
爬虫-BeautifulSoup4
之前我们是用lxml来提取数据,今天我们来学习一下bs4
在学习之前呢我们需要先来安装一下包
pip install bs4
我们用到的例子还是上节课的text内容
text = \ """ <ul class="ullist" padding="1" spacing="1"> <li> <div id="top"> <span class="position" width="350">职位名称</span> <span>职位类别</span> <span>人数</span> <span>地点</span> <span>发布时间</span> </div> <div id="even"> <span class="l square"> <a target="_blank" href="position_detail.php?id=33824&keywords=python&tid=87&lid=2218">python开发工程师</a> </span> <span>技术类</span> <span>2</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="odd"> <span class="l square"> <a target="_blank" href="position_detail.php?id=29938&keywords=python&tid=87&lid=2218">python后端</a> </span> <span>技术类</span> <span>2</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="even"> <span class="l square"> <a target="_blank" href="position_detail.php?id=31236&keywords=python&tid=87&lid=2218">高级Python开发工程师</a> </span> <span>技术类</span> <span>2</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="odd"> <span class="l square"> <a target="_blank" href="position_detail.php?id=31235&keywords=python&tid=87&lid=2218">python架构师</a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="even"> <span class="l square"> <a target="_blank" href="position_detail.php?id=34531&keywords=python&tid=87&lid=2218">Python数据开发工程师</a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="odd"> <span class="l square"> <a target="_blank" href="position_detail.php?id=34532&keywords=python&tid=87&lid=2218">高级图像算法研发工程师</a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="even"> <span class="l square"> <a target="_blank" href="position_detail.php?id=31648&keywords=python&tid=87&lid=2218">高级AI开发工程师</a> </span> <span>技术类</span> <span>4</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="odd"> <span class="l square"> <a target="_blank" href="position_detail.php?id=32218&keywords=python&tid=87&lid=2218">后台开发工程师</a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="even"> <span class="l square"> <a target="_blank" href="position_detail.php?id=32217&keywords=python&tid=87&lid=2218">Python开发(自动化运维方向)</a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="odd"> <span class="l square"> <a target="_blank" href="position_detail.php?id=34511&keywords=python&tid=87&lid=2218">Python数据挖掘讲师 </a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> </li> </ul> """
这段代码可以直接复制到编译器里,我这里用的是Spyder
首先需要导入模块,将这段文本解析为HTML形式,今天用的是bs4,我们可以和上节课的对比着来学习,加深印象
#导入模块 from bs4 import BeautifulSoup #实例化BeautifulSoup对象 soup = BeautifulSoup(text,'lxml')
接下来我们就要开始提取数据了
#获取所有的div标签 divs = soup.find_all('div') print(divs) #bs4提取的结果不是列表,而是通过print解析出了一个列表的结果 #输出的结果是一个列表,每个div是列表中的一个元素 print(type(divs)) for div in divs: print(div) print('*'*60)
这里的type是bs4里的元素

#获取指定的div标签 #第二个div div = soup.find_all('div')[1] print(div) #把结果保存,转换为列表。需要强制转换 div = list(soup.find_all('div')) #print(div) print(type(div))#此时会发现type变成了list div = list(soup.find_all('div'))[1] print(div) print(type(div))#type还是bs4里的元素因为[1]把列表里的取出来了 #第二个到第十个div [1:10]表示[1,2,3...10)左闭右开 divs = soup.find_all('div')[1:10] for div in divs: print(div) print('*'*60)
接下来介绍两种不同的方法获取拥有指定属性的标签
#获取拥有指定属性的标签(id="even") #方法一 divs = soup.find_all('div',id="even") #(标签,属性) #divs_1 = soup.find_all('span',class="l square") for div in divs: print(div) print('*'*60) #方法二 divs = soup.find_all('div',attrs={'id':'even'})#字典 for div in divs: print(div) print('*'*60)
为什么我将divs_1注释掉,因为这个有语法错误,通过接下来的讲解寻找答案吧
#获取多个指定属性的标签 #span = soup.find_all('span',class='position',width='350') #print(span) #这样的写法会报错,因为class无法辨认是python的关键字还是属性,所以需要在class后面加_才能识别为属性 span = soup.find_all('span',class_='position',width='350') print(span) span = soup.find_all('span',attrs={'class':'position','width':'350'}) print(span)
所以上面的应该写成
divs_1 = soup.find_all('span',class_="l square")
接下来介绍两种方法来获取标签的属性值
alist = soup.find_all('a') #方法一:通过下标方式提取 for a in alist: href = a['href'] print(href) #方法二:利用attrs参数提取 for a in alist: href = a.attrs['href'] print(href)
最后我们有一个综合的任务:获取所有的职位信息
#获取所有的职位信息 divs = soup.find_all('div')[1:] #print(divs) works=[] for div in divs: #获取职位信息 a = div.find_all('a')[0] position = a.string #print(position) #职位信息 category = div.find_all('span')[1].string #print(position,category) #获取人数 nums = div.find_all('span')[2].string #获取地区 area = div.find_all('span')[3].string #获取时间 time = div.find_all('span')[4].string #print(position,category,nums,area,time) positions={ 'position':position, 'category':category, 'nums':nums, 'area':area, 'time':time } works.append(positions) print(works)
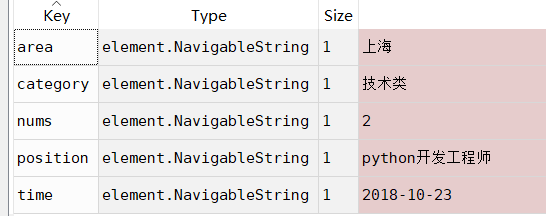
最后works里存放的数据我们可以看一下:

点开一个value我们会看到
你学会了嘛~
欢迎下方留言交流

 浙公网安备 33010602011771号
浙公网安备 33010602011771号