网络爬虫:1、什么是网络爬虫,requests模块介绍及常用方法,response响应对象常用方法及编码问题,爬取视频和图片
目录
网络爬虫
一、网络爬虫
什么是网络爬虫:
指程序在或联网上(各个网站),爬取数据(必须要在能够浏览的页面上才能爬取),然后通过清洗数据将需要的数据存入库中

爬虫的本质:
- 1、模拟http请求,向客户端发送请求,获取数据
- 2、网站内抓包
# 补充:百度其实就是一个大爬虫
-百度爬虫一刻不停的在互联网中爬取各个页面---》爬取完后---》保存到自己的数据库中
-你在百度搜索框中搜索---》百度自己的数据库查询关键字---》返回回来
-点击某个页面----》跳转到真正的地址上
-seo:
-sem:充钱的
学习方向:
- 模拟http发送请求
- requests、selenium模块
- 解析数据:
- bs4
- 入库:
- mysql、redis、文件
- 爬虫框架:
- scrapy
二、requests模块
什么是requests模块:
使用requests可以模拟浏览器的请求(http),比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3)
安装requests模块:
pip install requests
1、requests发送GET请求
# 导入模块
import requests
# 向指定的url发送get请求
res = requests.get('https://www.baidu.com')
# 获取请求结果(返回一个response对象)
print(res) # <Response [200]>
2、requests携带参数
携带参数的方式有两种
- 直接写在url路径上
- 写在params参数内
# 方式一:直接写在url路径上
requests.get('https://www.baidu.com/name=xx&age=18')
# 方式二:写在params参数内
requests.get('https://www.baidu.com/',
params = {'name':'xxx',
'age':18})
3、url编码、解码
在浏览网站时,经常会看到url地址中出现很多没有规律的字母,其实这些字母都是被编码后的汉字
# 如果是中文,在地址栏中会做url的编码:
https://www.baidu.com/?name=%E5%B8%85%E5%93%A5
帅哥:%E5%B8%85%E5%93%A5

- urllib模块
- 可以对url进行编码解码
# 导入模块
from urllib.parse import quote, unquote
# 编码
res = quote('帅哥')
print(res) # %E5%B8%85%E5%93%A5
# 解码
res1 = unquote('%E5%B8%85%E5%93%A5')
print(res1) # 帅哥
4、携带请求头
很多网站做了反扒措施,直接发送请求会被服务端拦截,原因是客户端会检查响应头中数据,对不是浏览器的响应做出拦截
import requests
res = requests.get('https://dig.chouti.com/')
print(res.text)
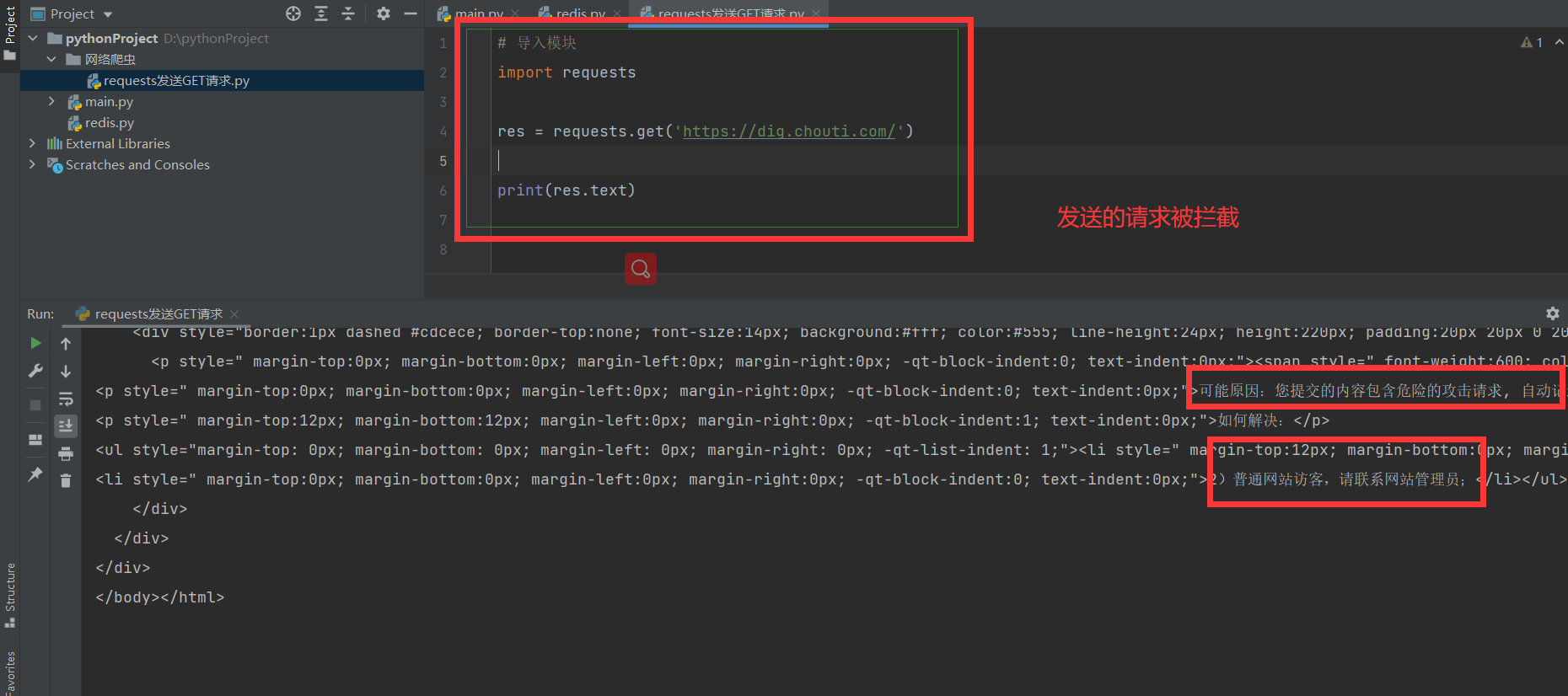
解决方法:
通过携带请求头伪装成浏览器,http请求中,请求头中有一个很重要的参数 User-Agent,该参数表明了客户端的类型是什么,如果没有这个请求头,就会被后端拦截

import requests
# http请求头:User-Agent,cookie,Connection
# http协议版本间的区别
# Connection: keep-alive
# http协议有版本:主流1.1 0.9 2.x
# http 基于TCP 如果建立一个http链接---》底层创建一个tcp链接
# 1.1比之前多了keep-alive
# 2.x比1.x多了 多路复用
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
res = requests.get('https://dig.chouti.com/',headers=headers)
print(res.text)
5、发送Post请求,携带数据
# 导入模块
import requests
# 请求头参数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# 携带的参数
data = {'postId': 17218867,
'voteType': "Digg",
'isAbandoned': 'false'}
# 向指定的url发送响应,携带请求头和数据
res = requests.post('https://www.cnblogs.com/', params=params, data=data)
print(res.text)
6、自动登录,携带cookie的两种方式
# 登录功能,一般都是post
import requests
data = {
'username': '',
'password': '',
'captcha': '3456',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
res = requests.post('http://www.aa7a.cn/user.php',data=data)
print(res.text)
# 响应中会有登录成功的的cookie,
print(res.cookies) # RequestsCookieJar 跟字典一样
# 拿着这个cookie,发请求,就是登录状态
# 访问首页,get请求,携带cookie,首页返回的数据一定会有 我的账号
# 携带cookie的两种方式 方式一是字符串,方式二是字典或CookieJar对象
# 方式二:放到cookie参数中
res1=requests.get('http://www.aa7a.cn/',cookies=res.cookies)
print('616564099@qq.com' in res1.text)
7、requests.session的使用
# 为了保持cookie ,以后不需要携带cookie
import requests
data = {
'username': '',
'password': '',
'captcha': '3456',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
session = requests.session()
res = session.post('http://www.aa7a.cn/user.php', data=data)
print(res.text)
res1 = session.get('http://www.aa7a.cn/') # 自动保持登录状态,自动携带cookie
print('616564099@qq.com' in res1.text)
8、Post请求携带数据编码格式
import requests
# data对应字典,这样写,编码方式是urlencoded
requests.post(url='xxxxxxxx',data={'xxx':'yyy'})
# json对应字典,这样写,编码方式是json格式
requests.post(url='xxxxxxxx',json={'xxx':'yyy'})
# 终极方案,编码就是json格式
requests.post(url='',
data={'':1,},
# 在响应头指定编码格式
headers={
'content-type':'application/json'
})
三、响应response对象
1、常用方法
# Response相应对象的属性和方法
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
respone=requests.get('http://www.jianshu.com',headers=headers)
# respone属性
print(respone.text) # 响应体转成了字符串
print(respone.content) # 响应体的二进制内容
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # cookie是在响应头,cookie很重要,它单独做成了一个属性
print(respone.cookies.get_dict()) # cookieJar对象---》转成字段
print(respone.cookies.items()) # cookie的键值对
print(respone.url) # 请求地址
print(respone.history) # 不用关注
print(respone.encoding) # 响应编码格式
2、编码问题
# 有的网站,打印
res.text --->发现乱码---》请求回来的二进制---》转成了字符串---》默认用utf8转---》
response.encoding='gbk'
再打印res.text它就用gbk转码
四、爬取图片/视频
1、爬取图片
import requests
# 指定图片地址
res=requests.get('http://pic.imeitou.com/uploads/allimg/230224/7-230224151210-50.jpg')
print(res.content)
# 保存图片
with open('美女.jpg','wb') as f:
f.write(res.content)
2、爬取视频
import requests
# 指定图片地址
res=requests.get('https://vd3.bdstatic.com/mda-pcdcan8afhy74yuq/sc/cae_h264/1678783682675497768/mda-pcdcan8afhy74yuq.mp4')
# 保存图片
with open('致命诱惑.mp4','wb') as f:
# 视频
for line in res.iter_content():
f.write(line)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号