由于索引的存在,数据都是顺序的,这就使得IO变成了顺序IO,大大提升了效率。
注意:
1、innoDB是通过B+Tree结构对主键创建索引,如果没有主键,则会选择唯一键,最后选择rowid。如果创建索引的时候用的是非主键的普通字段,在索引的叶子节点存储的数据就是主键,然后需要根据主键的索引来获得其他数据,这个过程叫做回表。
2、MyISAM引擎索引的叶子节点存储的是数据的实际地址,需要读取两个文件。
总结一下,索引的优点:
1、减少服务器扫描数据的量;
2、避免了排序问题和临时表
3、将随机IO变成了顺序IO
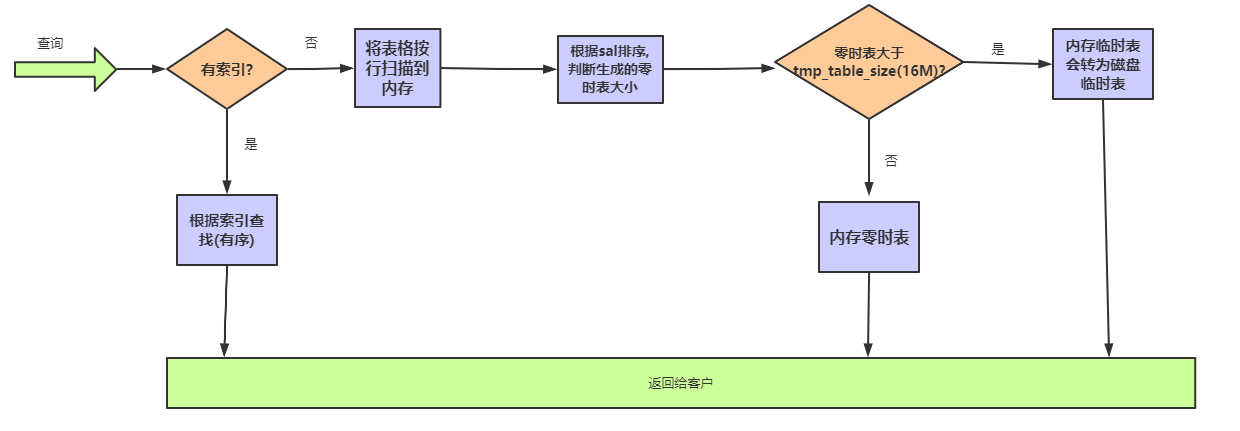
关于临时表的问题见下表:
参考 https://www.cnblogs.com/Courage129/p/14194248.html
索引的分类:
1、主键索引,默认 (PRIMARY KEY)
2、唯一索引,不能重复,可以有空值(UNIQUE)
3、普通索引,没有限制(INDEX)
4、全文索引,如需使用还是推荐直接上ES(FULL INDEX)
5、组合索引,多列的索引
技术名词解释:
1、回表:使用了普通索引,在普通索引的叶子节点找到主键id,然后根据主键id回查主键id的索引树,得到具体的数据。
2、覆盖索引:在索引的叶子节点可以拿到所有的数据,这种情况是最理想的情况。
3、最左匹配:如果有组合索引,会先匹配最左列的值,如果组合索引中最左侧的索引列不在查询条件中,则索引失效。举个例子
一个表A 包含 id,name,age,gender四个列,id为主键,name,age为组合索引:
select * from tableA where name = ‘aaa’ and age = 10;
select * from tableA wher age = 10;
select * from tableA where name = ‘aaa’ ;
select * from tableA where age = 10 and name = ‘aaa’;
以上四个sql,第二句没有使用索引,因为组合索引最左侧的列是name,没有在查询条件里,第四句虽然顺序不对,但是优化器会调整顺序,得到一样的效果。
4、全值匹配:使用索引的所有列进行匹配
5、聚簇索引和非聚簇索引:其实聚簇还是不聚簇其实就看数据和索引是不是分开存储的,InnoDB是在一起存储的,所以属于聚簇索引,但是有一种情况他也可以算作非聚簇索引:普通索引的叶子节点存储的是主键ID,数据和索引的叶子节点也没有存在一起,这种情况也可以算非聚簇索引。
聚簇索引的优点:
1、数据访问更快速;
2、使用覆盖索引查询的时候可以直接使用主键查询;
聚簇索引的缺点:
1、更新的代价很高,会导致数据行移动,或者页分裂,页分裂的过程数据行会加锁,阻塞数据更新,所以在频繁更新的列不应该使用索引。
2、聚簇索引最大的优势是最大限度提升了IO密集型的查询性能,但是如果数据行基本都在内存里,就失去了优势,还不如直接使用redis。
优化细节:
1、尽量不要在使用索引列查询的时候使用表达式,逻辑放到业务层去处理,因为使用了表达式之后,索引会失效。
2、尽量使用主键索引,不会有回表的过程
3、当创建索引的列为字符串类型,推荐使用前缀索引来创建索引,缺点是无法使用group by 和 order by ,具体就比如:ALTER TABLE `city_demo` ADD INDEX `idx_city` (`city`(7))
4、使用索引扫描来排序
5、union、all、in、or都能使用索引,但是推荐用in
6、使用范围匹配的时候,多个索引列的范围匹配,只有最左侧的会生效
如 select * from abc where a>10 and b>20 and c=10,只有第一个索引列 a会走索引,b、c不走索引,如果都是精确匹配的话没问题,即select * from abc where a=10 and b=20 and c=10。
7、使用类型转换会导致索引失效,比如查询条件是varchar类型,但是按照数字匹配的,就会发生全表扫描。
8、更新频繁的数据不适合设置索引。索引的更新会导致b+树变更,区分度不大的如性别不推荐做索引。
9、索引列不允许为null;
10、进行表连接的时候不要超过3张表。
11、尽量使用limit,少返回数据就减少io。
12、索引也不是越多越好,5个以下,太多了就反作用了。
13、在了解系统以后在做优化,比如压测一下。
查询慢的原因:
1、网络IO
2、磁盘IO
3、锁等待时间
InnoDB支持行锁和表锁,MyISAM只支持表锁,InnoDB的行锁锁的是索引,如果没有索引可以加锁则会退化成表锁
查询慢的优化方案:
1、优化数据访问:
考虑过滤条件是否可以更精确。
开发过程中会有先查询大量结果然后取前N行的情况,实际上mysql把所有的返回结果都先返回再做的计算,这就造成每次都查询很多没有用的数据,优化方案是使用limit
不要是用select * ,用哪行取哪行。
经常查询重复数据要做缓存。
2、优化关联查询
使用on或者using的时候列要有索引
3、优化子查询
子查询最好使用join等关联查询代替,因为select会得到一个结果放到临时表里,查询临时表又会涉及IO
4、union
union也涉及临时表,尽量避免
优化相关问题:
Q:为什么不要使用select *?
A:1、增加查询分析器解析成本。2、增减字段容易与 resultMap 配置不一致。3、无用字段增加网络 消耗,尤其是 text 类型的字段
具体:
1. 不需要的列会增加数据传输时间和网络开销
用“SELECT * ”数据库需要解析更多的对象、字段、权限、属性等相关内容,在 SQL 语句复杂,硬解析较多的情况下,会对数据库造成沉重的负担。
增大网络开销;* 有时会误带上如log、IconMD5之类的无用且大文本字段,数据传输size会几何增涨。如果DB和应用程序不在同一台机器,这种开销非常明显
即使 mysql 服务器和客户端是在同一台机器上,使用的协议还是 tcp,通信也是需要额外的时间。
2. 对于无用的大字段,如 varchar、blob、text,会增加 io 操作
准确来说,长度超过 728 字节的时候,会先把超出的数据序列化到另外一个地方,因此读取这条记录会增加一次 io 操作。(MySQL InnoDB)
3. 失去MySQL优化器“覆盖索引”策略优化的可能性
SELECT * 杜绝了覆盖索引的可能性,而基于MySQL优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式。
Q:主键的选择?
A:推荐使用代理主键,也就是和业务无关的数字序列。优点:不与业务耦合,通用的键策略可以减少代码的开发。
Q:适当拆分数据。
A:如果一张表字段很多,但是有很多字段查询的时候根本用不到,而表数据量又很大,那么应该把不经常查询的字段剥离,采用关联的方式分表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号