


7月19日day11总结
今天学习过程和小结
上午进行测试复习了
1,hdfs中namenode和datanode作用
2,hdfs副本存放机制
3,mapreduce计算处理过程
4,格式化hdfs命令
5,hdfs的核心配置文件内容配置
sql语句:
部门表:
6,统计各个部门的人数
7,查询所有部门。
8,倒排索引代码
9,hash函数的特点,有哪些实现方式
10,查看namenode是否正常运行
重点学习了倒排索引的代码。
然后进行了hive的安装和配置,以及sqoop的安装和配置。
Hive构建在Hadoop之上的数据仓库 Hive中定义了一种类SQL查询语言:HQL(类似SQL但不完全 相同) 通常用于离线数据处理(采用mapreduce) 底层支持多种不同的执行引擎(mapreduce、tez、spark) 支持多种不同的压缩格式(GZIP、LZO、Snappy、 Bizp2)、存储格式(TextFile、SequenceFile、RCFILE、ORC、 Parquet)以及自定义函数(UDF)
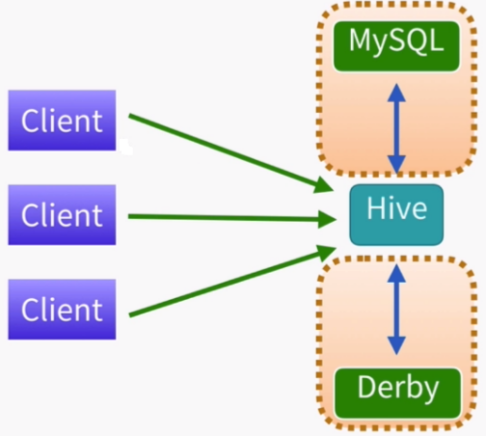
在hive中主要是进行SQL数据库表的建立以及SQL语句的学习。包括hive查询的联系和表连接的查询。以及sqoop的联系
1使用sqoop导入mysql数据到hdfs
2,使用sqoop导入mysql数据到hive
3,使用sqoop导入mysql数据到hive中,并指定表名
4,使用sqoop导入mysql数据到hive中,并使用where条件
5,使用sqoop导入mysql数据到hive中,并使用查询语句
6,使用sqoop将hive中的数据导出到mysql中
遇到问题汇总
- 今天主要学习了hive和SQL语句的操作,有很多SQL查询语句不是很了解要多多练习。
2.sqoop导入导出的步骤也要加强。
学习技能思维导图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号